What is Unicode?
 Unicode began as a project in 1987 between Apple and Xerox engineers in response to a need for an international standard of representation for every character in all major languages of the world. As the exchange of information and data became more prevalent electronically and internationally, there was a need for a unified code that could be read on any platform running any program. Prior to the development of Unicode, the primary ASCII coding scheme which used an 8-bit character representation only allowed for 256 characters.
Unicode began as a project in 1987 between Apple and Xerox engineers in response to a need for an international standard of representation for every character in all major languages of the world. As the exchange of information and data became more prevalent electronically and internationally, there was a need for a unified code that could be read on any platform running any program. Prior to the development of Unicode, the primary ASCII coding scheme which used an 8-bit character representation only allowed for 256 characters.
These early Unicode pioneers discovered that there were about 27,000 characters in the modern world and this resulted in a 16-bit fixed length character code which allowed for 65,000 characters, enough even for future expansion. Joe Becker, one of the Xerox engineers, coined the term Unicode from their requirements for a universal, uniform, and unique bit sequence to represent characters.
The initial success of Unicode naturally relied on its adoption by other companies. Early in its development, major computer manufacturers, networking and software companies began making significant contributions to the design. In addition to Xerox and Apple, participating companies included Metaphor, Claris, Research Libraries Group, Sun, Microsoft, SHARE, IBM, Pacific Rim, Aldus, NeXT, and Novell.
By 1991, Unicode, Inc. was incorporated with the original purpose to standardize, extend, and promote the Unicode character encoding. The original release date of Unicode was in October of that year. Version 1.0.0 contained codes for 7,161 characters. The most recent version, 6.0.0, was released in October 2010 and provided codes for 109,449 characters from the world’s alphabets, ideograph sets, and symbol collections.
IRI first began developing support for Unicode data in CoSort Version 7.5. But with the release of CoSort 9.5 there was a major re-design necessary to support the updates in characters that occurred.
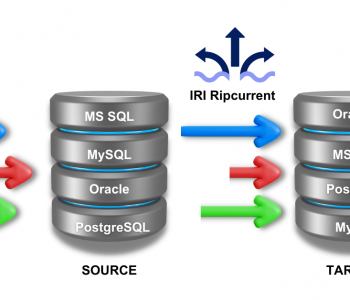
CoSort’s Sort Control Language (SortCL) program supports Unicode files and fields which may be mapped to database tables. SortCL can collate (sort), merge, join or convert Unicode characters and numerals in delimited or fixed-position fields.
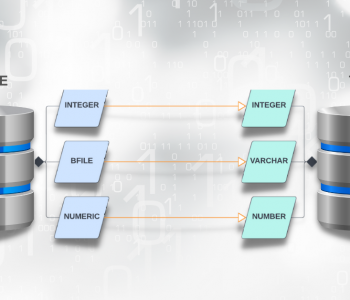
Conversion between Unicode and single-byte (e.g. ASCII) or native multi-byte characters (e.g. Chinese GBK/Big5, Japanese, and Korean) is supported. Conversion between a variety of numeric data formats and Unicode digits is supported in both CoSort (SortCL) and NextForm, IRI’s standalone data migration package.