
IRI Data Class Map
In past articles we have discussed the Data Class & Rules Library and leveraged this library in data classification processes (Schema Data Class Search and Directory Data Class Search), that in turn produce a file called a Data Class Map. For the topic of this article, I will discuss what a Data Class Map is and how to leverage different options for working with, and leveraging them, in the IRI Workbench IDE.
A Data Class Map is a file (.dataClassMap) used in Workbench to record mappings between fields and data classes and/or field (masking) rules. The Data Class Map file is used in both the New Data Class Map DB Masking Job and the New Data Class Map File Masking Job wizards in the IRI Workbench GUI for FieldShield to produce FieldShield data masking job scripts.
The data class map has mappings of fields of a data source to rules, which are assigned based on data classifications. The data class map is only used with FieldShield, and can generate its SortCL-compatible FieldShield Control Language (.fcl) job scripts by right-clicking on the file and going through the corresponding file mask or database masking wizard.
A Data Class Map is not to be confused with a Data Class & Rules Library (.dcrlib), which is a library containing definitions of data classes and rules that are used by many wizards such as in the RowGen, NextForm, DarkShield, and some FieldShield wizards.
How to Create a Data Class Map
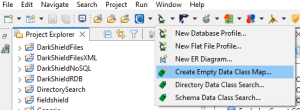
You can create a Data Class Map by going through one of the three wizards in the top toolbar menu for Data Discovery. The first wizard, Create Empty Data Class Map … steps you through the process of creating an empty Data Class Map (i.e. one containing no data class mappings).
Next is the Directory Data Class Search wizard. This wizard steps through the process of performing data classification on files in directories on the local file system, and then generates a Data Class Map to map the fields in those files to your data classes and masking rules.
Finally, there is the Schema Data Class Search wizard that will walk you through the process of performing data classification on tables in a schema(s) to produce a Data Class Map containing mappings between columns in tables and data classes and rules.
Data Class Map Form Editor Parts
- Data Class Map Tree View
- Data Class Map Main Details Page
- Table/File Data Info Details Page
- Data Class Map Toolbar
Data Class Map Tree View
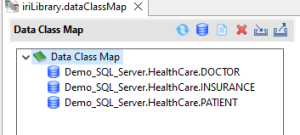
The Data Class Map form editor provides an overhead view of the various tables and files data sources from a widget referred to as a Tree View. This Tree Viewer displays nodes that represent different items based on the associated icon.
At the top level of the Tree viewer is a parent node 
For each table or file in a Data Class Map that contains mappings, there is a child node 

Data Class Map Main Details Page

The Main Data Class Map Details page provides details about the data classes (and the rule applied to said data class) currently being used by the Data Class Map to perform operations like auto-classification on tables and files. You can scroll through the list of active data classes and double-click on entries to open a page called Data Class Details.
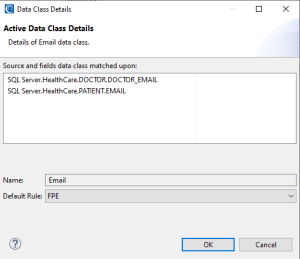
The Data Class Details page allows you to see a list of fields the data class has mapped to across different tables and schemas or files. There is also a dropdown menu for changing the rule assigned to a Data Class. The Rules displayed in the dropdown menu are the rules internally stored in the Data Class Map.
To update the list of Rules accessible by the Data Class Map, you need to add a Rule to the .dcrlib and then perform a Sync and Update process from the Data Class Map toolbar. Toolbar options will be discussed further, below.
Note that when the Rule assigned to a Data Class is changed from this page, the Data Class Map will automatically update the fields that were mapped to that particular Data Class with the Rule that had been selected from the Default Rule field’s dropdown menu.
Table/File Data Info Details Page
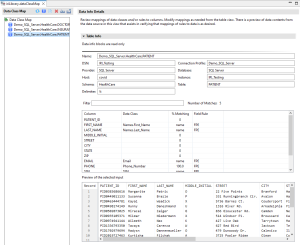
The Data Info Details page in the Data Class Map form editor displays various information about the data silo. Inside the Data Info Details page, there are three sections: the Table/File Info, Field Mappings, and Data Preview.
Table/File Info
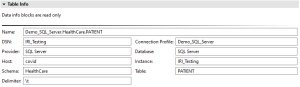
In the case of a table, the Table Info section lists details about a table including connection information. When a Data Info Details page is associated with a file there is a File Info section instead. The File Info section likewise lists details about the file in question.
Field Mappings
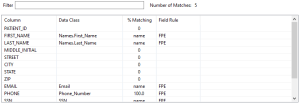
The second section of the Data Info Details page displays a view of the field mappings after data classification has occurred. As you can see from the image above there are four columns: Column, Data Class, %Matching, and Field Rule.
The first column displays the column names of tables or files when the header is present in the file.
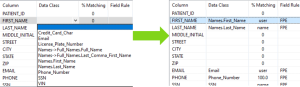
The second column displays what data class has been matched to a field if any. In this column, you can manually reassign or unassign the data class matched to a field.
If a data class is assigned to a field and also has a default rule, the Field Rule column will be updated to reflect the change to the new rule assignment for said field. Likewise, the %Matching column will be updated and indicate that a manual user assignment has occurred.
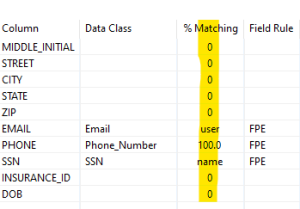
The third column shows the percentage of matches found using data matchers inside a data class. The percentage of matching is useful because we can assign depth of matching thresholds to our Data Class Maps to account for false positives or false negatives. On the other hand, if a match is found on a column name in a location matcher, the keyword name shows:
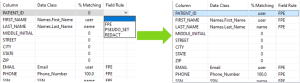
The fourth column displays the masking rule assigned to a column in a table or field in a file. In this column, you can manually reassign or unassign the rule that matches a field.
The rule you assigned determines how the data in a column (or field) will be masked when a FieldShield job is created. If a rule is manually assigned, the %Matching column will indicate that a manual user assignment occurred.
Preview of Data
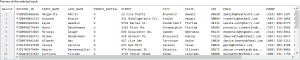
The last section is the preview of the source table or file data. By default, only the first twenty rows of data will be displayed in the preview section.
Data Class Map Toolbar
Toolbar Actions:
-
Sync with the latest changes to Data Class & Rule Library and re-classify tables in Schema with new and/or update data classes and rules.
-
Auto classify a new table.
-
Auto classify a new file.
-
Delete either a table or file mapping.
-
Import a flat file (.tsv) to generate mappings of masking rules to columns in tables.
-
Export the existing mapping in a Data Class Map to flat file (.tsv).
Sync with Data Class Library / Update Data Class Map
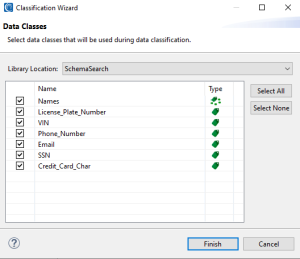
Sometimes you may need to make changes to data classes or rules stored in an IRI Data Class & Rule Library after making a Data Class Map. For a Data Class Map to reflect these new changes in its mappings, it first needs to update its internal list of data classes and rules based on the latest version in the IRI Data Class and Rule Library.
Afterward, the data classification process must be redone anew. This is because the results of classification and subsequently produced field mappings may differ after changes are made to data classes and rules.
To perform a SyncUpdate you must launch the Classification Wizard via the
Once the data classes are set up you can click Finish to begin the data classification process anew. The latest version of your data classes and rules will then be in the IRI Data Class and Rule Library.
Auto Classify New Table
The Data Class Map file also acts as a sort of staging phase to review your current column mappings and to modify them as needed. You can also manually add a table into an empty Data Class Map or one that wasn’t included in a previous Schema Data Class Search operation.
To do this, click the Auto Classify New Table
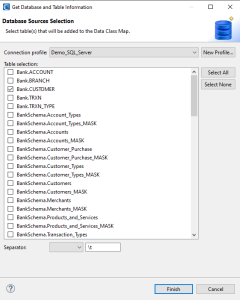
As shown above, a page will open for you to select a database connection profile from a list of existing profiles, or to create a new connection profile. Based on the profile you specify, a list of tables across various schemas should appear.
Select one or more of the tables that you want added to the Data Class Map and automatically classify (from stored Data Classes) to build new column mappings. Once you are done with that step, click Finish.
From the example below, you can see a new table was added from a different schema and column mappings were produced:
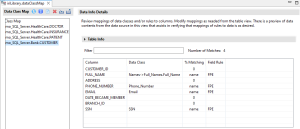
Auto Classify New File
Similar to the Auto Classify New Table option, you can also manually add a file into an empty Data Class Map or add one that wasn’t included in a past Directory Data Class Search. To do this, click the Auto Classify New File
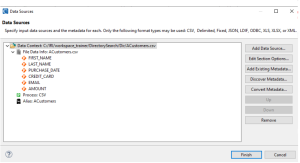
A page will open for you to provide the data source (in this case a file) and any metadata regarding the structure of the file. If no metadata file exists, you can generate it through the Discover Metadata option.
Once you are done setting up each new data source and its fields, click Finish.
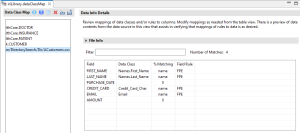
The example above shows that a new file was added and its field mappings were produced.
Delete Source
To remove tables or files and their related mappings from a Data Class Map, just select the table or file node and click on the
Import a Flat File to Create Field Mappings
If you already have table/PII location details in a spreadsheet, you can create IRI field mappings from a tab-delimited file with that information. Import file entries must be in this format:
<schema_name>TAB<table_name>TAB<column_name>TAB<dataclass_name>TAB<rule_name>
OR
<schema_name>TAB<table_name>TAB<column_name>2TABs<rule_name>
Each line entry in the import file can take up to five parameters, with at least four required and one optional parameter. The schema (column1), table (column2) and column (column3) names are required. A data class name (column4) is optional, but a rule name (column5) is required.
Here is an example of an import file with all five columns shown:
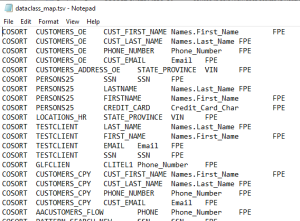
Note that the schemas, tables, and columns listed in the import file you use must already exist in a database. Likewise, the data class and rule names in the import file must exist in your .dcrlib file.
The names of data classes and rules are used to search the .dcrlib and retrieve the data class/rule’s information based on the unique name associated with individual data classes and rules stored in the .dcrlib. The data class and rules retrieved from a .dcrlib file are used to make mappings inside the Data Class Map.
To begin the import process click the
Export Existing Mappings
The export button on the Data Class Map toolbar will begin the process of converting and exporting field mappings stored in the Data Class Map to TSV file format. Each line entry in the export file will represent one field mapping.
The entries in the export file are in the following the format:
<schema_name>TAB<table_name>TAB<column_name>TAB<dataclass_name>TAB<rule_name>
OR
<schema_name>TAB<table_name>TAB<column_name>2TABs<rule_name>
To begin the export process click the
Need Help?
If you have any questions about data classification and column mapping in your IRI FieldShield data masking operation for a relational database, please email fieldshield@iri.com.










