When to Use Hadoop
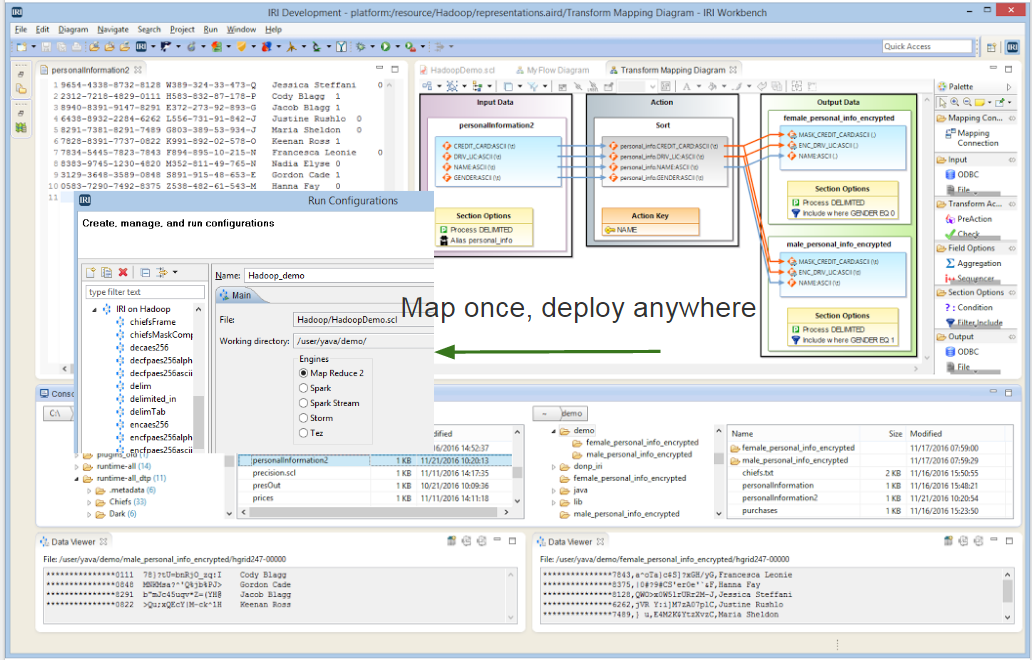
In the last couple of years since this article about the use of IRI CoSort as a parallel data manipulation alternative to Hadoop, IRI released the Voracity platform to process big data in either paradigm. With its “map once, deploy anywhere” capability, Voracity can run many popular jobs for data transformation, masking, and test data generation in the default CoSort engine, or in MapReduce 2, Spark, Spark Stream, Storm, or Tez without any changes.
Voracity is a full-stack data discovery (profiling), integration (ETL), migration, governance (data quality, masking, MDM, EMM), and analytics (reporting or blending) platform built on Eclipse.

The IRI Workbench GUI for Voracity showing Hadoop Run Configuration options
As seamless as the choice to run in Hadoop now is, the question about when to exercise it remains. The short answer is probably when input volumes approach 10TB, and your data are in HDFS. Here’s a longer answer:
Voracity’s CoSort engine (SortCL) runs reliably and fast enough below that point on most multi-core Windows, Linux or Unix servers that can hold the input, output and temp files … and still do whatever else they need to do. CoSort has better algorithms for each task than Java (or a DB) does, and a rare ability to run multiple tasks in the same job and I/O pass (consolidate).
Consider the CoSort benchmark here, and that there are inherent preparation and scheduling overhead in running jobs in Hadoop. If you can sort 50GB in 2 minutes with AIX CoSort, for example, and it takes at least a minute for Oozie to launch the same job in HDFS, stay off the grid for that.
Above that input volume, however, Hadoop’s inherent elasticity and redundancy, and the additional power of multiple memory and I/O backbones, should start to give it a performance edge over CoSort. You will also want to use Hadoop to process data sets that are or will be in HDFS if they are large. Voracity/CoSort/SortCL can access and process files or HIVE tables in Hadoop directly through drivers, which works fine (and is very fast) below a terabyte.
In other words, using Hadoop just to gain speed is not a good strategy when the data fit comfortably in the file system where it resides; CoSort will manipulate it efficiently on most Unix, Linux and Windows servers. Use Hadoop to process big data that resides in HDFS already.
If you are going to use Hadoop, the next questions are: how does that work in Voracity, and which Hadoop engine should I choose?
We explain how to run Hadoop jobs from Voracity in a generic Apache distribution here, and how to connect Voracity to your Cloudera, HortonWorks or MapR distribution through the ‘VGrid’ gateway here. Check out articles like this to assess which Hadoop execution option to use. Send your questions and feedback to voracity@iri.com.










