
Schema Data Class Search
The Schema Data Class Search wizard in IRI Workbench (WB) designs search jobs for (PII or other) data in relational database schemas. The searches you configure in the wizard will compare data in entire schemas to location (metadata) and/or data (content) matchers that you previously associated with specific data classes (like email addresses, names, phone numbers, etc.).
The search process compares your data class matchers with column data it scans to determine the best matches, if any. The wizard then combines the results of data discovery and classification with your data class masking rules, and records this mapping to a file called the Data Class Map. It also produces several search logs and aggregate visuals.
Why Perform a Schema Data Class Search?
As mentioned above, a Schema Data Class Search will perform data discovery on multiple schemas and produce a Data Class Map. The Data Class Map is used by several wizards, including the New Data Class Map DB Masking Job wizard in IRI FieldShield, to automatically create job scripts for masking structured data in one or more RDB tables in one or more schemas.
Prerequisites
Before performing a Schema Data Class Search operation some initial setup steps are required.
- An IRI Project must be present in the workspace (Workbench project folder).
- There must be a Data Class & Rule Library (.dcrlib) available that contains at least one Data Class. You have the option when first creating an IRI project to generate a Data Class & Rule Library pre-populated with some default Data Classes and Rules.
- A connection profile is required to read from and scan the data inside tables of a schema during the process of a Schema Data Class Search.
To learn more about Data Classification and Data Classes read this article.
Several articles and videos discuss making connections to different databases inside IRI Workbench; e.g.,
- PostgreSQL DB Connection Setup
- SQL Server Connection Setup
- DB2 Connection Setup
- MySQL Connection Setup
- Oracle DB Connection Setup
Using the Schema Data Class Search Wizard
The Schema Data Class Search wizard can be accessed from two different entry points.
The first is from the Discovery Menu > Schema Data Class Search… to start the wizard.
The second is to access the wizard from the Data Source Explorer in IRI Workbench. From the Data Source Explorer, choose a database and right-click on the schema to be searched.
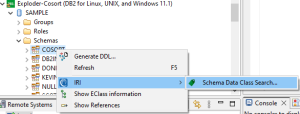
Regardless of which of the two entry points is used, the wizard will start by displaying the following setup page:
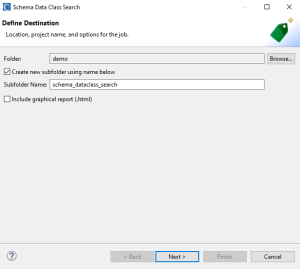
The first page is the initial setup to indicate which project this task is associated with, the name of the subfolder that will contain the search result files, and an option to produce a html graphical report.
The next page is where you choose a connection profile and schema or schemas that data classification will be performed against. To choose from a list of existing connection profiles, open the dropdown menu and select a connection or click New Profile to create a new connection profile.
Based on the connection profile selected a list of available schemas will be provided. Select at least one schema to classify. Click Next when finished.
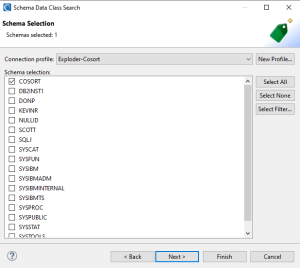
Note that depending on which entry point method discussed in the earlier section is used, the Schema Data Class Search wizard may already have a connection profile assigned and a schema selected to the schema you right-clicked on to begin the Schema Data Search wizard.
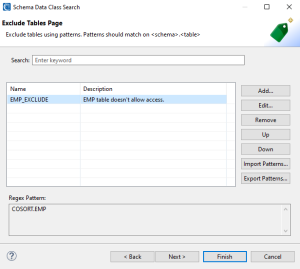
On the third page, you can optionally provide Regex patterns that will be used to exclude tables based on the fully qualified names of tables. Tables that matches particular patterns can be excluded to reduce the scanning volume. This is done to speed up the data classification process when there are tables that should be skipped or ignored.
On this page, enter regular expression patterns needed to exclude items. The patterns should follow this format: <Schema>.<Table>.
There are no exclusions in the example above as it is an optional parameter.
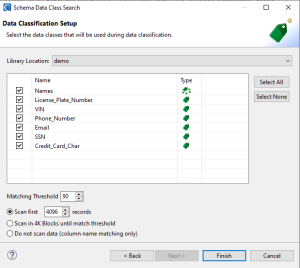
The fourth and final page is the Data Classification Setup page. On this last page, several options will determine how PII and other sensitive data are found and matched during the schema data classification process.
First, choose an existing IRI project with a Data Class & Rule Library in it from the top dropdown menu. Based on the Data Class & Rule Library selected, the data classes belonging to the library will be displayed in the table.
Check on or off to the left of each data class to determine which data classes should be used during the data classification process. Again, to learn about data classification and the different search methods to match on PII, read this article.
After indicating which Data Classes will be used for schema data classification, you will configure “depth of matching” parameters for the data in your tables. The first parameter is the matching threshold. This threshold tells the wizard to stop scanning the current column if it reaches the matching threshold after scanning N number rows of data (see below).
For this example, the default threshold of 90% is used. This means that if 90% of the first group of data in a column matches against a specific data class, scanning can stop and will move on to the next column.
The second parameter for depth of matching determines how many rows (records) in a table(s) may be potentially read and scanned. The default option is to scan the first 4096 (or some other specified number of records) and determine if there is a match based on whether the matching threshold was met. If a match is not found on the first block of records for that column, the scanning process will move on to the next column.
If you need a more thorough process of scanning their data, the second option is a better choice but potentially will increase the amount of time it will take to scan the schema(s). This is because columns will continue to be scanned in 4K blocks until the match threshold is reached or there is no more data in the column.
Alternatively, you could also choose to not match on the data itself and just try to match the column name. This will speed up the matching process in exchange for losing the ability to analyze the data itself.
Clicking Finish will start the search/map process. Depending on the volume of data being scanned, the wizard may run for a long time.
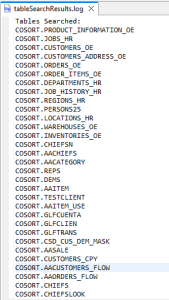
A file called tableSearchResults is created and records every table that has been fully processed. In case of a failure during the search, this file will show the last table that was successfully searched.
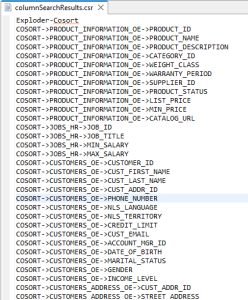
If a match was found during the data classification process on a column, a file named columnSearchResults gets appended with the name of the table and column where a match was found. If the option to match on names is selected, the column name is compared to the name of the data classes for a match.
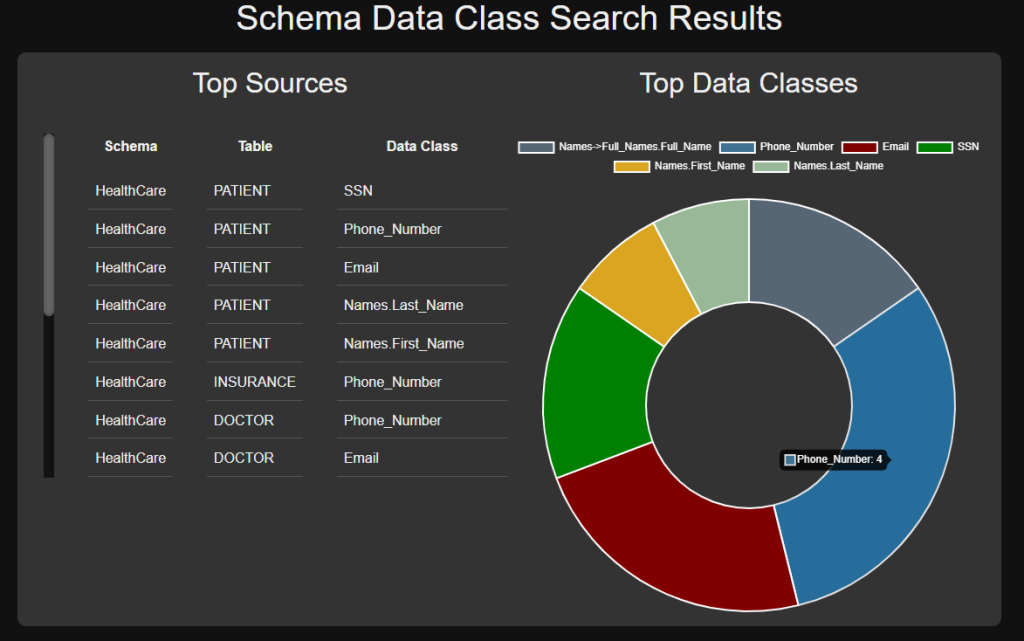
If you had chosen to generate an html report on the initial setup page, a discovery pie chart will be built to display the data classes that found matches. Hovering over each section of the pie chart will display the number of matches for the data class associated with that section.
Once the schema data classification has finished, a Data Class Map file (.dataClassMap) will be generated and a form editor for the map will open automatically. From the Data Class Map, you can see data profiling results and make various additional changes. And you can then use the map in New Data Class Map DB Masking Job wizard to run the data masking job using your masking rules tied to the data you’ve classified (discovered).
To learn more about the Data Class Map read this article. If you need help using the Schema Data Class Search wizard, please email fieldshield@iri.com.










