Voracity and the Logical Data Warehouse (LDW)
The traditional or Enterprise Data Warehouse (EDW) has been at the center of data’s transformation to business intelligence (BI) for years. An EDW involves a centralized data repository (traditionally, a relational database) from which data marts and reports are built. However, the EDW paradigm of physical data consolidation has been shifting in recent years to a more ‘logical’ one.
The Logical Data Warehouse (LDW) also serves analytic ends in a managed information management architecture, but accesses and integrates data in place (i.e., virtually). Specifically, a logical data warehouse is an architectural layer that sits atop the EDW’s store of persisted data. The logical layer provides (among other things) mechanisms for viewing data in the warehouse store (and elsewhere) without relocating and transforming data ahead of time.
LDW Trend Drivers
Several trends are contributing the EDW-to-LDW evolution, including:
- growth of data volume, variety, velocity, and veracity in the big data age of Web 2.0, mobile apps, and the Internet of Things.
- new data silos and formats that legacy ETL/ELT and BI tools cannot readily consume.
- analytic demands of digital businesses that need actionable information in real time.
- lack of data quality, compliance, and reliability in an ungoverned data lake or BI tool.
LDWs Will Become the Heart of the Modern Data Management Architecture.
If there were ever a movement that would force IT to modernize its data and analytics architecture, it is the IoT. The volume, velocity and variety generated are creating a deluge with which we are forced to reckon. The demands brought on by the IoT require that technical professionals build the data management and analytic architecture to accommodate changing and varied data and analytic needs. The environment must accommodate not only the traditional static, structured data and analyses, but also allow for access to less well-defined data using more advanced, iterative analytical techniques.
[Gartner, 2016 Planning Guide for Data Management Analytics, Carlie Idoine, October 2, 2015]
Certain “administrative issues” involved in EDW planning and investment are also well known:
- An EDW can host enough data to provide decision makers with the information they need to spot trends and drive strategies, but by the time the EDW is implemented, it may no longer meet current business needs.
- Dragging all that data into a central staging area before leveraging it, rather than leveraging it logically where it lives, is not always necessary, and much less efficient.
- EDWs are also encumbered by skill gaps and the costs of mega-vendor hardware and software; i.e., legacy ETL tools building and running those jobs are complex, slow, and expensive (even before a separate BI platform enters the picture).
Regardless of whether an EDW or LDW is used, data from transactional DBs, CRM systems, line-of-business applications, and other sources must be cleansed and transformed before, or within, the warehouse to ensure reliability, consistency, and accuracy downstream. Thus, careful thought must go into how data is extracted, transformed and loaded (ETL), actually or virtually.
Even though “small” structured data still drives most business decisions, the growing mess of unstructured data is what many business users and data scientists want to cull for decision value. So modern information architecture solutions must be flexible, nimble, affordable, and relatively painless to implement in order to work. Those qualities are everything the EDW is not, even though it still provides a vital purpose.
LDW Details
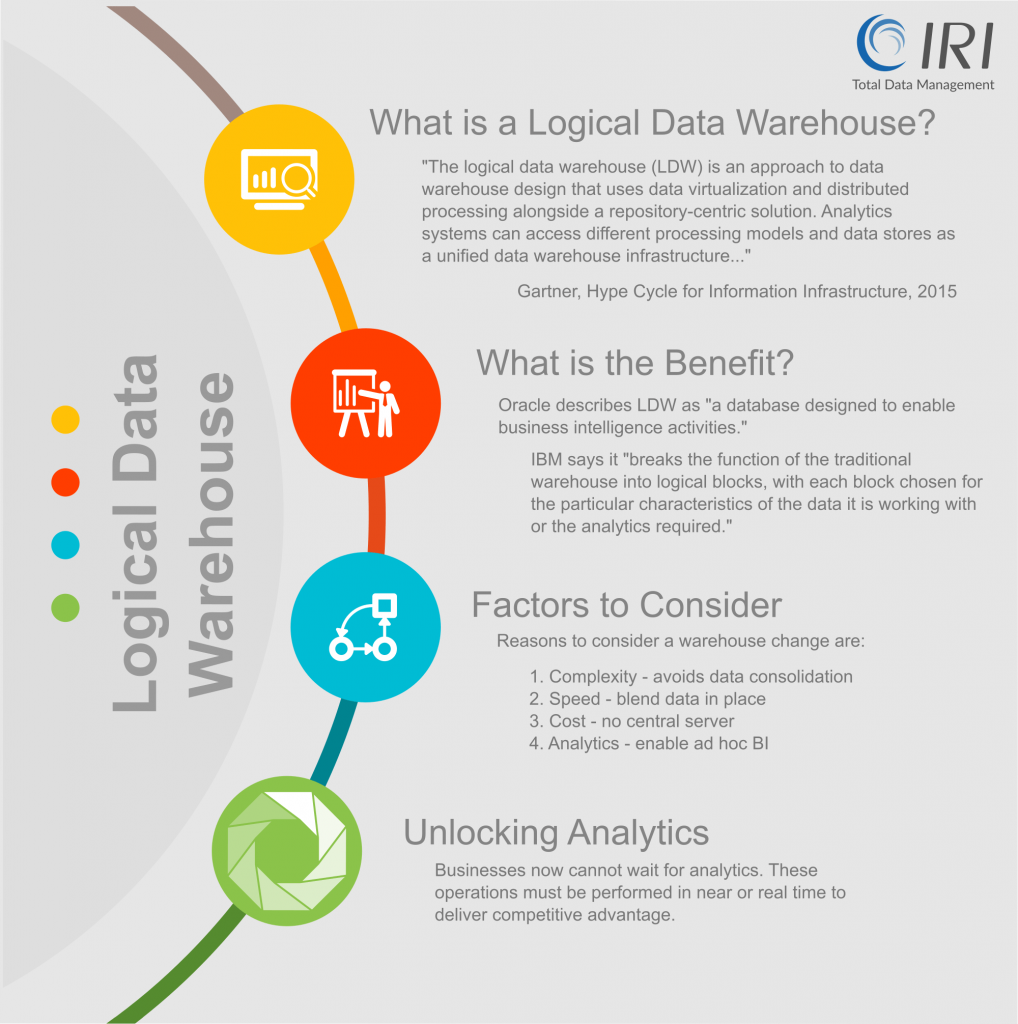
The Logical Data Warehouse (LDW) is a newer data management architecture for analytics that combines the strengths of traditional repository warehouses with an alternative data management and access strategy. Unlike a Virtual Data Warehouse (VDW) designed to work with multiple relational databases across a virtual network, the LDW is better positioned to deal with big data coming in from multiple silos in structured and unstructured formats.
The LDW has also been compared to the data lake, a repository for storing massive amounts of unstructured data, usually within a Hadoop infrastructure. The data lake can be particularly useful for handling the distributed processing component of the LDW. That said, differentiating the LDW from the VDW or the data lake does not give us a definitive picture of the LDW. In fact, arriving at that picture is no easy task because the LDW, as a whole, is as much a conceptual effort as it is a physical implementation.
Perhaps the best way to view the LDW is as a logical structure that’s defined by the sum of its parts. Those parts are the EDW, cloud services, Hadoop clusters, data lakes, and other elements, some of which include their own capacity to virtualize data and distribute processing. There is no one architecture that defines how the LDW should be built. It is changeable and malleable, with the essential ingredients necessary to handle all the enterprise data present.
Voracity’s LDW Play
To start with, IRI Voracity plays into the LDW as any data integration platform would. It can rapidly and reliably extract, load, and transform data components that reside in the traditional EDW architecture. But Voracity can also discover data accumulating in the storage repositories, effectively integrate that data with data from other sources, and also govern, PII-mask, and serve up results for analysis. It will directly build 2D reports, but is more commonly used to wrangle data for third-party BI and analytic tools like Business Objects, Cognos, Microstrategy, OBIEE, Power BI, QlikView, R, Splunk, SpotFire, or Tableau.
Voracity also feeds BIRT reports or KNIME analytic nodes with prepared data in memory, using APIs and UIs in the same Eclipse pane of glass. This collocation of, and metadata integration between, a traditionally managed DW infrastructure with a business user or data scientist’s sandbox combines data integration and governance with rapid-query mashups, ‘what if’ experimentation, predictive analytics, and even AI projects. It thus supports an even newer data integration paradigm coined by Dr. Barry Devlin, and described in his series of articles in this blog on the “Production Analytic Platform.”

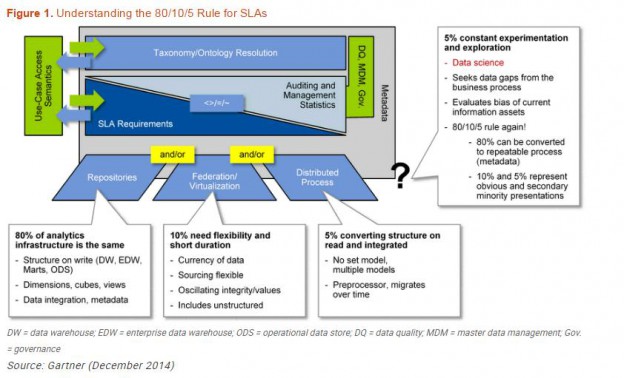
Gartner, Avoid a Big Data Warehouse Mistake by Evolving to the Logical Data Warehouse Now, December 2014, Gartner Foundational April 2016, G00252003
The table below reflects the merits of a virtual approach to data warehousing and what the Voracity data integration platform specifically provides:
| LDW Platform Components | What data virtualization does | What Voracity delivers |
| Repository Management | supports a broad range of data warehouse extensions | full management (sharing, lineage, version control, and security) for data and metadata in asset hubs, like EGit, SVN, and CVS |
| Data Virtualization | virtually integrates data within the enterprise and beyond | ergonomic, cross-platform connection, discovery, integration, migration, governance and analytics of heterogeneous data sources; i.e., federated queries using SQL or CoSort SortCL program syntax |
| Distributed Processes | integrates big data sources such as Hadoop, and enables integration with distributed processes running in the cloud | ingests and targets HDFS and Hive sources, direct or via ODBC, and can optionally execute IRI data transformation, masking, and related programs in MapReduce 2, Spark, Storm, or Tez (vs. using only CoSort SortCL) |
| Auditing Statistics and Performance Evaluation Services | provides the data governance, auditability, and lineage required | discovers and defines metadata, unifies and buckets, finds and masks sensitive data, validates, cleanses and standardizes data, tracks lineage, and secures metadata in a hub |
| SLA Management | scalable query optimizers and caching delivers the flexibility needed to ensure SLA performance | source-native API hooks or IRI FACT extract data into memory for consolidated transforms and reports, stream-feeds to Kafka, Splunk, or preps of a new dataset for R or other analytic tools |
| Taxonomy / Ontology Resolution | provides an abstracted, semantic layer view of enterprise data across repository-based, virtualized and distributed sources | automatically defines simple, Eclipse-supported metadata (DDFs) for all flat-files and JDBC connected sources, as well as COBOL copybooks and values found in “dark data” discovery |
| Metadata Management | leverages metadata from data sources, as well as internal metadata needed to automate and control key logical data warehouse functions | all jobs are based on SortCL syntax, which incorporates the above data definition file (DDF) layouts directly, or by reference, to their reusable/central location |
The bottom line: Faster insights and smaller footprints are possible through data virtualization tools and/or the federated query environment of the LDW. IRI Voracity is an ideal LDW platform technology because it connects to and rapidly integrates numerous data sources in place. It combines the key governance and analytic activities that produce the clean, compliant, and managed on-demand information that businesses need.










