Data Masking/Protection
Data Masking/Protection
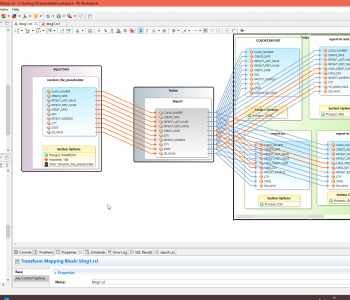
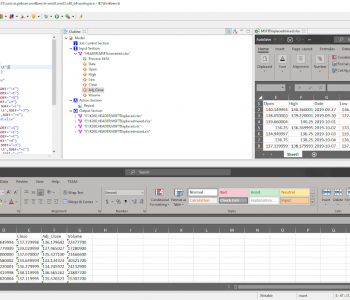
Connecting MariaDB and MySQL to IRI Workbench
MariaDB and MySQL are relational databases that follow the same paradigm when it comes to setting up connections with SortCL-driven Voracity component jobs designed in IRI Workbench. Read More