
Connecting to 84 More Data Sources
Data architects and data scientists, as well as DBAs and governance teams, may need to use or migrate data in legacy file formats and databases. Additionally, the ability to mash-up those sources with newer file and database repositories is important in data integration (ETL) and analytic projects, as well as in data profiling for data loss prevention and privacy law compliance.
Users of IRI CoSort (data transformation and reporting), IRI NextForm (data migration and replication), and IRI FieldShield (data masking) software, have traditionally acquired and manipulated data in structured (flat) files and relational databases. Recent support has been added in the IRI Workbench (Eclipse) GUI for unstructured sources and Micro Focus COBOL index files.
Through a new partnership with CONNX Solutions, IRI Workbench users can use specialized ODBC and JDCB drivers to access and view data in legacy formats like Adabas, Datacom, IDMS, Model 204, and Pick. Connections to these sources not only expand solution reach for IRI users, they eliminate the need to assign more resources to the problem of unlocking esoteric data.
Below is the updated list of supported data sources for those using IRI software. Parentheses denote integration of the IRI Workbench GUI or other dependencies for reaching the data. Italics indicate sources requiring CONNX driver installation.
| Access | D3 | IDMS | MyBase | Reality/X |
| Acucobol Vision | Datacom | IDS | MySQL | RRDS |
| Adabas | Dataflex | IDX 3, 4 & 8 | Netezza | RTF (WB) |
| Adabas D | Db4o | Image | NonStop SQL | SAP Hana |
| Advanced Pick | dBase | IMS | ObjectStore | Sequoia |
| ALLBASE | Delimited | Informix | Oracle | Sharebase |
| Altibase (FACT) | Derby (WB) | Ingres | Outlook (WB) | SQL Anywhere |
| Alpha Five | Desktop Adapter | InterBase | Paradox | SQL Server |
| Amazon RDS | DL/1 | Intersystems Cache | Pathway | SQLite |
| ASN.1 TAP 3 | DSM | ISM | PDF (WB) | Supra |
| Azure | Enscribe | Jasmine | PDS | Sybase ASA/E & IQ |
| BIRT DB (WB) | Enterprise Adapter | jBase | PervasiveSQL | Terracotta |
| BIRT Hive (WB) | ESDS | K-ISAM | Pick | Teradata (WB) |
| BIRT JDBC (WB) | Excel (WB) | Knowledgeman | Pick64+ | Text |
| BIRT POJO (WB) | ELF web logs | KSDS | Pl-Open | Tibero (FACT) |
| BizTalk | FileMaker | LDIF | PostgreSQL | Total |
| Cache | Firebird | Line Sequential | Powerflex | Ultimate |
| C-ISAM | Fixed | Lotus Approach | Powerhouse | UltPlus |
| CLF web logs | Flat Files | Lotus Notes | PowerPoint (WB) | UniData |
| Clipper | Focus | Manman | Progress | UniVerse |
| Codasyl | FoxPro | Max DB | QueryObject | UTF-8 |
| Corvision | GA-Power 95, R91 | Mentor/pro | rBase | UTF-8 |
| ConceptBase | Gemstone | MF-ISAM | R83 | VSAM |
| CSV | GENESIS | MF Var. Length | Rdb | VSAM-MVS (Unikix) |
| DB2 (UDB) | Gigabase | MO | REALITY | VSAM-VSE |
| DB2 for i5/OS (WB) | H2 | Model 204 | Record Sequential | Web Services (WB) |
| DB2 for z/OS (WB) | Heap / print | MongoDB (WB) | Red Brick | Word (WB) |
| D-ISAM | HSQLDB (WB) | Mumps | RMS | XML |
The procedure for connecting to a non-native database in the IRI Workbench involves installing CONNX software and drivers. After a data dictionary file is created in the CONNX software, that file is then used in the Workbench with the CONNX driver as a data source. Following our user guide, setup can take as little as 20 minutes.
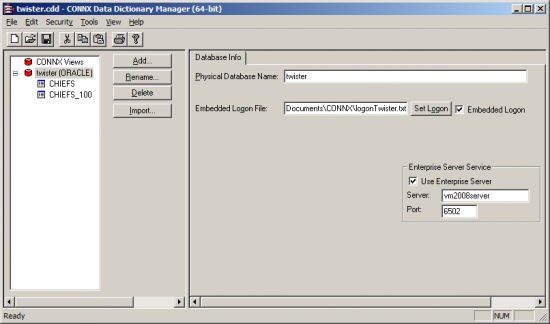
In the Workbench, the data source name (DSN) is available (as any native DSN would be) and displays in the lower left area of the Data Source Explorer workspace. This enables the use of that data (and its metadata) throughout the IRI Workbench environment.
Consider the following IRI CoSort (SortCL program) example; the script created in the new sort job wizard will use the connection to define the reordering of the ‘Customers’ table in a mainframe C-ISAM repository by zip code:
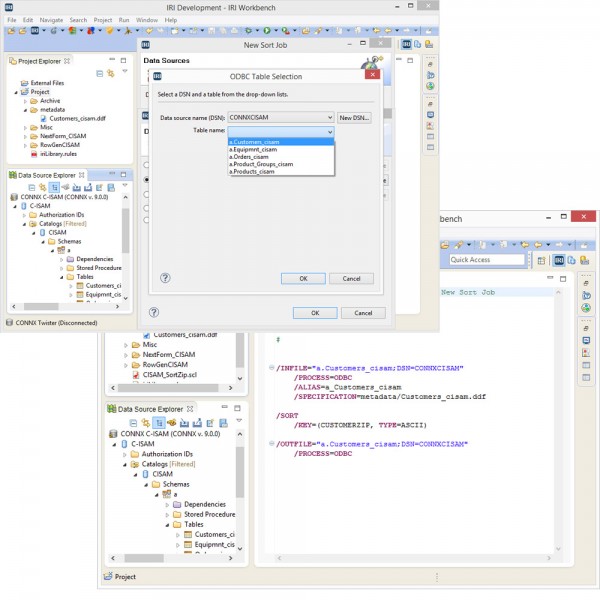 In this next example, IRI NextForm remaps data in multiple C-ISAM files (reflected as ODBC-connected DB tables) using a common mapping rule:
In this next example, IRI NextForm remaps data in multiple C-ISAM files (reflected as ODBC-connected DB tables) using a common mapping rule:
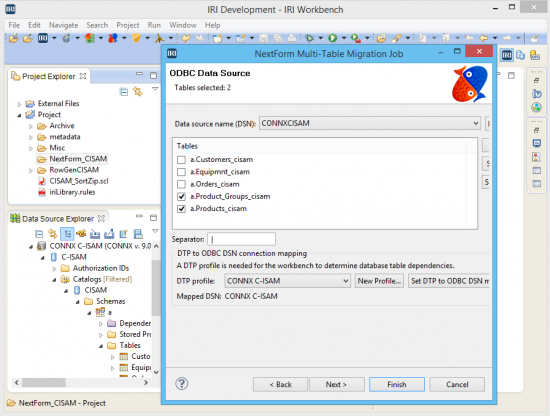
When the job wizard is complete, a portable job script is produced, and the script can be run from the GUI (or on the command line) to perform the specified migration:
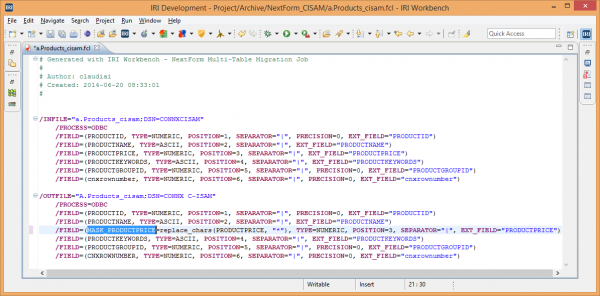
In this same environment, data can be migrated, transformed, masked, etc., for whatever the needs may be and the licenses allow. The ability to successfully access a large variety of structured, semi-structured, and unstructured data sources demonstrates IRI’s congruent commitment to supporting both legacy systems and emerging platforms.











1 COMMENT
I’m interested in the unstructured (dark data) sources. Do you need special drivers for those, or is the data restructuring wizard mentioned in the other articles all I’d need for that?