Mapping DB Data Types
Abstract: The process of transferring data from one database (DB) to another can be complicated when those DBs do not use the same data types. A DB Data Type Mapping wizard is now implemented in IRI Workbench to help solve this problem for SortCL-driven data management jobs with different sources and targets.
After completing a task like multi-table masking in FieldShield for example, if the target schema does not have the tables already created to place the masked data, Data Definition Language (DDL) scripts must be generated ahead of time to create the tables.
Now suppose that the source and target tables are in different vendor databases. There can be errors with the DDL because the wizard generating the scripts encounters a data type that is in one vendor but not the other.
At this point, a default data type is used – often Varchar – which isn’t the best solution, which forces the user to examine the scripts and modify them. This can be a time-consuming process and if the user is not careful, it can lead to a loss in data.
With the implementation of the new Data Type Mapping wizard, IRI Workbench users can dictate which data types should be used when going from one database to another.
The IRI Workbench GUI is built on Eclipse and is used to create job scripts that allow for the movement and manipulation of structured data through compatible IRI products. All the work specified in those scripts is performed at runtime by the back-end SortCL data processing program.
Overview of Data Type Maps
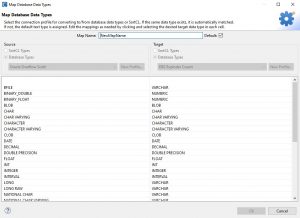
The Data Type Mapping preferences can be found in the IRI section in Preferences. The first view provides information on the maps created and allows for several options such as adding new maps, editing existing ones, removing, and importing/exporting:
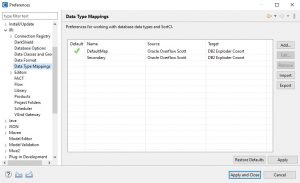
The table has four columns, including the Source and Target, which shows the names of the DB profiles created when setting up the JDBC connections. These are the same names you should see in the Data Source Explorer view.
The Name column holds unique names for data type maps which can provide context for using these maps in different Workbench job wizards. This is why names must be unique.
The Default column allows you to specify which map will be used by default when job wizards create DDL scripts. If the default is not selected, the user can still use a map if the source and target DB and version are the same as the source and target DB used in the wizard.
Creating a Data Type Map
To create a new map, click Add… and a new window will appear like the one below.
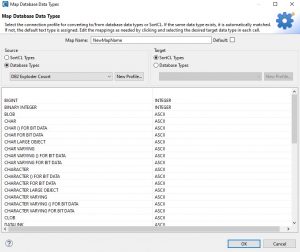
The default name of NewMap is automatically provided, but you should rename it. Next to the name is the default selection; check this if this new map will be the default map for the source and target DB in your jobs.
As for the Source and Target sections, you can choose to map data types between databases or from/to SortCL job scripts. If you select a database, the drop-down menu will present all previously configured connection profiles, as the image below shows:
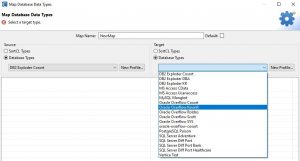
You will not be able to create a map that has the same source in the target, however; i.e.,
- SortCL to SortCL
- The same connection profile in source and in target
- Same vendor to same vendor 1
You can make several maps that share the same source and target, but only one map can be set as the default. If the user tries to create a new default map the wizard will check to see if there are any prior/existing default maps that use the same source and target.
If so, a pop up will appear showing the name of the existing map and warn that if the new map is saved as default, it will remove the prior/existing default map from being the default.

Once a selection is made for source and target, the table below will automatically be populated with their respective data types for the DB vendor and version, or for SortCL.
To obtain the version number from the DB, the wizard first tries to retrieve it from the DB server. Verify your DB version by going to the Data Source Explorer and right-clicking on the connection profile, and selecting the properties option. Under Version, the right DB release should show:
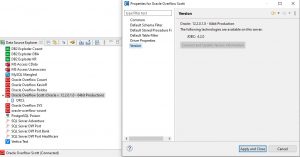
If an incorrect version is showing or has missing information, click on Connect and Update Version Information to fix it.
Suppose the database server version is not available, the wizard will then try to query the database’s version number by looking at the template driver used when the JDBC connection was first created. This is prone to error because you can use an incorrect driver template to connect to the DB.
For example, if you set up a JDBC connection to Oracle 12c with a driver template for Oracle 8, you can still connect to the DB but the system version and the actual DB version do not match. This can cause issues with data types available to the DB when creating the data type map.
The best practice is to ensure that the server version displays the correct DB version, so when the wizard queries the DB it receives the correct version.
Why Create a Default Map?
Having a default map avoids having to create a map for each connection profile. Maps that share the same vendor and version but not the exact connection profiles are still available as an option in a job wizard.
For example, certain maps can be created with a specific purpose in mind, such as matching Timestamp data type to Varchar to avoid losing the microseconds in the data, but this map isn’t needed for every job. This can make it confusing to select the correct map for the job especially as more maps are created in the future.
Having the option of making a map the default is available so you can know this default map was made for this exact same source and target, and contains the data types that are used for most jobs.
How the Data Types Actually Map
Let’s shift our focus to how the data type matching is done from source to target. If the DBs share the same data type, then the matching pair will also share the same data type. For example, the wizard will map integer to integer if both Oracle and DB2 use an integer data type.
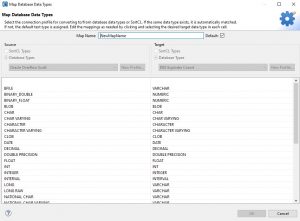
If the source and target do not share the same data type, the closest data type will be used for the matching pair. For example, Binary_Double in Oracle is mapped to Numeric in DB2.
You can however still manually override this, and specify which data type to use in the target column. Select the data type that needs to be changed and a drop-down menu will appear with all the data types available for the target DB (or for SortCL).
For example:
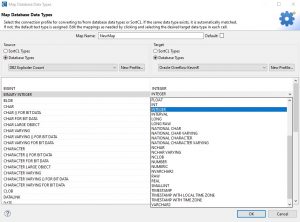
Once everything is set, click OK and the newly created map will appear in the data type preference page. It is important to know that any changes done to the data type maps do not take effect until you click Apply or Apply and Close. If you cancel, no changes are saved.
Editing a Data Type Map
You can make changes to existing data type maps by highlighting the map to change and selecting the Edit… button on the right side of the table, or by double-clicking on the map.
You can change the name of the map, select if the map will be used by default or not, and change any of the mappings between the data types. You will not be able to change the source or target DB, however.
Exporting Data Type Maps
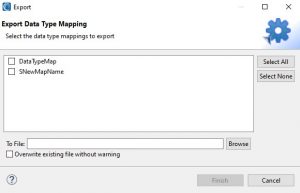
You can share your cross-DB data type mappings with other IRI software users by selecting the Export button. In the window that opens, you can select which map(s) to export.
Specify an output file folder and name for the map. The resulting XML file will contain all the information on the data type map(s) you selected.
Using a Data Type Map
As of this writing, there are three Workbench wizards that can use these data type maps:
- Sub-Setting job (Voracity)
- Multi-Table Masking job (FieldShield)
- Etl-Join Job (Voracity)
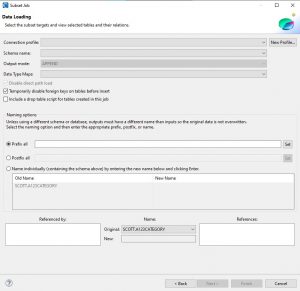
These wizards work the same way as they have, but now also have a new option to specify the data type map in their Data Loading page. The screenshot from the DB subsetting wizard below shows the data loading with the option to select a data type map right below Output mode:
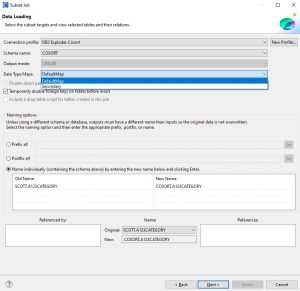
If there is a corresponding data type map for the source and target DB for the sub-setting wizard, then the drop-down menu will be enabled to allow you to pick which map to use. The example below shows a map called DefaultMap which is already selected, but there is another map available called Secondary.
The drop-down menu for the data type map will be disabled if there are no maps that correspond to the source and target DB specified in the sub-setting wizard.

Use Case
In this example, a Voracity sub-setting job is performed on source tables in an Oracle schema which targets tables in DB2.
The DB subsetting wizard in IRI Workbench automatically generates the CREATE and ALTER TABLE statements in a DDL file for the target schema along with the SortCL scripts that extract, join, and load the data from the source. Specifically, the wizard builds a batch job that re-creates the source table structures and their constraints in the specified target DB, and places the subsetted values into the newly created tables.
Oracle and DB2 share very similar data types but there is a special case for Varchar2 and Number. DB2 technically supports those data types but not by default. Upon creation of the target DB, those two data types need to be enabled for DB2 to support them.
On our first try, the DDL scripts needed to create the tables in the target DB (DB2) are not using data type maps. The DDL shows there are several tables with Number and Varchar2 columns:

In our first run, there is an error at execution time during table creation, due to Number or Varchar2 being recognized as an undefined name. This means every instance of Number or Varchar2 would have to be changed to an equivalent data type supported by DB2.
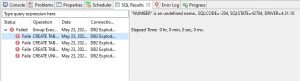
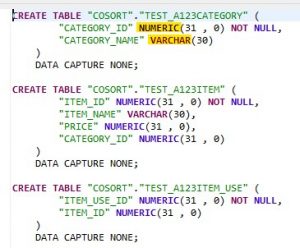
In our second try, however, with the right mapping defined, Number was automatically mapped to Numeric and Varchar2 was mapped to Varchar. The creation of the DDL scripts shows that the correct data type went to the target tables.
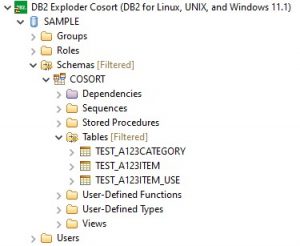
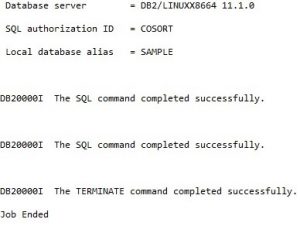
The subsetting job ran without errors and was completed with tables created and populated in DB2. This demonstrates that setting up a data type map can help prevent errors, and save the time involved with manually creating and editing multiple DDL scripts.
If you have any questions about this article, or if you need assistance with mapping data types from your sources to targets in IRI Workbench, please email support@iri.com.










