
Masking PII in PDF & Image Files
IRI DarkShield can search for, and mask, personally identifiable information (PII) and other sensitive data in many different file types, documents and databases on-premise or in the cloud. Among the file types supported are those in PDF and image formats, which are the focus of this article. Note that DarkShield can now also find and redact signatures in these sources as well.
As with other document types, DarkShield supports sensitive data discovery and protection in PDFs and images using masking functions specified as rules during data classification in IRI Workbench. These data masking functions include, but are not limited to, hashing, encryption, pseudonymisation, and black-box redaction.
This article provides standalone examples of PDF masking and image masking via DarkShield Jobs, created through wizards in the IRI Workbench GUI for DarkShield. For a more general discussion of using the GUI for all kinds of files, see this article.
Challenges with PDFs and Images
Searching and masking can at times present file-type-specific challenges. This is the result of files varying in their format, how data is stored in files, and the necessary techniques used to access and manipulate data in these files. Broadly speaking, PDF and image files can represent an outsized challenge for both search and masking operations.
Search Challenges
Technical limitations around PDF and image files can hamper the ability of software to find and extract PII from them. More specifically, both the quality and format of the files can determine whether complications will arise during the search process.
PII in images is translated to text using OCR (optical character recognition). The OCR model IRI ships with DarkShield can be used as is or fine-tuned (trained) to perform at a higher level of accuracy.
Low-quality images present a significant challenge. Specifically, images with low resolution, images containing multi-colored backgrounds, and text that cannot be easily read (e.g., in a very unique font or handwritten characters) may cause the OCR engine to stumble.
Searching for PII in PDFs also has its own set of challenges. You may need to extract the PII either from within form fields (fairly straightforward), or from free-form text based on X,Y coordinate specifications. Unfortunately, there are several challenges with the latter.
The first problem is that because characters are X,Y coordinate positioned, the use of spaces and tabs is not guaranteed. Moreover, null values can be in different locations to represent that there are “spaces” in a line and/or line breaks to indicate the end of a line or sentence.
Either way, this can result in sentences that are broken up incorrectly because of these faulty characters. That can disrupt content interpretation and thus the accuracy of Named Entity Recognition in searches.
Another problem with PDF character reading is the possibility of slight differences in Y elevation of characters on the same line. This commonly occurs when there are subscripts and superscripts. This is a serious problem when extracting text that is above an underline.
Consider this PDF from which text must be extracted for identification and masking to occur:

Below is the PDF processor’s extracted text that has difficulty reading words hovering above lines.
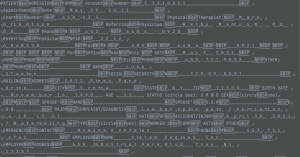
Yet another problem is that PDFs can have images embedded within. That loops back to the problems with images.
Recommendations
Some of the issues mentioned above can be alleviated by providing images with decent resolution quality and monochrome backgrounds (as much as possible). IRI also recommends modifying your DarkShield File Configurations as needed for a more tailored processing of these file types.
File configurations for images that may help include:
- Pass in bounding boxes to target hard-to-recognize text like signatures
- Pass in parameters for the OCR engine
- Provide a different OCR engine more fine-tuned for the task at hand.
Masking Challenges
The challenges of masking PDFs and images mainly arise from how those files are formatted. First is the issue of replacing text based on X,Y coordinates. Unlike most file types, PDFs and images do not make accommodations (shift characters to the right) for new text entered on a line unless it is done manually by an editor, like Adobe Acrobat.
For example, consider this ‘before’ clip of text in a PDF:
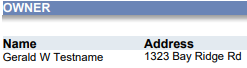
Note that same clip ‘after’ a hash function was used to replace the name “Gerald” with hash value:
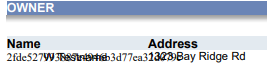
This demonstrates how replacement values exceeding the length of original PII values can create a text overlap issue. A total word’s length is determined by the number of characters, font type, and individual differences in character width. It can thus be a challenge to find a suitable replacement value even if it has the same number of characters.
In image files, this issue can manifest differently. Consider this ‘before’ clip of text in a JPG file:

In this ‘after’ clip, AES256 encryption was applied to the name to produce ciphertext value:

The image process attempts to “fit” generated text into the X,Y coordinates by shrinking the text. As you can see from the example above, at some point the text can become too small to read.

Images have an additional challenge when substituting text in images as a new background behind the text must also be drawn. This can lead to differences in color gradients between the background of the original image versus the one in the snippet generated with the replacement value.
Recommendations
Because of the complexity and challenges of masking PII in PDFs and images, there is no one-size-fits-all solution. That said, some general guidelines should be followed:
Use the appropriate masking rules when working with PDFs and images. When trying to resolve word overlap issues, use masking functions that will not return new values longer than the length of the original text.
Certain masking functions like format-preserving encryption, length-preserving pseudonymization, and character redaction will produce words that are equal in character count. This can keep overlap to a minimum or prevent it altogether.
By way of alternatives, character removal in PDFs and the default black-box redaction function for images work fine in terms of space. There are also PDF and image file masking settings in DarkShield that you can configure, e.g.,
- the font type of replacement text
- whether to copy and reuse original background color when inserting replacement text
- Whether to have PDF text replacement attempt to perform character shifting to prevent overlap (which does not always produce desired results).
Masking PII with the DarkShield Wizard
Below I demonstrate the use of the New File Search/Masking Job… wizard in the IRI Workbench GUI for DarkShield to build a DarkShield job to search and mask PII in PDF and image files.
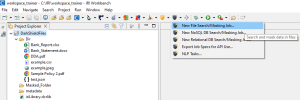
To open the wizard, select the DarkShield menu dropdown from the top toolbar’s charcoal shield icon and select the New Files Search/Masking Job… wizard. This brings up the first page where you can name your new job:
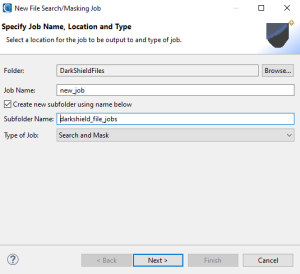
Here you will also specify the folder and file name for the DarkShield .dsc job file and location where the job file is placed after wizard is completed. The subfolder will also indicate where the metadata file will be placed in an IRI project after a DarkShield Search Job has been run.
Click Next to move into the Search Report Options page.
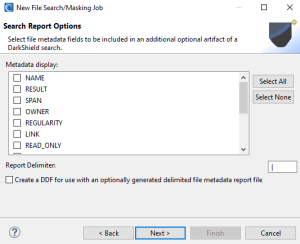
This page lets you customize a flat-file search log by selecting metadata attributes of the files in which PII was discovered.
Click Next when finished to move to the Data Class and Masking Rule Selection page where you can select your data classes, which determine the PII you are trying to find, and how the PII found, should be masked.
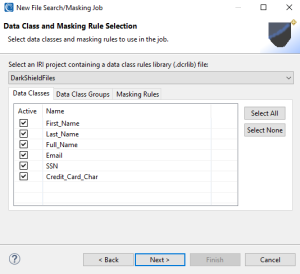
In the Data Class and Masking Rule Selection dialog, you will define the contents of your project’s IRI Data Class and Rule Library. This library contains Data Classes and/or Data Class Groups, and the data masking functions/rules you assign to them.
You can filter the Data Classes and Groups from the library that you intend to use by selecting or deselecting Data Classes in the Active column. In this example, I am using all default Data Classes provided when creating an IRI Project.
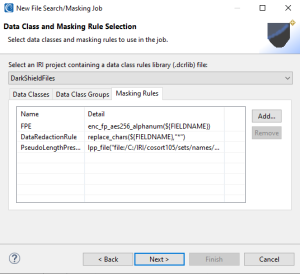
In the Masking Rules tab, we can see the masking functions are available. These rules dictate how PII found using Data Classes will be masked. It is also possible to add or remove Masking Rules from this tab.
Click Next when finished to move onto the page that will allow you to assign these Masking Rules to specific Data Classes.
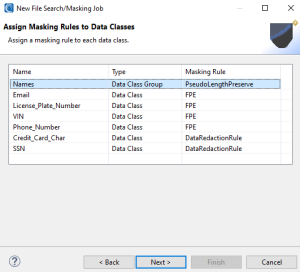
On the Assign Masking Rules to Data Classes wizard page, each Data Class or Data Class Group must be assigned a data masking function to specify how you will protect that type of PII (everywhere). If you do not wish to modify a particular PII type, click Back and deselect the Active checkbox associated with that Data Class or Group; then return here to finish assigning Masking Rules to Data Classes.
Once done, click Next > to begin specifying the location(s) of the files to search and mask:
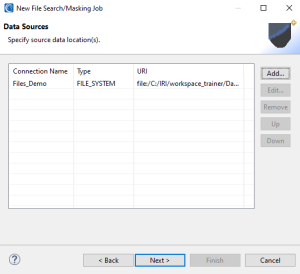
On this page, you add, edit, or remove data sources that DarkShield will scan. If you click Add… a sub-wizard opens so you can specify the file storage type and a connection registry.
A Connection Registry is a reusable connection configuration for connecting a data silo. To create a new Connection Registry first select the desired file storage type, then click New.
My example below demonstrates accessing files in the local (PC) file system, but DarkShield supports other (cloud) file sources (listed above) in Workbench. The DarkShield-Files API can support files that reside in other storage silos, plus streaming sources, using custom code.
After selecting or creating a new data connection, the connection registry information is displayed on the Data Sources page. The source item (URI) reveals the root directory from which the searches will occur. You can add more sources to the same search process here.
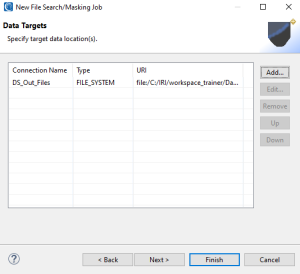
When finished, you can click Next > to open the Filter Selection page but skip it for PDFs and image files since it only applies to narrowing the search scope of flat or semi-structured (CSV, Excel, JSON or XML) files using metadata filters per this article. So click Next > from there to move onto targeting.
On the Data Targets page, you will provide the destination for your masked files. The steps to add a data target are the same as for a data source, except no file type selection is requested (since it will be in the same format as the source).
At this point, you can click Finish to produce a .dsc file, or Next > to move on to the File Search/Mask Configurations page. There you can further define job attributes applicable only to certain file types, like PDFs or image formats; see the Optional Search/Mask Configurations that follow.
These attributes can be stored for reuse in a configuration registry. You can select from an existing DarkShield File Configuration option registry entry, or create a new one.
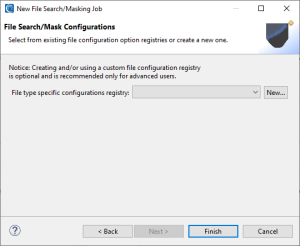
If you opt to create a New … entry, the file configuration option selection page will appear:
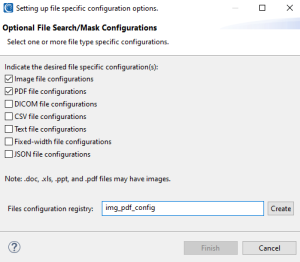
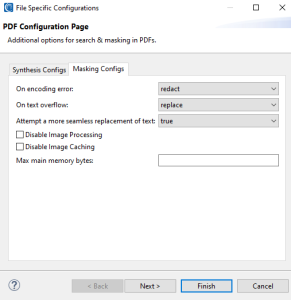
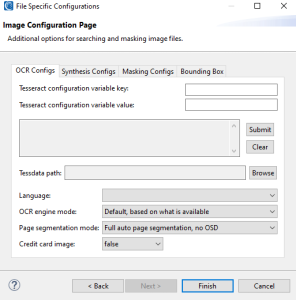
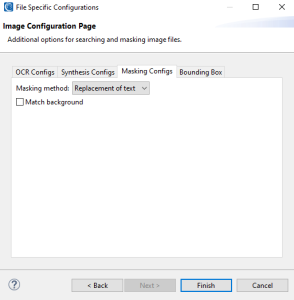
On this page, select the types of file configuration options to specify, and enter a name for the DarkShield File Configuration registry entry. Once that’s done, you can finally click Finish to produce the .dsc file that is used by the DarkShield API.
In the demonstration below, I will run a DarkShield Search and Mask Job on PDF and image files and show before and after examples. To run your DarkShield Search and Mask Job, right-click on the .dsc file and select Run As > IRI Search and Masking Job.
After running the job, PII found in the search phase gets immediately masked, and written into files with the same name within the data silo (target location) previously specified in the wizard.
Examples of DarkShield Search and Masking
Per my configuration options above, you will see that DarkShield applied a same-length pseudonym to the first name, format-preserving encryption to the phone number, and redacted the SSN where those data class values were found in both types of files below:
PDF before DarkShield:
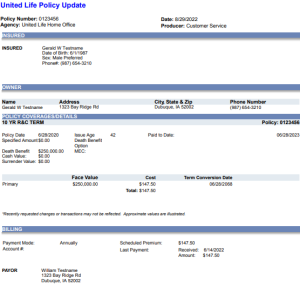
PDF after DarkShield:
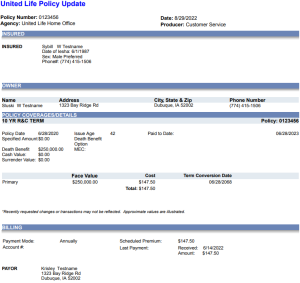
Image before DarkShield:

Image after DarkShield:

Check out our YouTube video here!
Contact darkshield@iri.com or your IRI representative if you have any questions or need assistance using DarkShield.










