Masked Test Data in an AWS CodePipeline
This article demonstrates how to automate the execution of IRI DarkShield data masking jobs from SSH commands run from within the AWS CodePipeline to produce fit-for-purpose test data in the DevOps process.
In my last demonstration with the GitLab pipeline, I ran structured IRI FieldShield data masking and IRI RowGen data synthesis job scripts to produce test data and consume them in API testing post-deployment. In this demonstration, the AWS CodePipeline will call the DarkShield-Files API on a remote server to showcase another method of creating fit-for-purpose test data in MongoDB. Of course, the GitLab method with FieldShield and RowGen, is viable in Jenkins and Azure DevOps, too.
About IRI DarkShield
DarkShield is a member data masking product in the IRI Data Protector Suite and included a component of the IRI Voracity data management platform. DarkShield focuses mostly on data in semi-structured and unstructured sources like: NoSQL DBs (including DynamoDB), PDFs, MS Word, text and image files (including Parquet and DICOM). DarkShield also finds and masks PII in flat files (local or stored in buckets like S3) and RDBs (usually with C/BLOB data).
About AWS CodePipeline and Its Structure
The Amazon Web Service CodePipeline is a continuous delivery service that automates the build, test, and deployment phases of new software releases. AWS CodePipeline also supports the integration of third-party services such as GitHub.
According to AWS documentation, “A pipeline is a workflow construct that describes how software changes go through a release process”1. The pipelines are made up of units called stages (build,test,deploy). Each stage in turn, is made up of sets of operations called actions.
The actions are configured to run at specific points in the pipeline. An example of an action would be a deployment action in a deployment stage that deploys code to a compute service.
Each action can be run in serial or parallel within a stage. The following are valid action types in CodePipeline:
- Source
- Build
- Test
- Deploy
- Approval
- Invoke
Each action type has an accepted set of providers. Each provider has a name that must be included in the Provider field in the action category of the pipeline.
The Source
For this demonstration my source will be from my GitHub repository. With that source, the AWS CodePipeline will utilize the buildspec.yml file stored in the repository and build the pipeline as dictated by the buildspec.yml file.
Conversely, I could have stored my buildspec.yml file in any number of places as a source. These include Amazon S3, Amazon ECR, CodeCommite, BitBucket, GitHub, and GitHub Enterprise Server actions.
Demonstration Prerequisites
- Your IRI software product is installed and licensed on the target remote server (the remote server that the CodePipeline will access via SSH could be your on-premise computer or somewhere on the cloud).
- The server where the IRI job script is located can be accessed with SSH.
- An AWS account (for my purposes the free tier was adequate).
- The environment variables to be used are stored in the AWS Parameter Store.
Setting Up the AWS CodePipeline Build Stage
The first part of my buildspec.yml file will be declaring my environment variables that are stored in my AWS Parameter Store within secure strings. I stored variables here to keep sensitive data like IP addresses, private keys, and ssh commands hidden.
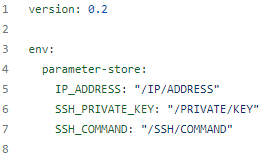 Setting up environment variables for buildspec.yml
Setting up environment variables for buildspec.yml
Alternatively, you could use the AWS Secret Manager Store, but unlike AWS Parameter Store, it will incur fees to store secrets in the Secret Manager Store.
 Parameter Store Environment Variables
Parameter Store Environment Variables
Before creating an SSH connection, an OpenSSH Client is installed, an SSH agent is set up, and a private key has been added to the SSH agent. AWS CodePipeline will now be able to SSH into the server where licensed IRI software is installed without requiring a password.
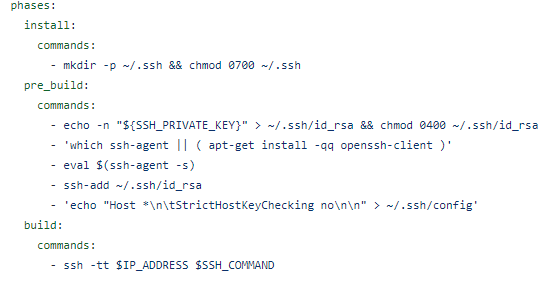 Setting up the build stage to execute SSH commands
Setting up the build stage to execute SSH commands
Executing the Build Stage to Generate Test Data
When the build stage is executed the string value stored in SSH_COMMAND will run the IRI job script on the server where the licensed IRI software is installed. After the build stage is finished AWS pipeline console will display a successful build message.
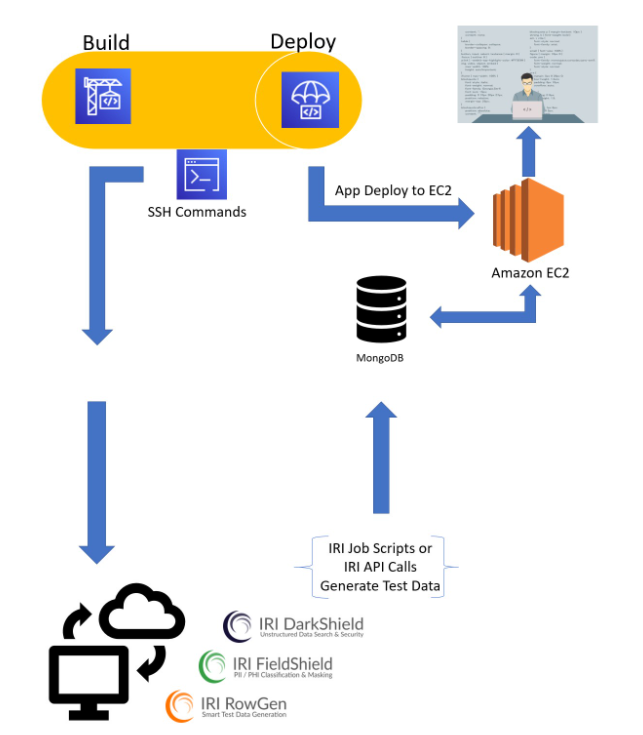
For my demonstration, I am executing a python script that will make a call like this to the DarkShield-Files API hosted on the remote server to search and mask JSON posts stored in a collection on a test MongoDB cluster hosted in AWS.
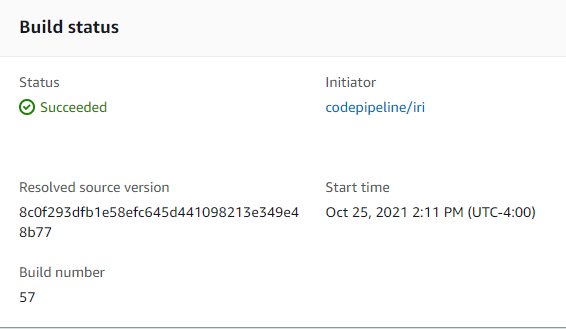 Build project Build status display
Build project Build status display
The log file created during the build stage will show that a connection to the remote server has been established, and that the DarkShield-Files API has been successfully called.

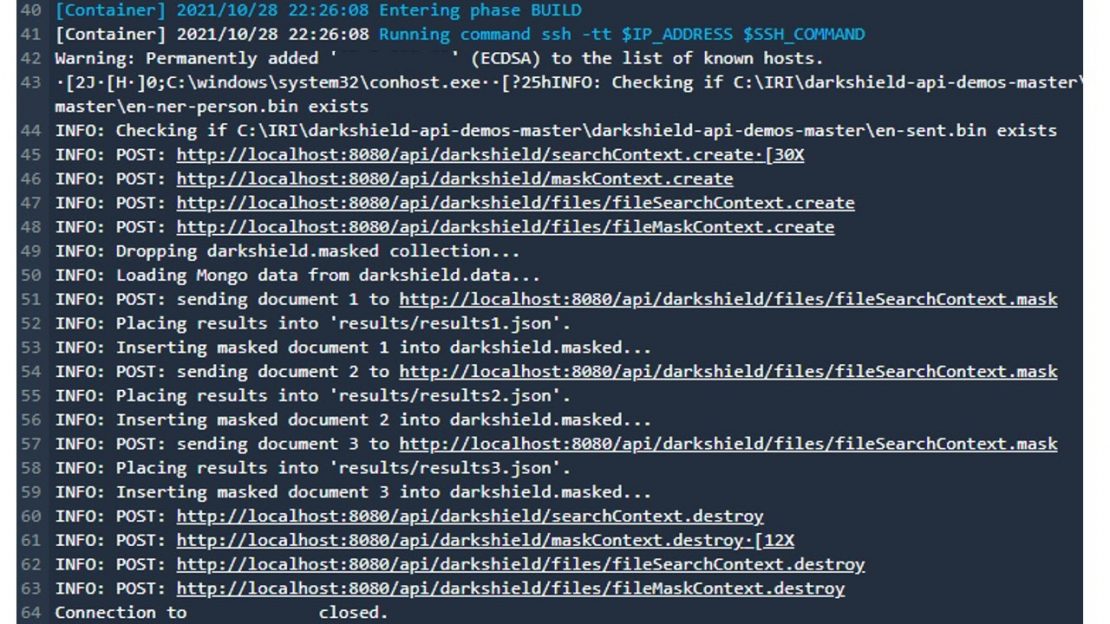 The build stage log output
The build stage log output
Results of DarkShield-Files API Call
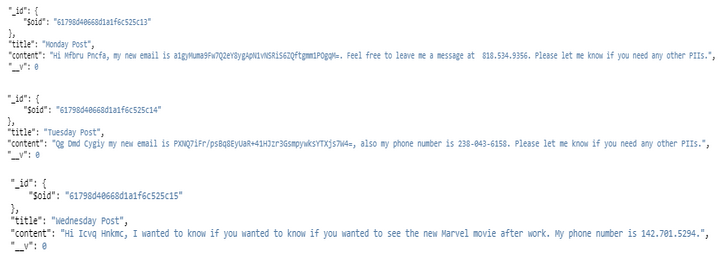
After searching and masking operations are completed, the masked files will be placed in the cloud MongoDB cluster in my collection called Posts.
 MongoDB documents in a collection before masking operation
MongoDB documents in a collection before masking operation
 MongoDB documents in a collection after masking operation
MongoDB documents in a collection after masking operation
What Can You Do With The Generated Test Data?
To provide an accurate assessment of how an application will behave during production, developers will usually require a test environment as close to the final production environment as possible. That said, test environments inevitably will not have the same level of security as the final production environment.
This is an issue when test data needs to be produced and later consumed during the testing process. Testers must make the choice between using a copy of sanitized production data or producing as realistic as possible, synthetic test data.
IRI offers several solutions for procuring safe to use test data. Earlier, I demonstrated how to mask sensitive data in MongoDB collections and produce safe to use test data via the AWS pipeline.
Below you can see a screenshot of a MEAN (MongoDB, Express.js, AngularJs, Node.js) stack app that is using the newly created test data. The app is able to create and store posts in MongoDB. Those posts are then retrieved from the database and displayed back to the user as accordion elements.
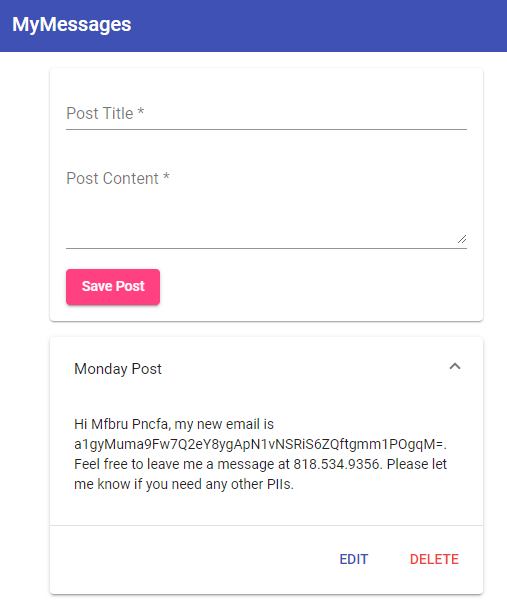
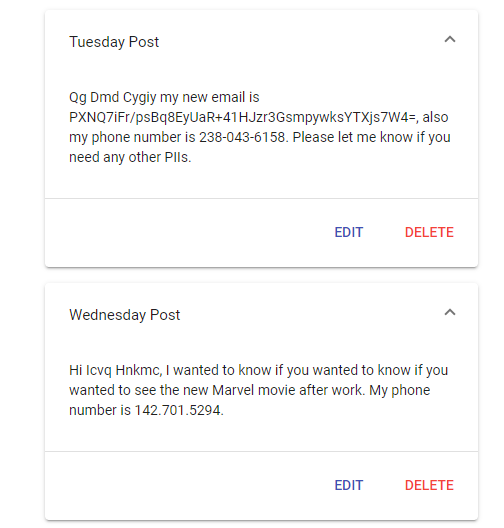
You will notice that no sensitive data has been revealed in this test environment.
AWS CodePipeline Building and Deploying Apps
In my demo I showed how to generate test data in the AWS pipeline using IRI DarkShield but the AWS pipeline is capable of far more. I would like to recommend an article written by Max A Raju, on building and deploying a MEAN stack app (MEAN stands for MongoDB, Express.js, AngularJS, Node.js) in the AWS CodePipeline.
For those not comfortable yet with AWS services like EC2, IAM permissions, or just CodePipeline in general, I highly recommend giving his article a read to better familiarize yourself with the process. As Raju points out, “there are quite a few steps involved in getting a pipeline up and running, but once set-up it is clearly a valuable workflow tool”2.
Procedural Summary
This article demonstrated how to automate the execution of IRI test-data-producing jobs from within the AWS CodePipeline. Using SSH, any IRI job script or API routine that can run from the command line can be executed from within the pipeline.
It is because the IRI back-end engine is an executable, products like DarkShield, FieldShield, and RowGen can be run from the command line. Furthermore, the DarkShield-Files API can be programmatically assigned to execute on preselected data sources as our python demos show.
Whether it is the generation of synthetic test data, the masking of structured data, semi-structured, or unstructured data, it is possible to incorporate IRI job scripts into the DevOps process through the CI/CD pipeline. My next article will demonstrate this in Azure DevOps.
- Codepipeline Concepts – AWS Codepipeline. https://docs.aws.amazon.com/codepipeline/latest/userguide/concepts.html
- Raju, Max A. “CI/CD with a Mean App on AWS Codepipeline.” Medium, Medium, 7 Sept. 2020, https://max-a-raju.medium.com/ci-cd-with-a-mean-app-on-aws-codepipeline-8d1954ce0ed










