
Getting Started with IRI Ripcurrent
Abstract: Data collected, processed, and saved across industries is constantly generated and updated. Database (DB) tables can be refreshed with new data from applications or events in intervals as frequent as a fraction of a second. With this in mind, IRI developed Ripcurrent as an adjunct feature in Voracity for real-time data replication to monitor, refresh and mask DB data that changes in real-time.
Editors Note: You can read the press release introducing Ripcurrent here.
What is Ripcurrent?
Ripcurrent is the name of an IRI-developed Java application included in the Voracity data management platform that combines the Debezium embedded engine with the streaming feature of the IRI (CoSort) SortCL program to react in real-time to DB change events by replicating data to downstream target(s), optionally with transformation (e.g., PII masking) rules consistently applied based on your classification of the data.
Ripcurrent integrates with Debezium to track changes from several different DBs. Ripcurrent bundles Debezium connectors for MySQL, SQL Server, PostgreSQL, and Oracle. Debezium may eventually also support MongoDB, DB2 and Vitess, but more work is required.
Ripcurrent automatically triggers SortCL to take action on data in an inserted, updated, or deleted row. This can keep a set of equivalent targets (likely in a lower environment) in sync with source tables, and optionally apply consistent field-level transforms (like PII-classified masking) to the data.
Ripcurrent is a seamless analog to this approach for processing changes to flat files in real time, and an alternative to this approach for moving and masking changed DB data incrementally.
This diagram shows the approach Ripcurrent takes for supported DB sources:
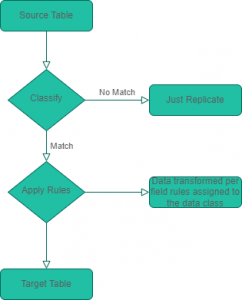
How Ripcurrent replicates data in real-time from a source table to a target
Ripcurrent can detect changes for every row insertion, update, or delete in all tables in a DB, excluding any tables or schemas that have been filtered out based on the configuration properties passed to Ripcurrent.
Additionally, other DB change events like the change of the structure of a table are monitored and recorded by Ripcurrent. However, only DB change events that involve the modification, addition, or deletion of data in a table trigger Ripcurrent to take action on that event.
Why Use Ripcurrent?
The ability to replicate and/or mask data in DB tables to other DB tables or files has long been supported by IRI software. This is commonly done through IRI Workbench, the graphical user interface for all IRI (structured) data management products.
The Schema Data Class Job wizard in IRI Workbench – where data in a schema are searched and grouped into data classes – can be paired with masking rules. A batch file or shell script is generated from the wizard to execute bulk masking operations defined in FieldShield scripts.
However, if there are any changes to the DB, there is no easy way to replicate the changes without running the batch/shell script again. And, if there were any additional tables added to the DB or new columns added to existing tables, those will be ignored unless the wizard is run again to generate a new batch/shell script and the relevant FieldShield scripts for the operation.
The need to keep in sync with DB changes is the motivation for the development of IRI Ripcurrent. For those who want to keep the downstream target(s) in-sync with a source DB, perhaps for testing, Ripcurrent provides the functionality of a Data Class DB Masking Job, but in a dynamic fashion. In other words, Ripcurrent enables real-time data masking.
Ripcurrent Prerequisites
If duplicating data to tables in a target DB, the target tables must be created beforehand with the same DDL as the source table. If the structure of a source table is changed, the target table must also have the change applied. Ripcurrent cannot automatically change the structure of a target table.
If duplicating to target tables in the same DB instance and DB schema, a postfix string (i.e. _masked) should be applied. This consistent postfix allows the target tables to be filtered out from monitoring by Debezium if they are in the same DB. This can be done by using a regular expression like .*_masked as the value of the table.exclude.list configuration property.
Ripcurrent cannot use a DB change event to replicate data to any tables being monitored themselves by Debezium as this would trigger an infinite feedback loop of DB change events.
Ripcurrent requires a licensed Voracity installation with a CoSort 10.5 build tag of May 2022 or newer, and an installation of Java JRE 11 or greater.
To monitor Oracle databases, place the Oracle JDBC driver, JDBC 4.x standard java.sql.SQLXML interface, and the Oracle Database XML Parser library jar files into the lib folder of the Ripcurrent distribution. These Oracle dependencies could not be packaged directly into the distribution due to licensing restrictions.
Installing Ripcurrent
IRI Ripcurrent is installed as an optional feature for IRI Workbench. From the top menu in IRI Workbench, select Help->Install New Software…
A screen similar to the one below will be displayed:
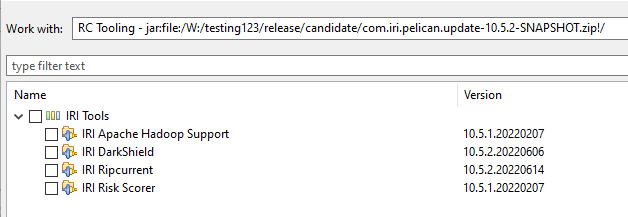
Select the IRI Tools site, and select IRI Ripcurrent from the available options.
When Ripcurrent is installed as a feature, there should be a ripcurrent directory located within the Ripcurrent feature folder of the Workbench distribution. This directory is the root directory of the Ripcurrent distribution.
In addition, the feature installs several user interface plugins to generate and edit a properties file, which is a file that specifies configuration options to Ripcurrent.
Configuring Ripcurrent
After installing the Ripcurrent feature, there is a new wizard available from the IRI Voracity (orca icon) menu to generate a Ripcurrent properties file. A Ripcurrent properties file contains configuration options that are read by Ripcurrent at the start of execution.
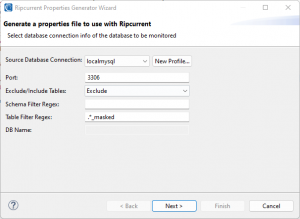
The first page contains options for the source DB to be monitored by Ripcurrent. Ripcurrent can monitor MySQL, PostgreSQL, Oracle, and SQL Server DBs. A source DB connection must be selected from one of the aforementioned supported DB types.
The port number associated with that connection should be entered. The default port number for the type of DB will be automatically shown, but the number must be modified if the DB is not using the default port.
Optionally, a regular expression pattern for filtering schemas and tables to be monitored within the DB can be specified. For some DB types such as Oracle and PostgreSQL, a DB name should be specified (e.g. ORCL). If the DB connection selected is a DB type that does not require this property, the text box will be disabled.
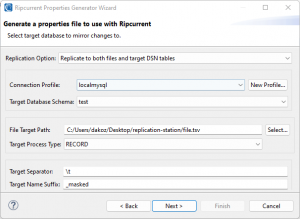
The second page contains options for Ripcurrent targets.
Ripcurrent can replicate data to either a set of files, DB tables in a schema, or both files and tables in a schema. After selecting a replication option, this page will be filled in with only the relevant configuration options for the replication option selected.
When targeting DB tables, select the target DB from the list of connection profiles. A target schema can be selected to which all events from the source DB will be replicated.
Ripcurrent will not create tables if they do not exist; therefore, a set of tables with the equivalent structure to the source tables being monitored must be already created in the target schema. The name of the target table should be the same as the source table, optionally with a consistent suffix such as _masked.
Alternatively, the target schema selection could be left unselected; in this case, an event received from the source DB will attempt to be replicated to the target DB using the same schema name as the table of the source event.
The file target path configuration should include a directory and base file name. The file name part of the path is actually not necessary but may be important so that the file has the desired extension, such as .xlsx for Excel files (otherwise the operating system will not know how to open the file by default).
A set of files are created – one for each unique table that changes have been replicated from – in the following format:
{Folder Portion of dataTarget}{SOURCE_SCHEMA}.{SOURCE_TABLE}-{suffix}-{Filename Portion of dataTarget}
For example:
C:\Users\dakoz\Desktop\replication-station\TEST.TRANSACTIONS-_masked-file.tsv
for an event from the TRANSACTIONS table of the TEST schema in the source DB.
The target process type is an option that specifies the SortCL process type of the output file. Record is for delimited files, CSV for delimited files with a header, XML for Extensible Markup Language, and XLSX for a Microsoft Excel Open XML Spreadsheet.
The target separator option specifies the separator between columns in delimited flat file outputs. It can be a maximum of 15 characters.
The target name suffix option is an optional configuration option that adds a consistent suffix to a target table name, which would otherwise be the same as the source table name.
The third page allows existing IRI libraries, which are artifacts generated in other Workbench wizards like the Schema Data Class Search wizard, to be selected for use in data classification and consistent rule application in the replication of data to targets.
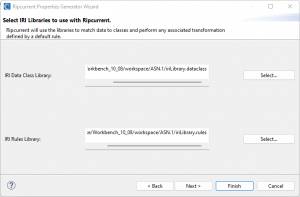
For example, a data class could be defined in the IRI data class library to consistently classify credit card numbers. A default rule can be assigned to the Credit Card data class to consistently mask all data classified as a credit card with format-preserving encryption.
The details of the rule referenced in the data class library are contained in the IRI rules library. If no data class library or rules library is selected, data will just be mirrored from source to target.
The fourth page has several other miscellaneous Ripcurrent properties to select from.
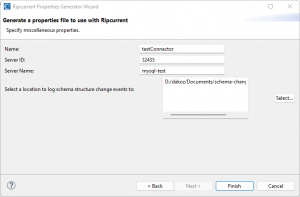
Name is a required property that specifies a unique name for the connector. It is not important what exactly this name is so long as one instance of Ripcurrent is running.
Server ID is an optional property to identify the DB client. A positive integer can be specified as the Server ID; otherwise a random ID is generated.
Server name is a logical name that identifies and provides a namespace for the particular DB server/cluster in which Debezium is capturing changes. Again, it is not important what exactly this name is if only one instance of Ripcurrent is running.
Finally, a file path that DDL contents of schema change events will be logged to can be selected (schema_change_events.log is the default value if no location is selected).
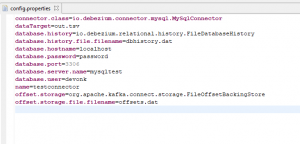
After clicking the Finish button, the properties file should be successfully generated and automatically opened in an editor for review. For example:
Executing Ripcurrent
Once a properties file has been successfully generated to the conf directory of the Ripcurrent distribution, Ripcurrent can be started.
To start Ripcurrent, execute the ripcurrent (Unix) or ripcurrent.bat (Windows) scripts in the bin directory of the Ripcurrent distribution.
Since Ripcurrent is run as a script (a batch script on Windows, otherwise a shell script), it can also be launched through the External Tools Configuration run configuration in IRI Workbench. As a run configuration, it can also be scheduled.
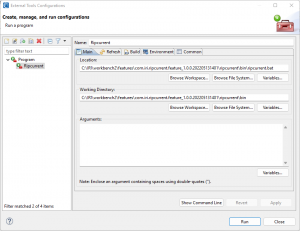
Ripcurrent will run constantly, monitoring the source DB for changes. Ripcurrent must be explicitly terminated to stop running.
If DB changes occur when Ripcurrent is not running, Ripcurrent will resume from where it left off; the changes that occurred in the meantime will not be skipped over.
Ripcurrent Documentation
Detailed documentation for Ripcurrent is available here, and help for Ripcurrent is also included in IRI Workbench.
Demonstrating Ripcurrent
This article provided an introduction of Ripcurrent, and detailed how to install and configure Ripcurrent. Additional articles in this series will display the capabilities of Ripcurrent through demonstration.
The second article demonstrates real-time replication of data with Ripcurrent, the third article demonstrates real-time data masking with Ripcurrent, and the fourth article demonstrates how the schema change event log generated by Ripcurrent can be monitored to alert when the structure of a database has changed (database change monitoring).










