
Masking PII in a Relational DB with FieldShield
The New Data Class Map DB Masking Job wizard in the IRI Workbench GUI for FieldShield creates IRI FieldShield job (.scl) scripts which, when run, will mask one or more tables in one or more schemas. Using this wizard automatically applies your chosen masking functions to like data (called data classes) as rules.
IRI recommends choosing masking functions that are deterministic in nature – like format-preserving encryption, hashing, or two-column pseudonymization – to produce consistent values in the output. This means each unique original value will have the same replacement value in every table.
Thus when you map deterministic masking rules to your data classes, joins will still work in your target schema. This is how FieldShield users preserve referential integrity in their lower / test environments without relying on key constraints (which may not be defined).
How that Magic Happens
Behind the scenes, your masking rules get built into FieldShield jobs by the New Data Class Map DB Masking Job wizard, which picks up the mappings of masking rules to target table(s) columns stored in a Data Class Map file. That Data Class map is one of the artifacts produced when you run the Schema Data Class Search (PII discovery job) wizard to find, report on, and classify the PII in your files and folders.
Diving Deeper
The Data Class Map, serialized in a .dataClassMap file, contains the mappings of your classified columns to the masking rules you defined in your Data Class & Rule Library (or .dcrl file, not to be confused with the Data Class Map). Your data classes (like email address, phone number, last name, credit card number, etc.) are also stored in the Data Class & Rule Library.
The Schema Data Class Search wizard performs data classification using Data Class Search Matchers. Search Matchers determine if a column matches a data class by the content of its values (i.e., using Data Matchers) or its metadata (i.e., using Location Matchers).
Running the Masking Job Wizard
Note that a Data Class Map is required to use the New Data Class Map DB Masking Job wizard. To start the wizard, click on the FieldShield icon in the top toolbar menu of IRI Workbench and select New Data Class Map DB Masking Job …
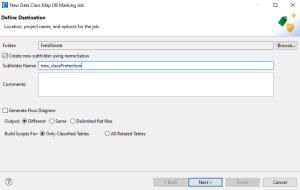
On the Setup page, enter the job details—the option to Generate Flow Diagram that can be toggled on or off.
If toggled on, a visual workflow diagram with table-specific transform (masking) mapping blocks inside will be generated. Note that generating a Flow Diagram significantly increases the time it takes to generate the job scripts when multiple source tables are involved.
Select an output type:
- Different will display a loader page to make selections about the targets.
- Same will use an Update function to modify only classified columns and load into the same table using ODBC. This option cannot be used if the primary key (or the first column if no PK) is being transformed.
- Delimited flat files will produce a delimited file for each of the modified tables.
In this example, Different is selected. Click Next > to move onto the next page of the wizard.
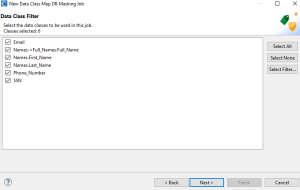
The Data Class Filter page allows the inclusion of selected Data Classes only. When you are ready to continue, click Next >.
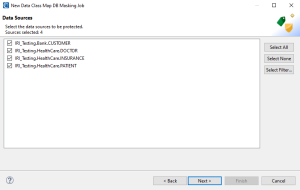
The Source page will be populated with the tables that are referenced from the Data Class Map which contains the mappings between columns and rules. On this page, we can include or exclude tables by toggling the check box to the left of each table.
At this point, you can click Finish to generate the FieldShield job for DB masking if your target data silo is either the delimited file format or the same (source) tables (update operation). Otherwise if your target data silo is different from the source tables, there will be one more page before completing the wizard.
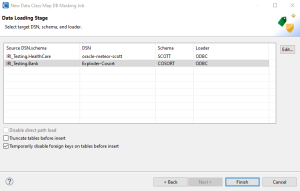
If you set the output of the job to Different then the Loader Page will be last. The Loader page is where the target details are entered.
The table on this page contains a list of unique Data Source Name (DSN) and Schema pairings. For each pairing, a DSN, Schema, and Loader must be assigned. Make a selection and either double-click or click Edit.
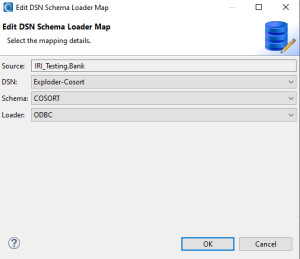
Enter the details for the target. The Loader options are filtered based on the database type. ODBC is also available for each database to use instead of a bulk loader, or if one is not available. Click OK.
If you use Oracle SQL Loader, there is an option to disable Direct Load. There are also options to truncate and temporarily disable the foreign keys.
Note that the tables must already exist in the target location with the same table name and structure as the source. Otherwise, you will need to create the tables before running the job.
After you click Finish, the wizard will produce new artifacts in a new project subfolder like this:
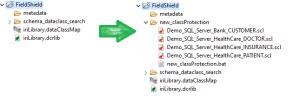
After the wizard has finished generating the FieldShield Job you will see separate .scl or .fcl task scripts for each table that will be masked by the FieldShield engine, SortCL.
Along with these table-specific task scripts scripts, is a .bat file that run the full FieldShield sequence of files like these:
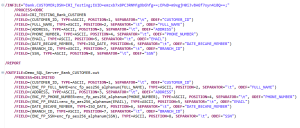
View of .scl file (job script) with instructions to read a table and send masked column values to a target file per the output option chosen on the first page of the wizard. Note the automatic encryption of credentials.

View of .scl file (job script) with instructions to mask and update the source table (target is the same).
The batch file generated, and what you would run to actually mask the schema, looks like this:
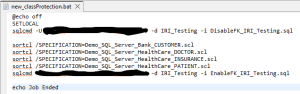
These bulk masking jobs run from Workbench, a DevOps pipeline, or the command line. You can thus trigger or schedule them for data refreshes and automatic archival. Note that “sqlcmd” or similar utilities required to run batch commands must also be installed on the system running the FieldShield executable, SortCL.
Here is a how-to video on using this wizard to produce and run a FieldShield DB Masking Job. Please email fieldshield@iri.com if you have any questions or need help with any aspect of this end-to-end configuration process, or its deployment.










