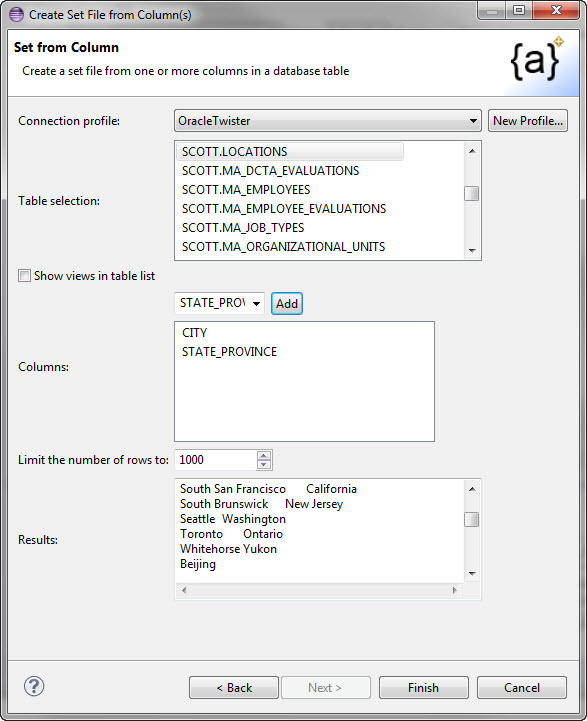
Pairs Testing in RowGen v3 – Valid/Joined Pairs and…
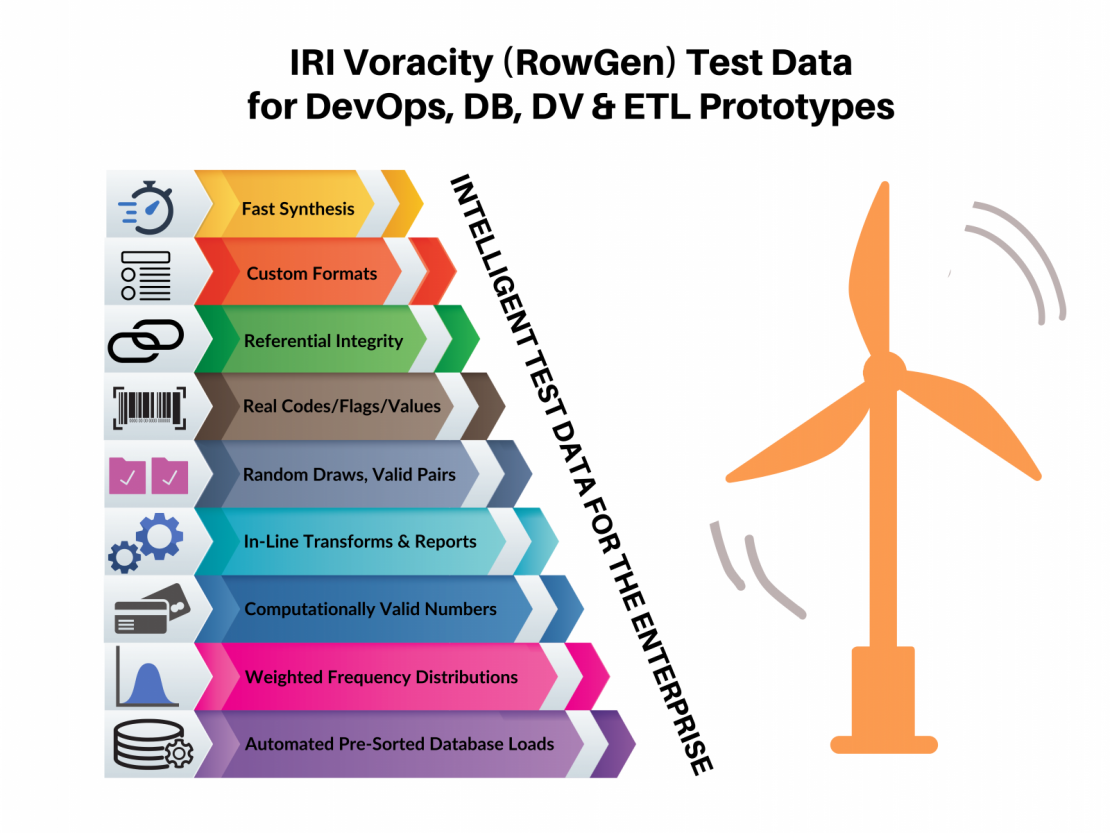
Database and solution architects depend on realistic test data to:
help create new databases, prototype ETL jobs or applications benchmark performance in new or existing platforms stress-test systems protect confidential information in existing systems if database work is outsourced or used for demonstrations. Read More






{kind=link}
{kind=link}
{kind=link}