Building Test Data in a CI/CD Pipeline
Automating where you can, when you can, is the basis of DevOps testing and test data automation. Allowing IRI job script executions which mask or synthesize test data to be handled in the CI/CD pipeline supports this pursuit. This test data management article illustrates an end-to-end example of a successful integration with GitLab. This is the first of four articles in a series; subsequent articles in this blog show how to feed IRI test data into Amazon CodePipeline, Azure DevOps and Jenkins.
The Growth of DevOps
DevOps is a phrase that many, if not all of us have heard when discussing the latest trends and movements in the tech industry. DevOps combines software development (Dev) and IT operations (Ops) to accelerate the systems development life cycle and provide continuous delivery of high quality software.
DevOps processes are an integral part of product lifecycle management for large companies releasing new versions of source code. For example, Amazon is deploying code to production every 11.7 seconds; Netflix deploys thousands of times per day; and, Fidelity saved $2.3 million per year with their new release framework (Masse, Aug 6, 2019)1.
A common real-world example of DevOps CI/CD in the frequent, iterative deployments of APIs (application programming interface). In recent years, APIs have become critical to the growth and revenue of companies. Salesforce generates 50% of its revenue through APIs, Expedia generates 90%, and eBay generates 60% (Masse, Sept 3, 2019)2
 Well Known APIs: Yahoo Finance API, Zillow API, and Open Weather API
Well Known APIs: Yahoo Finance API, Zillow API, and Open Weather API
What Is CI/CD?
In DevOps, CI/CD stands for Continuous Integration and Continuous Delivery/Continuous Deployment. The phases of CI/CD can be explained this way:
- Continuous Integration is the method by which software developers regularly deploy iterative code changes into a repository. Then a CI service will build and run tests against the new changes to the repository automatically.
- Continuous Delivery starts after CI. Code is deployed to a test or production environment. Automated tests may run during this stage. If all tests pass the code can be manually approved for update to production.
- Continuous Deployment differs from Continuous Delivery in that deployment to production happens without manual approval.
What is Being Demonstrated Here
As a part of DevOps CI/CD, Continuous Testing is the testing and evaluation of software at every phase of the software development lifecycle. Testing software after it has been deployed to an environment is par for the course.
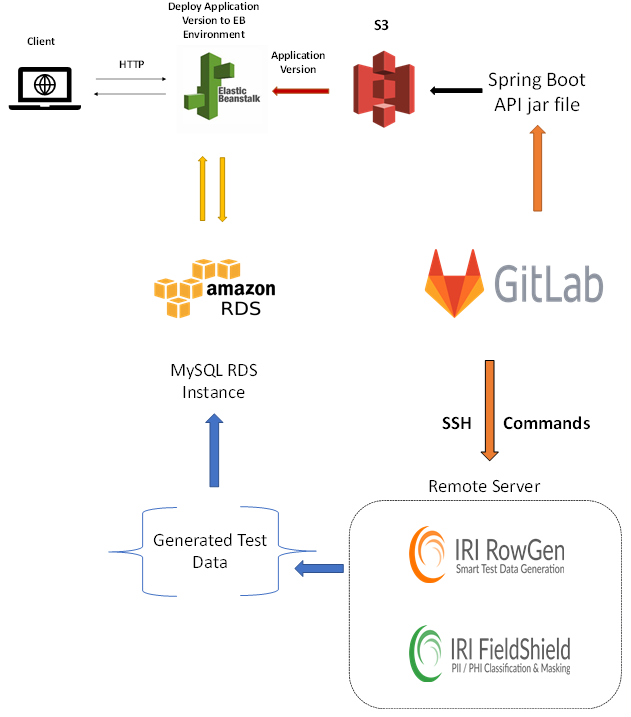
For the sake of providing a demonstration that simulates a common real-world business practice, I am using an API that will be built, tested, and deployed through a GitLab CI/CD pipeline. I am also incorporating IRI test-data-producing jobs into this same pipeline to automate the provisioning of test data in my test database DATASOURCE1 in an AWS RDS instance.
The IRI test-data-producing jobs will be used to populate the rows of a table called MEMBER_TB, with the fields ID, FIRSTNAME, LASTNAME, PHONE, EMAIL, STREETADDRESS, ZIPCITYSTATE, and DOB, in the test database (DATASOURCE1) that will be used during post-deployment testing. During post-deployment testing, the API in this demonstration will retrieve rows of test data from the table MEMBER_TB, located in the test database DATASOURCE1, using Postman.
Please note that this article focuses on how to leverage a GitLab CI/CD pipeline to automate IRI job script executions. As such, a basic understanding of the GitLab CI/CD pipeline is assumed.
About IRI Test Data Jobs
Fit-for-purpose, standalone IRI software products — namely, IRI FieldShield for searching and masking, and IRI RowGen for subsetting or synthetic data generation (i.e., creating structured data from scratch) — produce safe, realistic, and referentially consistent test data for relational and NoSQL databases. IRI DarkShield can find and mask sensitive data in semi- and unstructured sources, too. You can also combine RowGen and DarkShield to produce test documents and images.
All of these products, along with others, are also supported components of the IRI Voracity data management platform.
 Bloor Research Report on IRI Test Data Management
Bloor Research Report on IRI Test Data Management
In this POC, I use both FieldShield and RowGen to populate a GitLab pipeline with smart data that can be used in post-deployment testing.
Building the CI/CD Pipeline in GitLab
GitLab is a service that provides remote access to git repositories and facilitates team collaboration. It supports the DevOps platform with its built-in tools for CI/CD and issue tracking. Furthermore, GitLab offers a free version and has an active community in its forum.
To use GitLab pipeline a file called .gitlab-ci.yml needs to be located in the root of the repository. GitLab will use runners to run the script found in the YAML file.
Runners can be either shared or private runners installed locally on your machine. With GitLab’s free tier, users can use shared runners for 400 minutes’ worth of CI pipeline execution time.
Pipeline Structure
The CI/CD pipeline consists of jobs which are written to do or perform a certain task. Jobs are contained in Docker images, and when the job ends the Docker images closes and all data is lost.
To pass data from one job to another, a job artifact must be made. Jobs are designated to run in specific stages (i.e., build, test, staging, or production).
If multiple jobs are run during the same stage, they will run in parallel with each other to save time. Unless configured to do otherwise, if any job fails in a stage, the pipeline will not move on to the next stage.
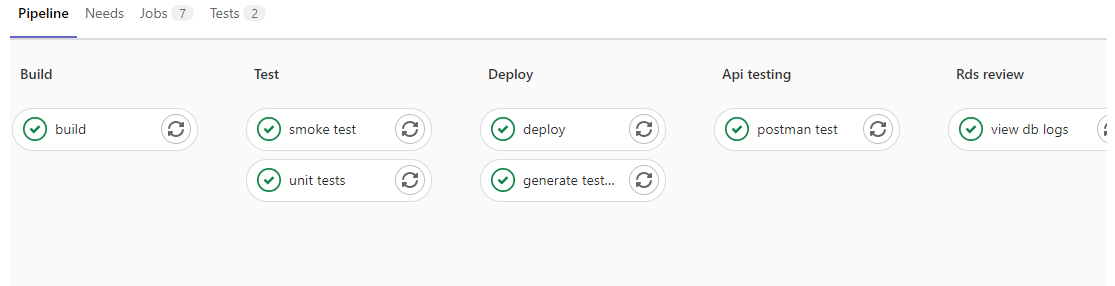 GitLab Pipeline
GitLab Pipeline
Pre-requisites
- Your IRI software product is installed and licensed on the target remote server (the remote server that the GitLab runner will access via SSH could be your on-premise computer, an AWS EC2 instance, etc.).
- The server where the IRI job script is located can be accessed with SSH.
- An AWS account (for my purposes the free tier was adequate).
- A relational database instance with appropriate inbound and outbound rules.
- An AWS Elastic Beanstalk web server environment.
- An S3 Bucket.
- An IAM user with programmatic access and the necessary permissions set (AmazonS3FullAccess and AdministratorAccess-AWSElasticBeanstalk).
- AWS credentials stored as environment variables in GitLab.
CI/CD Pipeline Breakdown
Defining stages, in script variables, and services
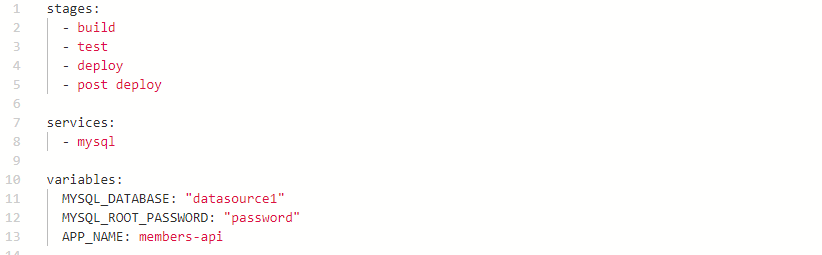 Top of .gitlab-ci.yml file.
Top of .gitlab-ci.yml file.
Build Stage
 Build Job
Build Job
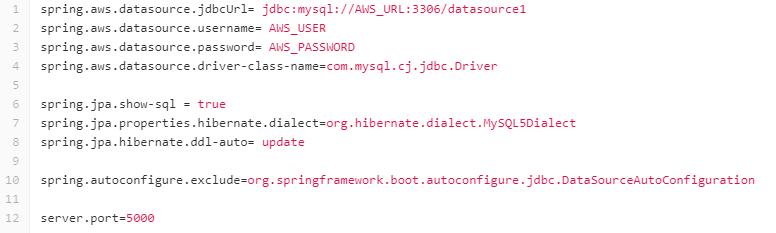 application.properties file
application.properties file
The placeholders in the API’s application.properties file, must be dynamically replaced with the credentials for the test database DATASOURCE1 in my AWS RDS instance. The sed command is used to find and substitute these placeholders with the variables stored in GitLab.
Test Stage
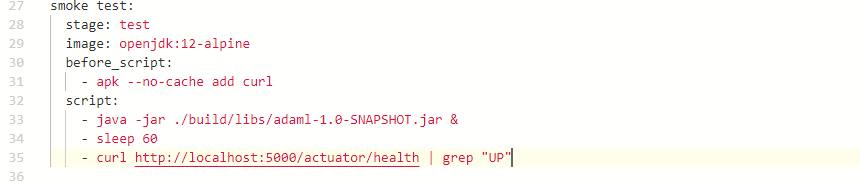 Smoke Test Job
Smoke Test Job
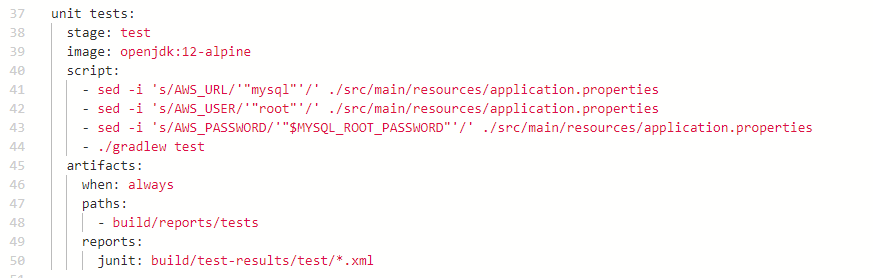 Unit Tests Job
Unit Tests Job
GitLab provides some useful documentation on how to produce Unit test reports.
Deploy Stage
Before trying to SSH to a remote machine from the pipeline, you must first verify that the target machine has SSH enabled. If you are running Windows, it will not be enabled automatically.
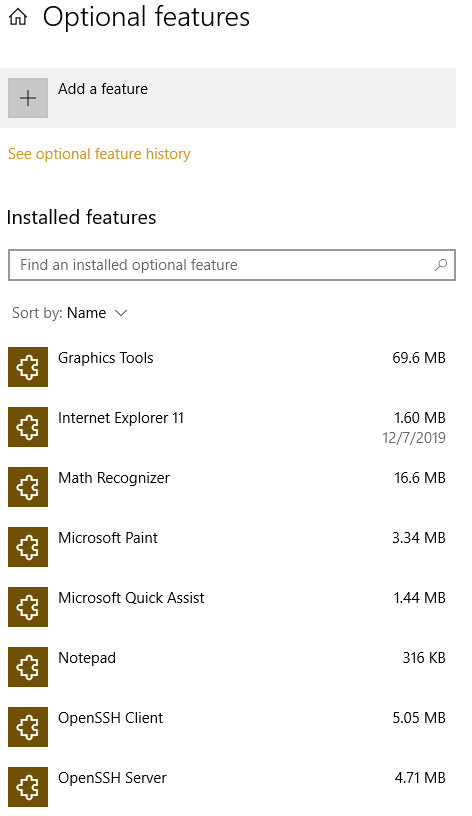
To install SSH for Windows 10 you must do the following:
- Go to Settings .
- Apps and click “Optional features” under Apps & Features.
- Click “Add a feature” at the top of the list.
- Select from list “OpenSSH Server”, then install.
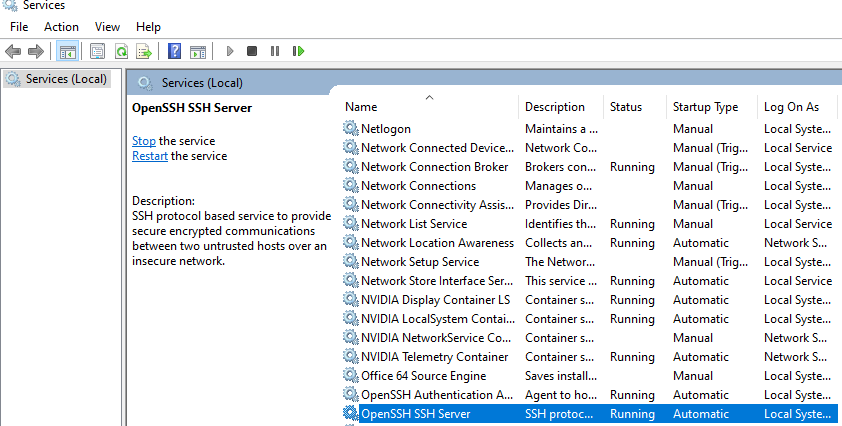
To enable OpenSSH Server and SSH Agent Authorization (SSH from within CI pipeline requires your target server to have both enabled):
- Type Services in your search bar and open Services.
- Scroll down until you find OpenSSH Server and right-click.
- Click properties.
- In the general tab, click the dropdown list for startup types.
- Set to Automatic then click apply.
- Repeat this process for OpenSSH Authorization Agent.
In GitLab you will need to store a copy of your IP address for the target machine in a variable. I stored my IP address in the variable IP_ADDRESS. In my case, the IP address I used was the IP address for my router with port forwarding enabled on port 22. For those not familiar with port forwarding, here is a helpful link.
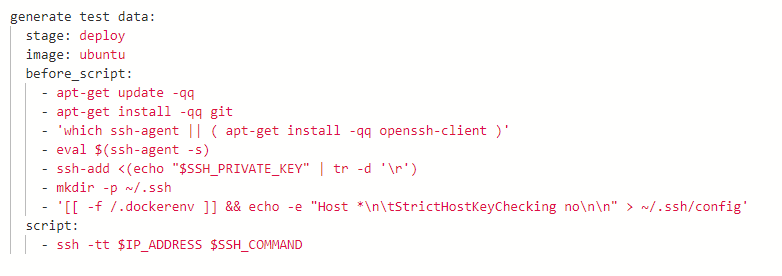
In the GitLab pipeline’s job called IRI script, an Ubuntu image has been set for the docker container. Before creating an SSH connection, OpenSSH Client is installed, an SSH agent is set up, and a private key has been added to the SSH agent. The GitLab runner can now SSH to the server.
The string value stored in SSH_COMMAND variable, looks something like this:
cd path/to/rowgen/job && rowgen_job.bat && cd path/to/fieldshield/job && sortcl.exe /spec=fieldshield_job.fcl
To generate test data for the test database, I used a RowGen job script. When executed via SSH command, the MEMBER_TB table present in the Amazon RDS instance is populated with synthetic test data.
For the sake of demonstration purposes, I also ran a FieldShield job script, via SSH commands, issued from within the GitLab CI/CD pipeline.
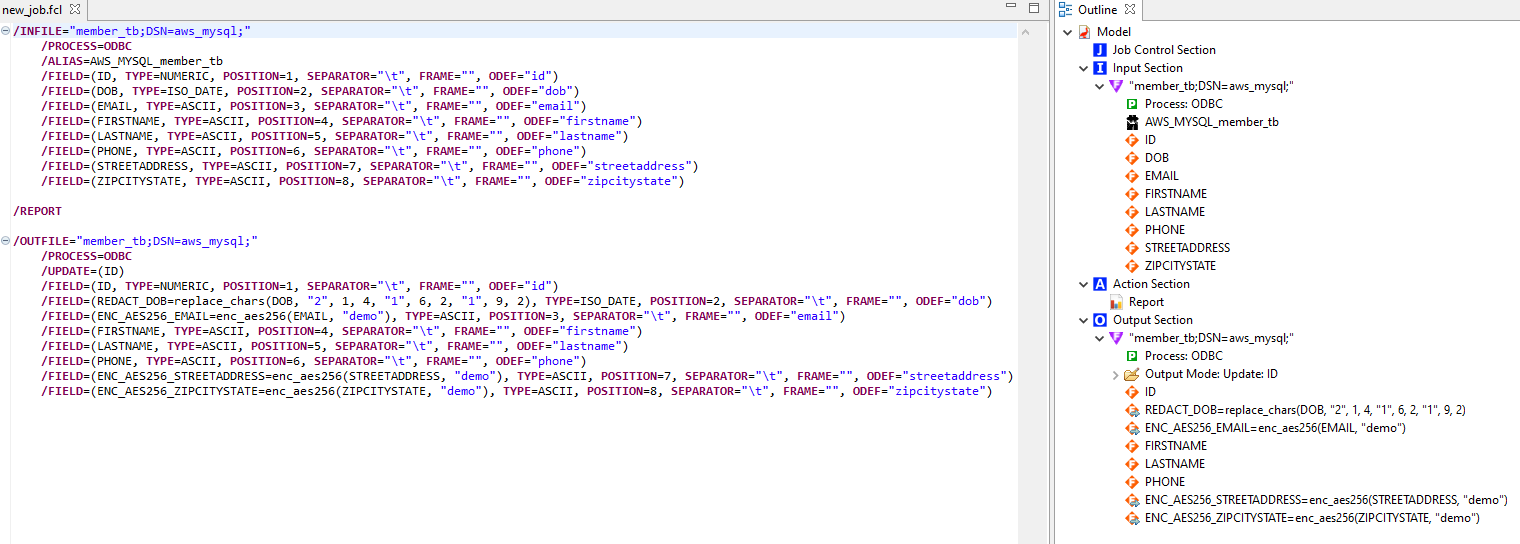
The FieldShield job accesses the MEMBER_TB table and masks sensitive fields that contain PII (DOB, EMAIL, STREETADDRESS, ZIPCITYSTATE).
You can verify that the IRI job scripts have generated data in your database, or from the IRI Workbench IDE, built on Eclipse™. Open your JDBC-connected schema in the Workbench Data Source Explorer view, and:
- Navigate down from the target Connection Profile (in my case “AWS MYSQL”).
- Find the target table in the target database (in my case “MEMBER_TB” in database “DATASOURCE1”).
- Right click the table you wish to use.
- Hover over Data and slide the mouse right.
- Click Sample Contents.
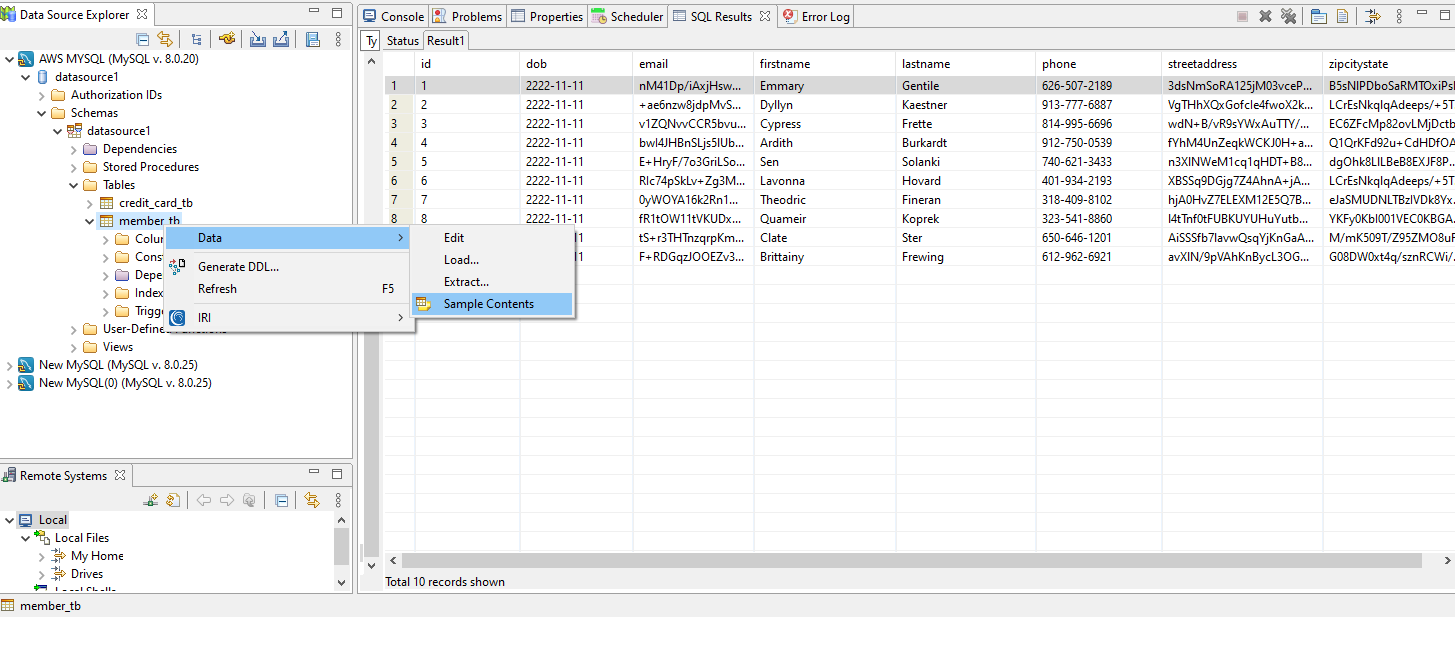
RowGen Test Data Synthesis Job
IRI provides easy-to-use end-user job wizards for RowGen that build the job scripts that will synthesize and populate test data. For my purposes, I used the New RowGen Database Test Data Job wizard.
Before using the wizard, I created a database connection using JDBC in the Workbench Data Source Explorer. After connecting to my database, I can select the MEMBER_TB table in the wizard. When advancing through the wizard, you will be presented with the New Field Rule Wizard Selection dialog box.
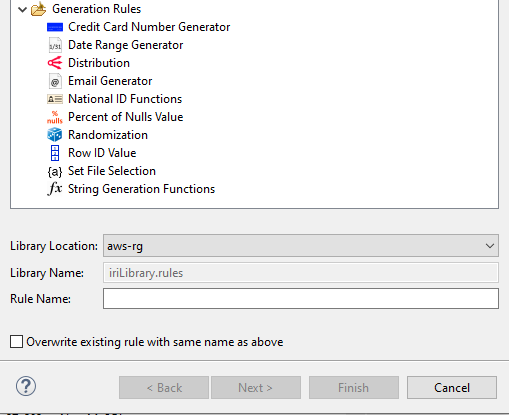
This dialog box allows users to choose from and create various field-level generation rules. For my MEMBER_TB table, I have the ID, FIRSTNAME, LASTNAME, EMAIL, PHONE, STREETADDRESS, ZIPCITYSTATE, and DOB fields.
For the DOB field, I used the Date Range Generator rule to create a list of randomly generated dates from a predetermined range of dates, to populate the DOB field.
Apart from the DOB field, all other fields use the Set File Selection rule to insert randomly selected data from set files included with my IRI software installation. Set files are collections of similarly grouped objects, with each object listed on a new line in the set file.
After completing the wizard, the necessary RowGen job script (.rcl) is created to specify the generation of test data for the MEMBER_TB table. A batch file is also created, which when run from either the GUI or command line, will execute the steps to synthesize the test data and populate the target(s).
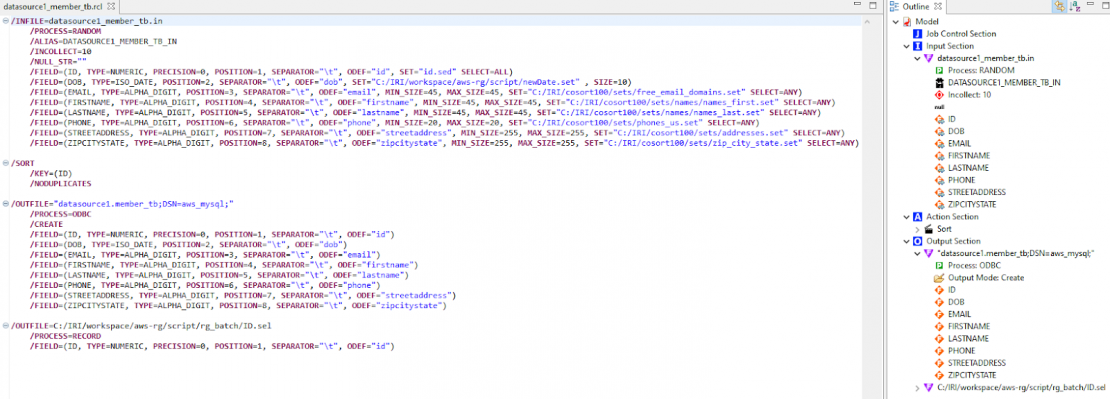
FieldShield Data Masking Job
For the sake of demonstration purposes, I also created a FieldShield job script that is executed when SSH commands are received from the GitLab pipeline.
Using FieldShield scripts, personally identifying information (PII) is masked at the field (column) level. Masking can occur on a production snapshot (as it’s built, ask IRI), or on-the-fly (ETL-style) as data are copied from production to the lower environment.
The IRI Workbench GUI for FieldShield has wizards that assist in the creation of FieldShield job scripts. I used the New Masking Job wizard to produce the necessary script (.fcl).
When proceeding through the wizard, you will need to specify an input datasource (ODBC), DSN, and the target table (MEMBER_TB) where the fields will be modified. Afterwards, the wizard will ask the user to add masking rules to individual columns using the New Field Rule Selection dialog box.
In my demonstration, I am using the Field Encryption rule to apply AES encryption to the EMAIL, STREETADDRESS, and ZIPCITYSTATE fields. Lastly, for the DOB field, I use the Redaction Function rule (though not the blur function is also popular for dates and ages).
After completing the wizard, the necessary script (.fcl) is created to specify the masking rules for the selected columns in the MEMBER_TB table.
Deployment Job Using AWS Elastic Beanstalk and S3
 Deploy Job
Deploy Job
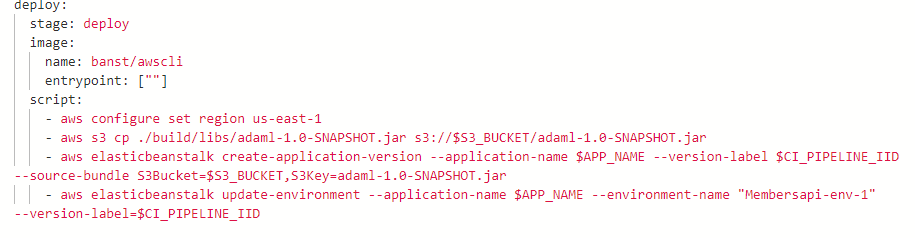
This pipeline job is called Deploy. It will configure the GitLab pipeline to deploy the application previously built in the Build job, to AWS Elastic Beanstalk.
After the application is deployed, we should be able to access the data in the test database DATASOURCE1, using the API endpoint Beanstalk provides. This endpoint will later be used in post-deployment testing, using Postman.
See this article for more information on how to deploy using AWS Elastic Beanstalk and S3 from the GitLab pipeline.
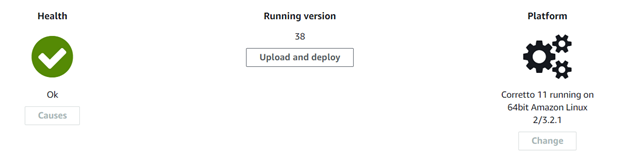 AWS Elastic Beanstalk environment management console.
AWS Elastic Beanstalk environment management console.
Post-Deploy Stage
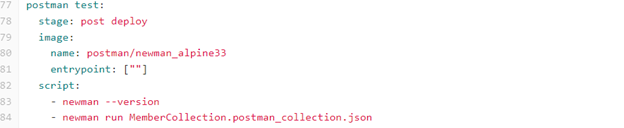 Post-Deploy Job
Post-Deploy Job
For those not familiar with using Postman in the GitLab pipeline, here is a helpful article.
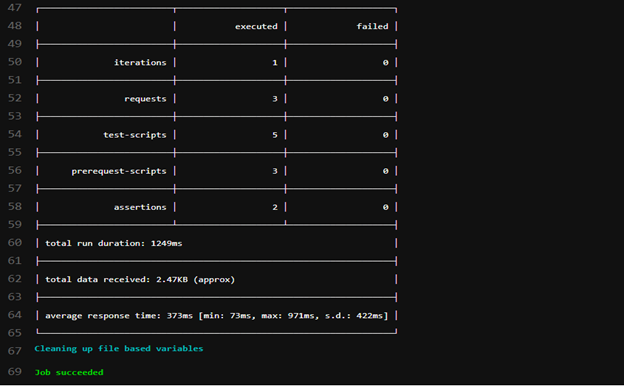 Output of Post-Deploy job log in GitLab.
Output of Post-Deploy job log in GitLab.
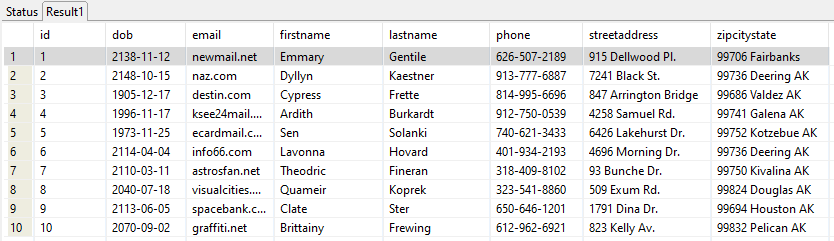
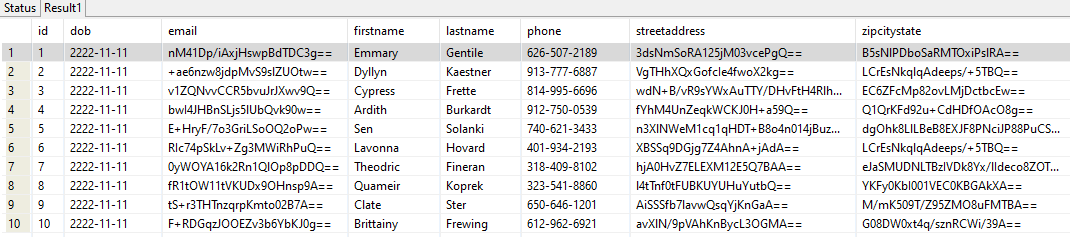
During the Postman tests, a GET request was made to the API hosted on Elastic Beanstalk. The API responded with the contents of the MEMBER_TB table in the test database DATASOURCE1. The MEMBER_TB table was not empty because the IRI job scripts had generated test data in the MEMBER_TB table before the Postman tests had begun.
Although I chose to use Postman to test my REST API, there are plenty of alternative tools out there based on your personal preferences.
JSON Response to GET Request to REST API Hosted on AWS Elastic Beanstalk
When the API deploys, the test data can be retrieved in JSON format when accessing the API endpoint (URL of server).
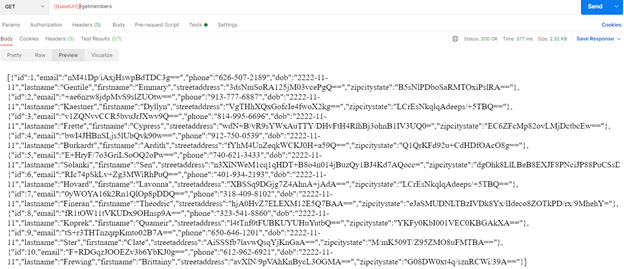 API response to GET request from Postman.
API response to GET request from Postman.
Procedural Summary
This article demonstrated how to automate the execution of IRI test-data-producing jobs from within a GitLab CI/CD pipeline. Using SSH, any IRI job scripts that can run via the command line can be executed from the pipeline.
IRI RowGen jobs synthesize test data while keeping real data out of non-secure environments. Alternatively, IRI FieldShield job scripts find and mask sensitive data at the field level, allowing a lot of real data copied from production environments to be used securely in test environments.
The IRI job scripts in this demonstration provided safe data for post-deployment testing. The API deployed in this demonstration would later retrieve these newly generated rows of data from the AWS test database (DATASOURCE1) as part of the testing process in post-deployment.
If GitLab is not for you, there are plenty of CI/CD pipeline alternatives that can execute IRI job scripts in a similar fashion. Although the syntax may differ slightly, Amazon CodePipeline, Azure DevOps, BitBucket Pipelines & Bamboo, CircleCI, GitHub Actions, Jenkins, and Travis CI pipelines all support SSH.
Automation in DevOps is motivated by the desire for consistency, speed, and reliability. The more that can be left to automation, the more productive testing can become.
- Massé, Nicolas. “5 Principles for Deploying Your API from a CI/CD Pipeline.” Red Hat Developer, 6 Aug. 2019, developers.redhat.com/blog/2019/07/26/5-principles-for-deploying-your-api-from-a-ci-cd-pipeline.
- Massé, Nicolas. “Full API Lifecycle Management: A Primer.” Red Hat Developer, 3 Sept. 2019, developers.redhat.com/blog/2019/02/25/full-api-lifecycle-management-a-primer.