
Data Class & Rule Library in IRI Workbench
Abstract: HIPAA, GDPR, FERPA, and other data privacy laws require that personally identifiable information (PII) and related data considered sensitive be protected from disclosure or discovery. A list of sensitive items made up of PII can be abstracted into easy-to-understand groups – what IRI calls Data Classes – to produce groupings of PII such as emails, names, phone numbers, etc.
In this article, Data Classes and the Data Class & Rule Library are discussed in depth. It covers how Data Classes and (data masking) Rules are defined and stored inside the IRI Workbench Data Class & Rules Library. Once inside, that information can be accessed by IRI Voracity job-building wizards for NextForm, FACT , RowGen, FieldShield, and DarkShield — as well as the FieldShield Schema Data Class Search or Directory Data Class Search wizards.
Note that a Data Class & Rules Library is different from a Data Class Map, which would be the final product of a Schema Data Class Search or Directory Data Class Search wizard. Those wizards use a Data Class & Rules Library to perform data classification and produce a Data Class Map containing mappings of rules to fields in structured targets.
Editors Note: The information in this article supersedes earlier documentation on data class creation in IRI Workbench versions downloaded prior to December 2023 and that an upcoming article covers auto-migration of your data classes and masking rules to the new, improved framework described herein.
What is Data Classification?
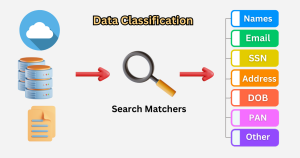
Depending on who you ask, the meaning of data classification may differ. At IRI, data classification refers to the act of cataloging and defining specific types of data – like email addresses, ID numbers, and company names – into unique, abstract categories of data called Data Classes, based on certain attributes or traits.
IRI Data Class and Rule Library
IRI Data Classes and IRI Rules are stored in a file called IRI Data Class and Rule Library.
IRI Data Class (& Rules) Library Form Editor
Every new IRI Project produced in IRI Workbench comes with an empty Data Class and Rule Library with a file extension of .dcrlib. This library is where Data Classes and Rules are created and stored.
Every FieldShield Job and DarkShield Job requires at least one Data Class to be present in a project’s IRI Data Class and Rules Library. To create, edit, and remove Data Classes and Rules, you must use the IRI Library Form Editor. The IRI Library Form Editor provides a non-modal graphical user interface that allows for the configuration of the IRI Data Class and Rules Library.
To open the IRI Library Form Editor, double-click on the iriLibrary.dcrlib file inside your project folder. This in turn opens the respective form editor attached to the iriLibrary.dcrlib file inside Workbench as a non-modal wizard page.
In the form editor, you can add Data Class Groups, Data Classes and their associated Search Matchers and default Rule, and also Rules not associated with any of the Data Classes. These unassigned Rules can later be used to overwrite the default Rule assigned to each Data Class.
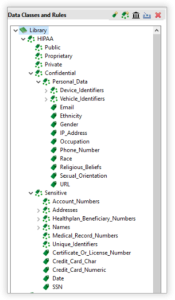
Data Classes
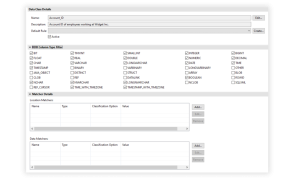
Data Classes provide convenience, consistency, and the ability to support the needs of data architects and governance teams by providing a more granular level of control on what is considered, discovered, and treated as PII. Data Classes consist of Search Matchers, a default Rule, and RDB Column Type filters (only applicable to Relational Databases).
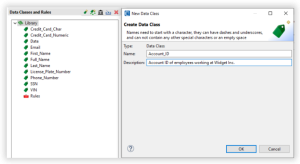
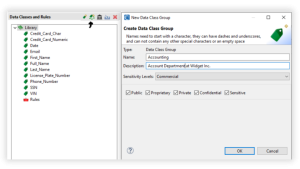
By default when a new IRI Project is created a Data Class Rules Library comes preloaded with several Data Classes with some default Rules assigned. To add a new Data Class to the library, double click the green tag 
Note that there can not be multiple Data Classes with the same name. Click Ok and a new Data Class should populate the library.
For example:
 Data Class Groups
Data Class Groups
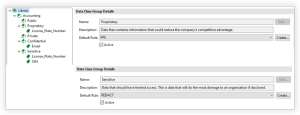
A Data Class Group is a container for a group of data classes. Each Data Class Group can have a default Rule assigned by the user.
By assigning a default Rule to a Data Class Group, any Data Classes within a Data Class Group that have no default Rule assigned will instead inherit the default Rule of the parent Data Class Group. Otherwise, if the Data Class in a Group has a default Rule, that Rule will be used instead of the Data Class Group’s default Rule. Grouping Data Classes together can also be useful for categorization and logging purposes.
Another optional feature of Data Class Groups is the ability to further categorize Data Classes according to their level of sensitivity. Sensitivity level groups are Data Class Groups with an assigned priority level. Higher priority groups typically have more restrictive masking functions assigned to them.
Because only one Data Class can be matched to a given element of PII, the sensitivity level of a Data Class Group determines the order in which a Data Class that may be in a different group (using different masking rules) can perform its matching and masking operation against incoming data. Where two Data Classes with the same name and search matchers but different masking functions are defined, the sensitivity level should dictate which masking function takes priority.
In the example below, the License_Plate_Number data class might be found in both Proprietary and Sensitive groups. Sensitive is the higher priority sensitivity level group, so in this case the redaction rule would be applied even though the License_Plate_Number was also part of the Proprietary group which had a default encryption rule assigned.
To create a Data Class Group, double click on the multi green tag 
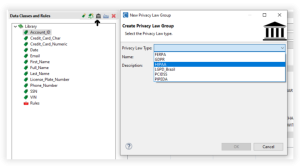
Privacy Law Associated Data Class Groups
Privacy Law Groups are pre-populated Data Class Groups that provide a launching board for business rules to adhere to different privacy law requirements. These privacy law groups have pre-populated data classes, search matchers, and masking functions.
Note however that these specifications are provided for convenience, and may or may not identify every element or conform to specific data protection requirements.
Review and customization of these objects is therefore recommended to assure your job settings will address your particular needs.
To create a Privacy Law Group double click the courthouse 
Search Matchers
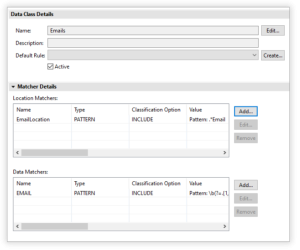
Currently, Search Matchers can be divided into two sub-categories: Location Matchers and Data Matchers. Location Matchers apply strictly to structured and semi-structured data and inspect the structure of data. Data matchers on the other hand, directly inspect the contents of data to determine if they match the specified search attributes of the data class.
As a general rule, Location Matchers have better performance during matching operations and have better accuracy. The caveat is that Location Matchers are not available when working with unstructured data, since Location Matchers rely on a predefined structure to match on PII.
Unlike Location Matchers, Data Matchers can be used for matching against structured, semi-structured, and unstructured data. Data Matchers are very useful when PII can be found in free floating text. This includes but is not limited to, text files, Word documents, PDFs, images, and PowerPoint slides.
By using both location and data matchers simultaneously, you can find PII in your data source(s) by either source structure or data format. Note as well that you can also use more than one location matcher and data matcher at the same time for even more certainty, but the more matching attempts you specify, the longer data discovery can take. Without at least one Search Matcher, no matches will be found, and no grouping of data classes can occur.
The IRI Library form editor provides a section called Matcher Details which allows for the adding, editing, and removal of Search Matchers from individual Data Classes. Currently, Search Matchers are divided into two sub-categories: Location Matchers and Data Matchers.
The Matcher Details section supports the creation of multiple Location and Data Matchers.
Below are links to articles that discuss Location Matchers and Data Matchers in more depth, including how each are specified:
Data Class Default Rule
Any Data Class can store a default rule. A default rule is usually a masking function that will be applied by default to a Data Class if no Rule has been assigned. This is done to assure there is at least a base level of protection assigned to a Data Class if this is a Data Class with sensitive PII.
To create a default rule, select the Create… button to the right of the Default Rule label and a dialog will appear. There are three major types of rules: Data, Quality, and Section. Data rules is the most common type, and are used for data masking. At the top of the dialog, there is a filter section to expose masking rules which only relate to DarkShield.
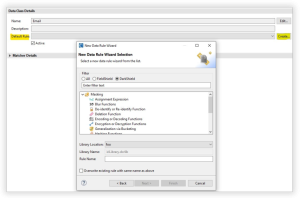
Once a rule is created, select the drop-down menu next to the Default Rule label and select a rule to be the default for that data class.

Rules Library
In addition to the default rule inside a Data Class, some rules can exist without being assigned to a Data Class during its creation. These unassigned rules are stored in a sub-library called the Rules Library.
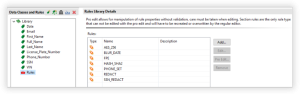
The rules in a Rules Library are available during the creation of an IRI job, and allow for the overriding of the default rule assigned to a data class if your application requires that. To access the Rules Library from the IRI Library Editor, click on the red toolbox next to the words “Rules”.
A view of current existing rules will be displayed in the editor. From the editor, we should also be able to add, modify, or remove rules as needed.
Rule Pro Edit
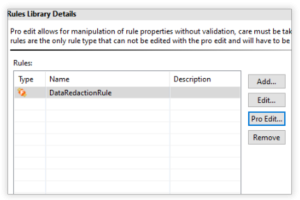
The Pro Edit option in the Rule Library editor allows for manual modification of Rules without the need to go through a wizard for that. This option helps those with advanced knowledge and the need for more freedom in alteration, like adding additional properties to a rule.
One example use might be changing the data type in a target column (within a FieldShield job script). Clicking Pro Edit opens a page for editing a rule’s properties.
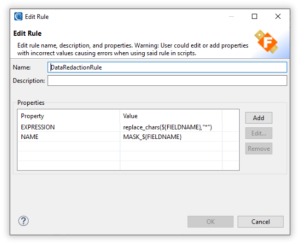
From this page, Rule properties can be added, modified, or removed. Pro Editor also allows you to change or add properties that you couldn’t through the standard creation of rules.
Example 1) I can add a property that changes the data type of a field when we generate SortCL job (e.g., FieldShield data masking) scripts.
Example 2) In the image I can edit the expression to use an if then else statement and it will generate it in job scripts automatically.
Using this wizard requires knowledge of IRI data rules and their possible properties. That said, all IRI rule properties and expressions are documented SortCL program options in the CoSort manual.
Re-Using and Sharing Data Classes and Rules
Once your data classes and rules are defined in a iriLibrary.dcrlib within your project, you can re-use the same information in other projects. To do that, simply copy this file into additional projects.
In this way, you can apply the same masking rules to like data classes you encounter in different projects. And remember, it is the consistent application of the same deterministic masking rule to the same data classes that preserves referential integrity in your targets.
Note too that some of the new job wizards, particularly those in DarkShield, allow you to specify a particular library even from another project folder. This means copying the library would not be necessary.
Re-using data classes and rules is particularly useful in IRI FieldShield data discovery and masking projects that are defined for different schemas. This is because database test data consumers need each unique original value masked the same way across multiple lower environments.
Library re-use is also useful in multiple IRI DarkShield projects built with its different search and mask wizards for files, healthcare documents, relational and NoSQL databases. This again is because enterprises with sensitive data in heterogenous sources also need consistently masked values.
Sharing these libraries is also desirable for IRI software users who need to re-use the same rules in their own Workbench workspace. In a less formal, non-governed environment, you can create one or more library files with a .dcrllib extension and send them as needed as you would any other file.
A better practice would be to share these files along with other applicable and permissible project artifacts through a secure repository integrated with IRI Workbench such as Git. See this article on sharing IRI data management jobs to fully understand and implement this approach.
Import From Old Data Class Library and Rules Library

Before the Data Class and Rule Library (.dcrlib) was supported in IRI Workbench there were predecessor libraries called the Data Class Library and the Rules Library. With breaking changes to updates to IRI Workbench and new features added, the old libraries became unusable. As such users needed a way to make the transition from older versions to new ones without having to completely throw out their previous work.
The Data Class and Rules Library now supports the import and conversion of content from the older versions of the Data Class Library and Rules Library:
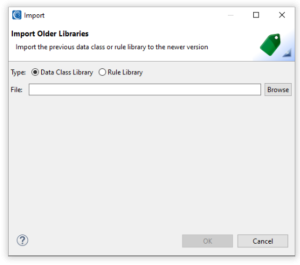
Documentation of this functionality is available in this article.










