
Big Data Redaction
As data volumes available for research, resting, data science projects, and AI models continue to grow, so does the urgency to protect sensitive information they contain from exposure. Whether you’re dealing with billions of database transactions, massive log files, or terabytes of archived documents, managing privacy at scale requires more than just manual effort or ad hoc tools. That’s where big data masking tools like IRI DarkShield come into play..
Built for large-scale data privacy protection, DarkShield offers a powerful solution for classifying, locating, and redacting personally identifiable information (PII) and other sensitive data across massive, diverse repositories. But how does it actually scale? And why does that matter?
In this article, we’ll explore the growing need for redaction at scale, how DarkShield addresses the challenge, and what sets it apart from other data masking tools.
What Is Data Redaction and Why Is It Critical?

Data redaction is the process of obscuring or removing sensitive information from documents and data sources, so that unauthorized users can’t view it. This is different from deletion—obfuscated content may still be present, but has been masked or otherwise rendered unreadable or irreversible.
Redaction is essential for:
- Meeting regulatory requirements like GDPR, HIPAA, and CCPA
- Protecting customer trust
- Securing intellectual property and proprietary data
- Safeguarding machine learning and analytics pipelines from bias or exposure
For organizations working with massive unstructured data stores, spreadsheets, and files in various formats, traditional data redaction tools often fall short. That’s where IRIDarkShield steps in—with purpose-built features designed for big data protection and scalable data masking workflows.
Why Big Data Needs Masking
When you’re managing large volumes of data, performance, accuracy, and flexibility matter. Let’s explore how big data masking and redaction go hand in hand—especially when the stakes are high.
Imagine an enterprise that needs to redact PII from over 10 million archived customer support tickets. Doing this manually or with a lightweight tool would take months, possibly years, and introduce massive risk. DarkShield enables the same organization to automate redaction, ensure consistency, and generate audit trails to demonstrate compliance.
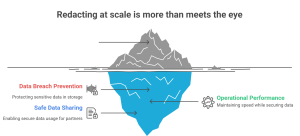
Redacting at scale also means:
- Avoiding data breaches in backup or cloud storage
- Preserving operational performance while securing sensitive data
- Enabling safe data sharing for AI, analytics, and third-party partners
The IRI DarkShield data masking tool addresses these concerns with optimized engines and parallel processing, making it one of the most scalable data privacy tools available.
DarkShield: A Redaction Engine Built for Scale
IRI DarkShield is part of the broader IRI Data Protector Suite and offers robust static data masking functionality. It’s engineered to redact sensitive content from structured, semi-structured, and unstructured files—regardless of volume or format.
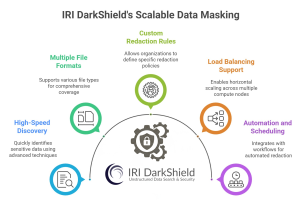
Here’s how it works at scale:
1. High-Speed Discovery
DarkShield utilizes pattern matching, keyword dictionaries, natural language processing (NLP), and machine learning to scan and detect sensitive data across millions of files in real-time. From names and social security numbers to medical codes and financial data, it quickly identifies what needs to be redacted.
2. Support for Multiple File Formats
Whether it’s Parquet files, PDFs, Word documents, Excel spreadsheets, JSON, XML, EDI, image or log files, DarkShield’s multi-source, multi-format support ensures full coverage. It can scan vast repositories in on-premise, cloud, or hybrid environments.
3. Custom Redaction Rules
Organizations can define their own redaction rules, including masking formats, regex patterns, or dictionary values, and apply them at scale across multiple systems. This enables granular control over how sensitive data is treated.
4. Load Balancing Support
Developers interested in scaling search/mask jobs horizontally across multiple compute nodes and leveraging the DarkShield REST API. The single-endpoint Java API supports integration with load-balancing technologies like NGINX and Hadoop.
5. Automation and Scheduling
You don’t have to run jobs manually. With a built-in task scheduler in IRI Workbench, or CLI support for external automation tools, DarkShield can run redaction jobs as part of larger ETL, backup, or file archival workflows—making it ideal for ongoing compliance processes.
Use Cases: Where Redaction at Scale Is a Game-Changer
1. Healthcare Providers
Hospitals and clinics often store patient records, lab results, and prescriptions in multiple formats. DarkShield enables rapid redaction of PHI to meet HIPAA compliance requirements without compromising data usability for research or reporting.
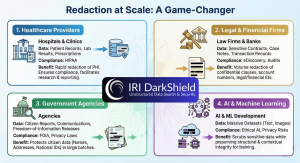
2. Legal and Financial Firms
Law firms and banks deal with a constant stream of sensitive contracts, case notes, and transaction records. DarkShield helps redact confidential clauses, account numbers, and other legal or financial identifiers at volume—especially during eDiscovery and audits.
3. Government Agencies
Agencies need to protect citizen data when releasing information under freedom-of-information laws. Redaction at scale ensures that names, addresses, and national ID numbers are masked in large batches of reports and communications.
4. AI and Machine Learning
Sensitive text or image data must be cleaned before training AI models. DarkShield helps scrub massive datasets while preserving structural and contextual integrity—ensuring ethical AI without privacy risks.
Integrating DarkShield with Your Data Ecosystem
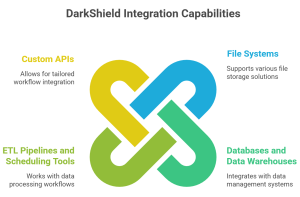
One of the major benefits of DarkShield is its ability to integrate seamlessly with enterprise ecosystems. It works with:
- File systems (local, cloud, Hadoop, Azure, S3, etc.)
- Databases and data warehouses
- ETL pipelines and scheduling tools
- Custom APIs for workflow integration
This makes it not just a redaction utility but a strategic component of your data privacy and compliance tools stack—ready to fit into DevOps, research, demo/marketing, or analytic and AI processes.
FAQs: Redaction at Scale with DarkShield
Q1. How is redaction different from deletion or encryption?
Redaction hides sensitive data (e.g., with masking characters) so it’s unreadable to unauthorized users, but the structure remains intact. Deletion removes data entirely, while encryption secures it with cryptographic keys. Redaction is useful for sharing or archiving data safely.
Q2. Can DarkShield redact data from image files or scanned documents?
Yes, with OCR (Optical Character Recognition) capabilities, DarkShield can extract and redact sensitive text from image-based formats like scanned PDFs or TIFFs.
Q3. Is DarkShield compliant with regulations like GDPR or HIPAA?
Yes, DarkShield is designed to support compliance with global privacy laws including GDPR, HIPAA, CPRA, KVKK, LGPD, PIPEDA, and more. Its audit trails and rule-based redaction make it ideal for regulated industries.
Q4. Can redaction processes be scheduled or automated?
Absolutely. DarkShield supports job scheduling and API integration for automation, enabling continuous redaction workflows with minimal manual intervention.
Final Thoughts
Privacy compliance at scale is one of the toughest challenges facing modern enterprises. Whether you’re protecting millions of medical records or archiving vast customer datasets, the need for reliable, high-performance data redaction tools is more urgent than ever.
The IRI DarkShield data masking tool consolidates the best of big data classification, masking, automation, and integration flexibility. With it, you can enforce privacy controls confidently, stay compliant, and protect your brand reputation—no matter how large your data estate becomes.
So, if your organization is looking for scalable, efficient, and auditable redaction capabilities, IRI DarkShield should be at the top of your list.










