
Masking NoSQL DB PII in the DarkShield GUI
This is the second article in a series of articles on using IRI DarkShield to search and mask sensitive data in NoSQL databases.
Introduction
The IRI DarkShield data masking product now includes fit-for-purpose wizards in the IRI Workbench IDE to search (classify) and mask (remediate) PII or other sensitive ”dark data” (as defined by Gartner) in structured, semi-structured, and unstructured file, NoSQL, and relational database sources.
This article covers the use of Workbench for finding and masking data in Cassandra, Elasticsearch, and MongoDB. DarkShield V6 also front-ends CosmosDB, Redis and Splunk. The DarkShield API can support additional NoSQL databases as long as custom calling programs are provided, as shown in this repository.
The diagram below summarizes DarkShield’s architecture as part of the overarching Voracity data management platform. The wizard this article explains is inside Workbench:
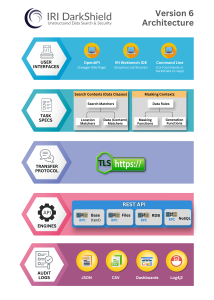
Although not discussed in this article, DarkShield also includes wizards for other sources, like: the New File Search/Masking Job … wizard for sensitive data in files, and the New Relational DB Search/Masking Job … wizard for sensitive data that is either semi-structured or unstructured in RDB columns.
What the DarkShield NoSQL DB Wizard Does
The “New NoSQL DB Search/Masking Job …” wizard in the IRI Workbench GUI for DarkShield helps you create a DarkShield Job to find and mask PII or other sensitive information in MongoDB, Cassandra and Elasticsearch. The job serializes into an XML “.dsc” file containing the Search and Mask Contexts applicable to your jobs.
Search Contexts contain instructions on how to access the NoSQL source silo and scan it for PII. Mask Contexts contain instructions for de-identifying the PII found during the search operations, and how to access the NoSQL target silo where the masked version of data will be sent.
The scanning and remediation of data stored in NoSQL silos is based on your defined Data Classes, which are stored in an IRI Data Class and Rule Library. Each Data Class contains one or more search methods called Search Matchers used to identify PII.
Previous iterations of the wizard only supported scanning and extracting sensitive values that matched Java RegEx patterns and Set File lookups. Today’s wizard supports more search methods, and of course simultaneous or separate masking operations.
For more information on the various search methods available, read about Data Matchers and Location Matchers.
Prerequisites
Before running the DarkShield NoSQL wizard, these preliminary steps must be completed:
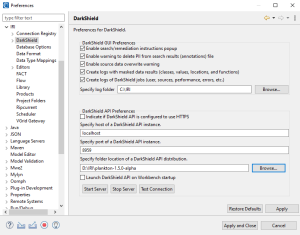
First, verify that the DarkShield API distribution directory has been specified in IRI Preferences. To do so go to IRI Workbench Preferences > IRI > DarkShield. From here, you can configure both DarkShield GUI and API preferences including the host, port, and directory where the DarkShield API resides.
Second, all DarkShield wizards require a project possessing an IRI Data Class and Rule Library. The IRI Library in turn should contain at least one Data Class and a masking Rule assigned to that Data Class. To learn about the IRI Data Class and Rule Library and how to create Data Classes and Rules, read this article.
IRI Project containing IRI Library
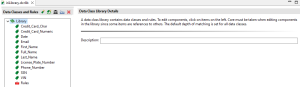
IRI Data Class and Rules Library Form Editor contains some Data Classes and Rules
Third, verify that the Plankton (DarkShield API) server is running. This can be done by opening the DarkShield API Status view in IRI Workbench. This view displays information about the DarkShield API, including whether it is currently running.
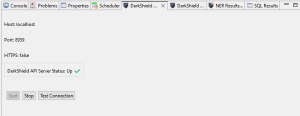
DarkShield API Status view panel
Finally, ensure that the data silos you will be reading from and writing to can be accessed by the DarkShield application (DarkShield API). Each NoSQL database type (Cassandra, Elasticsearch, MongoDB, etc…) uses a different SDK to connect and make CRUD operations with that particular NoSQL database type. As such, different database types may require different credentials and specifications for accessing and manipulating data in NoSQL silos.
For my demonstration in this article, I have a MongoDB database called “Darkshield” with a collection called “data”.
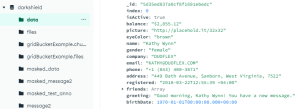
View of data collection from MongoDB Compass
Using the Wizard
In this article, I will demonstrate the use of the New NoSQL DB Search/Masking Job… wizard to create a DarkShield NoSQL Job.
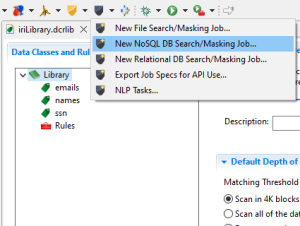
Launch the wizard from the DarkShield menu by selecting New NoSQL DB Search/Masking Job…. This opens the first page where you name a new job:
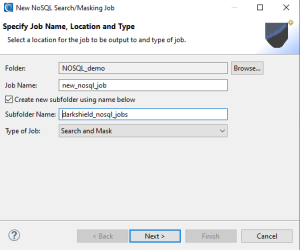
Specify the folder and file name for the output of the wizard (your .dsc job configuration file).
Click Next when finished to move on to the specifics of the data you are trying to find — and how it should be masked.
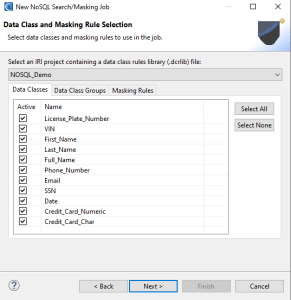
Here is where you specify the IRI Data Class and Rule Library which contains your Data Classes, Data Class Groups, and (masking) Rules. It is possible to filter the Data Classes and Groups from the library we intend to use by selecting or deselecting Data Classes in the Active column. In this example, I am using the default Data Classes provided when creating an IRI Project.
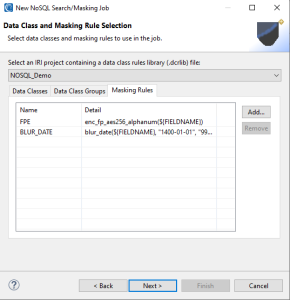
In the Masking Rules tab, we can see that two functions are available: a Format Preserving Encryption Rule and a Blur Date Rule. These rules dictate how PII found using Data Classes will be masked. It is also possible to add or remove Masking Rules from this tab.
Click Next when finished to move onto the page that will allow you to assign these Masking Rules to specific Data Classes.
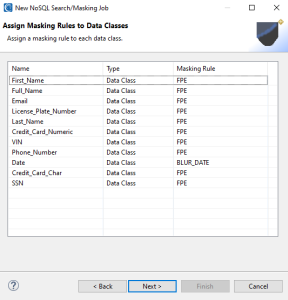
On the Assign Masking Rules to Data Classes wizard page, each Data Class and Data Class Group must be assigned a Masking Rule to indicate how PII will be masked. If you do not wish to mask a particular PII data type, click Back and deselect the applicable Active checkbox in the Data Class or Data Class Group tab. Then return to this page and finish assigning rules to your data classes.
Once finished, click Next to begin specifying the NoSQL silo that will be searched and masked.
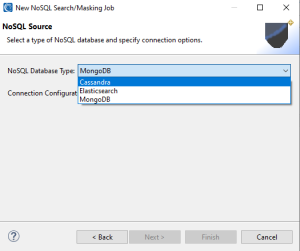
From this page, you are prompted to specify the NoSQL database type and a connection registry for the data source.
Currently, the IRI Workbench GUI IRI DarkShield supports the following NoSQL database types:
- Cassandra
- Elasticsearch
- MongoDB
A Connection Registry is a reusable connection configuration for connecting a data silo. Select the desired NoSQL database type to create a new Connection Registry, then click New.
Depending on the database type parameters for connections will vary:
Cassandra:
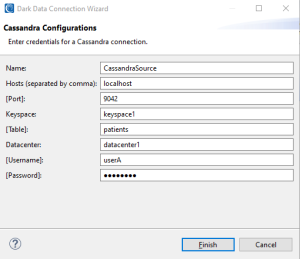
Elasticsearch:
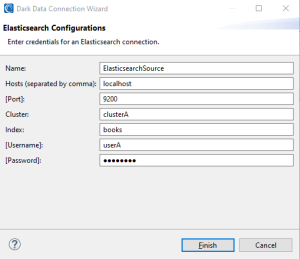
MongoDB:
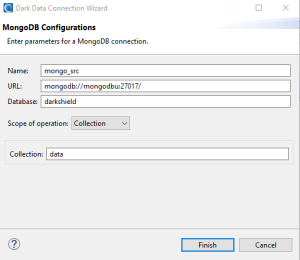
Once you populate the required fields, click Finish to create a new connection registry and return to the previous page.
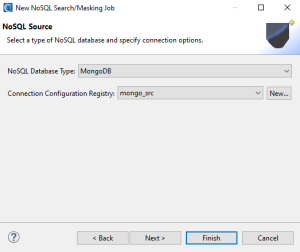
You now have your desired connection registry configured for the source database. Click Next to move onto the NoSQL Target page.
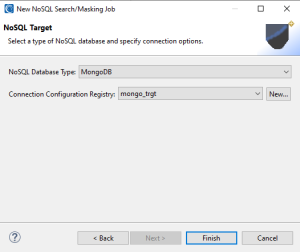
The target page is where you specify where the masked data will written. Like the Data Source page, a connection registry is used to specify the NoSQL data silo and provide the necessary credentials.
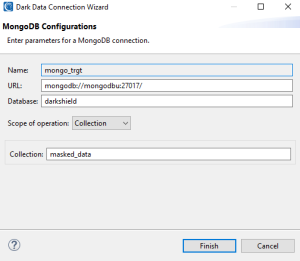
The steps to create a connection registry are the same for a data target. Once a connection registry has been provided for the target silo, click Finish to produce the .dsc file that will be used by the DarkShield API at runtime.
DarkShield Job Editor
Your .dsc file can be viewed and modified from the (.dsc) form editor in Workbench, referred to as the DarkShield Job editor. This editor allows you to redefine the parameters of a job that were initially set, upon completion of a DarkShield Job wizard. Below we have an open editor:
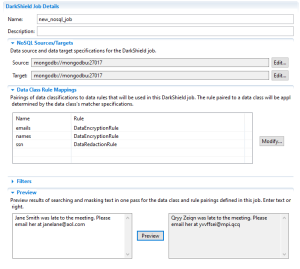
You can add, edit, or remove a source and/or target from your .dsc file as desired by clicking the Edit… button alongside the source or target.
From the editor, you can also modify your Data Class Rule Mappings by clicking the Modify button. It is also possible to choose a different IRI Library and/or rearrange the Masking Rules assigned to your Data Classes.
Finally, the editor also provides a preview option that allows you to test your Data Class search matchers and Masking Rules using text input. By clicking Preview, you can see what PII was found and how it was transformed using the current Data Classes and Masking Rules.
Running Your Search and Masking Job
You can use your DarkShield job configuration in three different ways; i.e., in a:
- Search Job to simply identify PII and log the results to file;
- Masking Job that will use the search log to mask the discovered PII; or,
- Search and Masking Job to search and mask PII in one job.
In this demonstration, we will be running a DarkShield Search and Mask Job. To run a DarkShield Search and Mask Job right, click the .dsc file and select IRI > Run Search and Masking Job.
After running a Search and Masking Job, the PII data found will be masked and placed in the target silo you previously specified. Following is an example of the data I started and ended with:
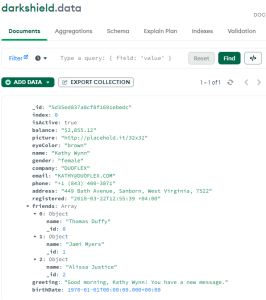
MongoDB collection unprotected
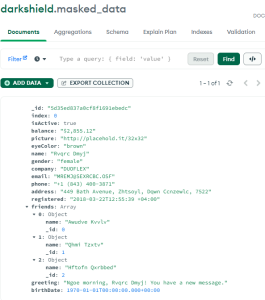
MongoDB collection protected
If you would like help using this wizard to scan and/or mask data in your NoSQL database – or with any other data source(s) – please contact your IRI representative or email darkshield@iri.com.










