Common Challenges in Data Preparation
In your quest to turn huge sets of data into actionable business intelligence and AI models, consider these issues:
- Performance
- Complexity
- Quality
- Security
- Cost
- Redundancy
Performance
The bigger the data, the longer it takes to prepare and present information. BI, ETL and newer data blending tools cannot integrate or stage data sets that exceed memory, and require large servers or appliances, in-memory DBs, or even Hadoop.
What if you could easily leverage a proven big data preparation engine at reporting time that multi-threads and scales linearly in your file system? In other words, if you could marry data integration to faster and more reliable insights and AI models.

Complexity
When IT integrates data for business users, report results can suffer. DW ETL activities and data service deliverables may reflect wrong or duplicate data sources, values, formats, and types. The disconnect comes from their disparate missions, methods, and platforms.
What if business and IT users could easily identify, validate, cleanse, and normalize (homogenize / standardize) all the sources of data that feed the reports or stock the data lake?

Quality
Trying to manage the variety of data formats from different silos and feeds often takes several tools, and even specialized techniques from multiple people. Time to roll-out, and time-to-value, lags at inception and throughout the use of disparate platforms controlled by IT.

Security
Encryption, pseudonymization, and other data masking functions that are needed to comply with data privacy regulations usually require other software products and/or processing steps.
What if field-level security functions could be applied directly at reporting or data preparation time?

Cost
Big data preparation (ETL) tools and hardware (Hadoop) technologies -- as well as most sophisticated BI and data blending platforms -- are expensive to acquire, implement, configure, and maintain.
What if you only needed one product supported in a free Eclipse GUI that provided everything you needed to report directly with built-in tools or rapidly prepare data for your own?

Redundancy
Integrated data in the BI layer is not only slow (or impossible) given the volume, variety, velocity and veracity of data today, but their internal data integration operations are inherently complex, require repetition, and create data synchronization issues.
Centralized data preparation on the other hand resolves those issues, allows you to manage changes to source data in one place, and creates better data targets ready for multiple reports.

What's Your Approach?
Reliable business intelligence and faster analytics are two of the biggest headaches for IT managers and data scientists. A whole industry of complex (and costly) ETL and data blending tools has arisen to help them munge and mine data faster. And in the era of AI, most organizations spend more time preparing data than training models.
Meanwhile, IRI (The CoSort Company) has been rapidly and affordably integrating, transforming, cleansing, and masking big data for enterprises worldwide since 2003. In those days, staging data was called data franchising. Today we continue to excel at high-performance data preparation, wrangling, blending, or whatever you want to call it.
And because our customers' analytic needs, reporting tools, and AI model training needs vary, the IRI Voracity platform supports multiple ways to deliver information from the data. In fact, only IRI customers can leverage any -- or all -- of these approaches from the same data preparation and presentation environment built on Eclipse:
- KNIME AI Integration
- Splunk Add-On
- Cloud Dashboard
- Your Analytic Tool
Embedded BI
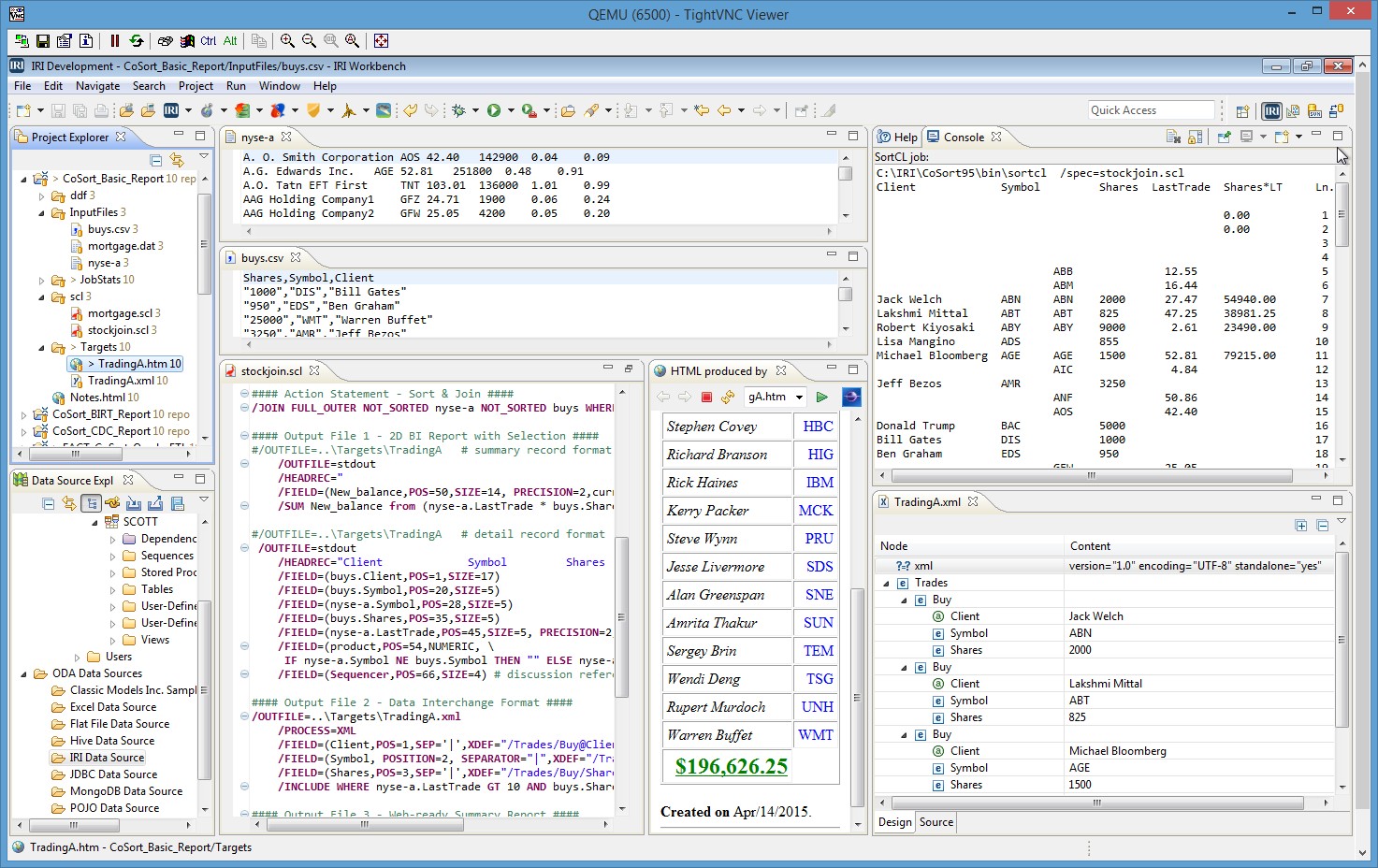
IRI's embedded reporting capabilities allow you to drive BI results on big data as you transform it. The built-in formatting capabilities in all IRI products let you capture the value of information seamlessly and in the shortest amount of time.
 Learn More
Learn MoreKNIME AI Integration
KNIME is an open source analytic and AI platform built on Eclipse. The IRI Voracity node for KNIME can feed KNIME nodes from data wrangled in the CoSort engine in Voracity to combine data preparation and model use in real-time.
 Learn More
Learn MoreSplunk Add-On
Put Splunk into overdrive. IRI's free Splunk add-on for Voracity simultaneously indexes big or dark data from Voracity. Cleans, transform, and mask your data going as you feed it into Splunk!
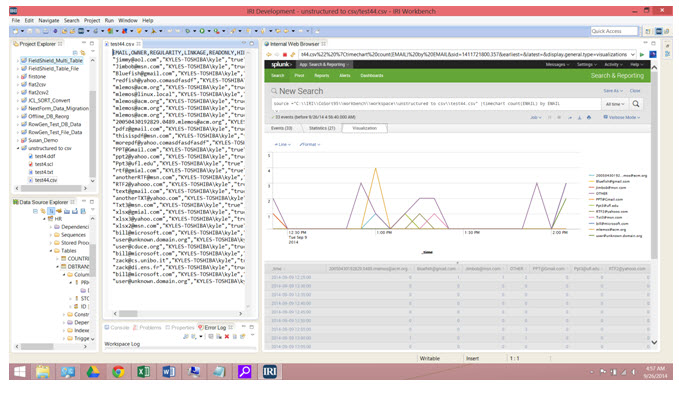 Learn More
Learn MoreCloud Dashboard
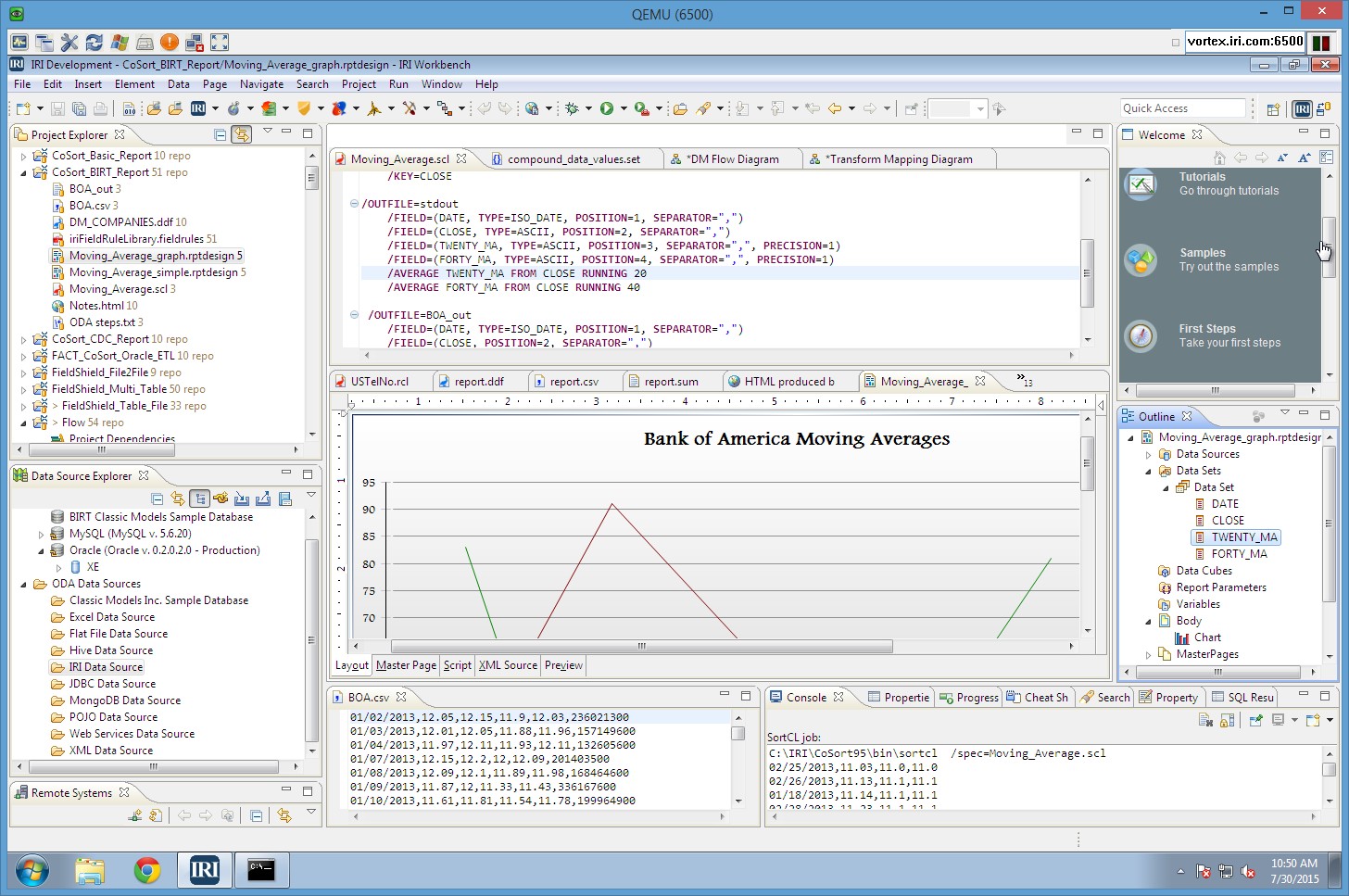
See and learn more with a modern dashboard inside the IRI Workbench GUI or your browser. Visualize and interact with data you can first transform, cleanse, and mask in Voracity. Prepare data anywhere and see information everywhere.
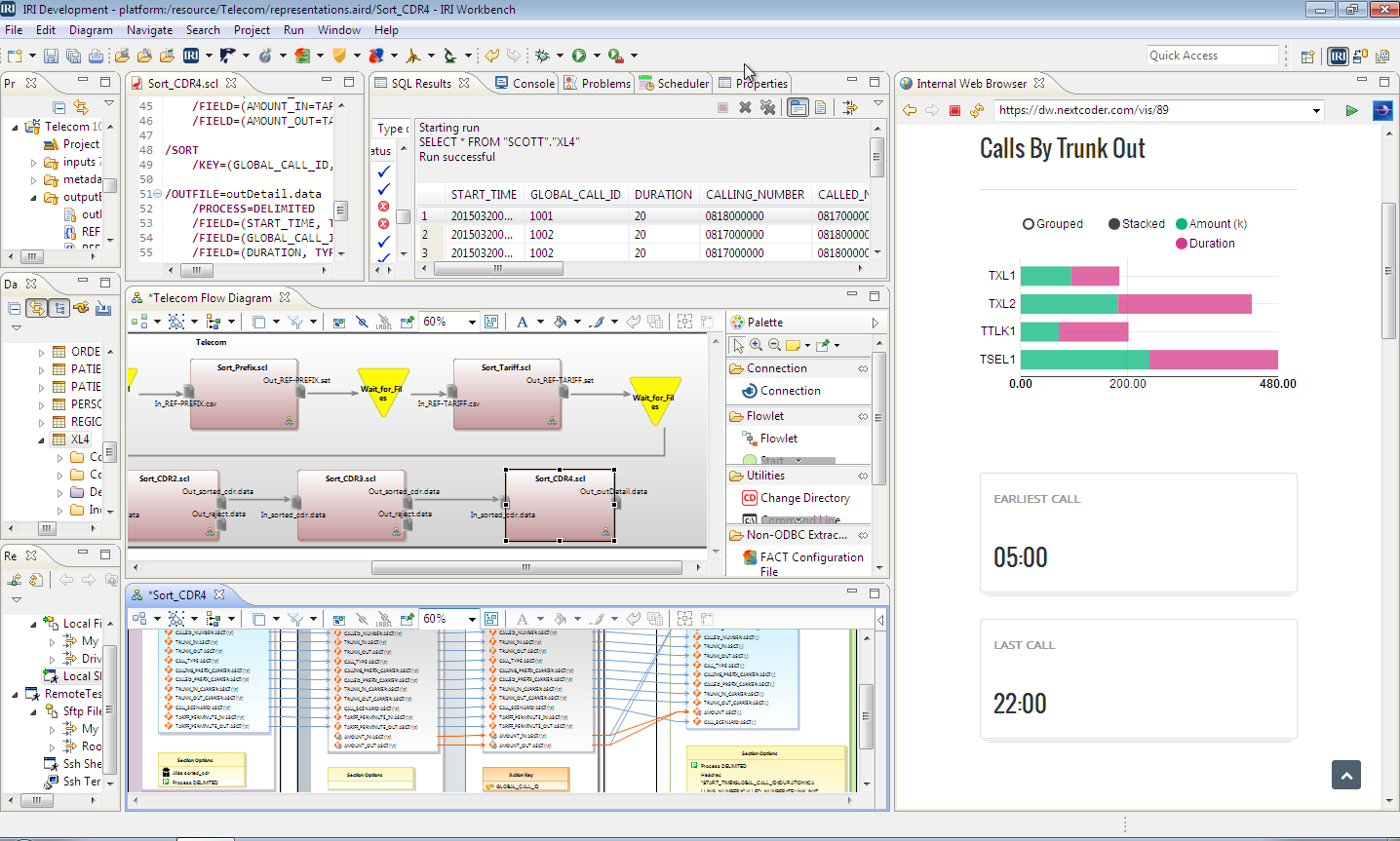 Learn More
Learn MoreYour Analytic Tool
Stop trying to transform, clean, and mask data in slow BI, DB, ETL, and specialty data blending software. Click on your tool below to see how you can discover and prepare data in Voracity -- with the proven performance of CoSort or Hadoop engines -- and get clean, compliant subsets your tool can use to render displays up to 20X faster: