
Making Test Data Realistic – Without Taking It from…
 The increasing sophistication of software applications and the expanding role of database testers require high volumes of high quality, realistic test data that can faithfully represent existing, and stress-test new, platforms. Good prototypes also need test data that represents good and bad production data, and conforms technically and functionally to production characteristics.
The increasing sophistication of software applications and the expanding role of database testers require high volumes of high quality, realistic test data that can faithfully represent existing, and stress-test new, platforms. Good prototypes also need test data that represents good and bad production data, and conforms technically and functionally to production characteristics.
Those using copies or subsets of real data for testing risk exposing personally identifiable information (PII) like credit card and social security numbers, birth dates, names, and medical conditions. PII is also often protected by government regulations.
IRI provides robust data masking software products like FieldShield for finding, classifying and masking PII in databases and files (structured and semi-structured), CellShield for Excel spreadsheets, and DarkShield for unstructured text, document and image files.
However, production data may be off-limits, not yet exist, or be considered inadequate for testing. For these reasons, IRI RowGen was designed to create realistic test data without requiring real data. RowGen uses both random data generation and set file selection techniques to generate data without the need for data source access.
All of the data masking products mentioned above, as well as RowGen, are also included in the IRI Voracity data management platform. However, this article only focuses on the ways in which RowGen fosters realism in test data targets, be they relational databases in data warehouse or Data Vault schemas, flat or JSON files, or even custom-formatted reports with embedded transforms.
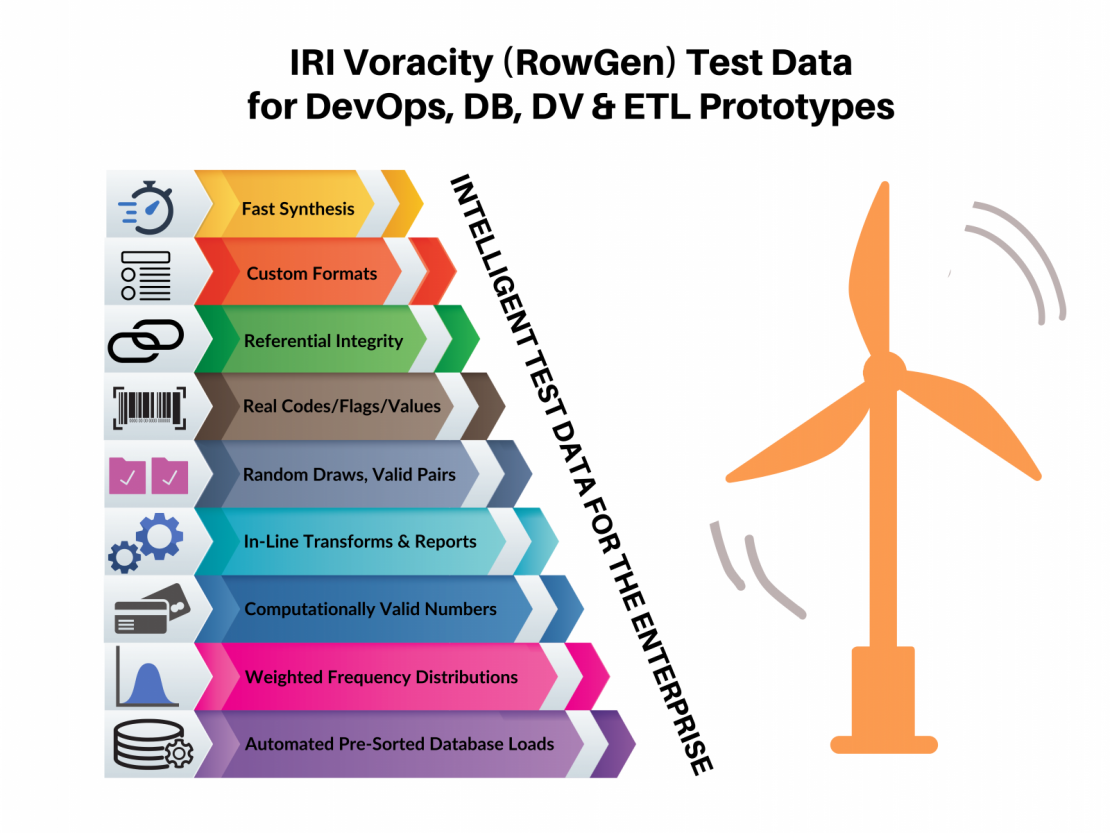
To assure the realistic nature of that data in appearance and behavioral terms – that is, to preserve the look, feel and frequency of production, and to conform to database constraints — RowGen has a number of critical ‘intelligent test data’ features, including:
Referential integrity
Referential integrity preserves the same relationships in the test data that exist in the real data, such as a supervisor to an employee, store to a city, and student to a college. This makes the test data more realistic and usable for query testing, and for developing database applications that have to run against future linkages in the data. RowGen preserves RI both in the generation of target tables from scratch, and in its new DB subsetting wizard.
Random selections from real data
By using values from the set files containing real (or realistic, e.g. names from a phone book) data, the test data will includes the same (or at least similarly looking) proper nouns, values, and items that exist in reality. In RowGen, real data that may need to be taken from actual columns or files is selected at random; this disassociates real people from the attributes they carry in a production table or file.
Compound data value definition, or format masks
RowGen users can define custom data formats for the data generated. The resulting test data has the same format characteristics needed for testing. For example, you may be building a new application around stock trades, and RowGen allows you to generate values that conform to the exact specifications and value computations, such as market-specific currency formats that are part of buy/sell calculations and forecast models. This produces valid test data that can reflect real-world transactions and trends.
Conditional placement of constants and variables
As RowGen generates realistic test data, it allows you to specifically locate and display literal strings and ad-hoc values that lend realism to the output. For example, you can insert specific messages and data flags, dates, times, user names, and other values from the system environment in the test data, just as you might see in transactional or real time production sources. The use of conditional selection and display logic produces test values in real formats that follow the same business rules that apply to real data.
In-line sets, or literal value ranges, in field statements
By allowing value and range definitions at the field level within RowGen job scripts, users have a very convenient way to specify a precise datum, or choose from a narrowly defined scope of numbers. This precludes the need for external set files while still affording the opportunity to output only those values the test data should contain in that field.
Math and custom computation functions
RowGen’s ability to perform mathematical operations, and perform bespoke computational functions during the generation of test data, allows user to apply the same logic to test data that occurs in production data. For example, the use of custom field level procedures allows RowGen users to define their own national ID format and assure that the values produced conform to the validation standards for that particular format. RowGen can also generate standard and custom date formats within specific ranges and assure weekdays match the dates.
All and valid (joined) pair value generation
RowGen’s ability to define set files from production column values results in pairs of test data that reflect either exact combinations of columns that exist in production (joined or valid pairs) or a randomly permuted set of pairs that produce realistic bad data. Either way, the resulting join operations on the test data will behave in the same predictable manner as production data (matching or not), while preserving the values from the production data that enable cogent analysis. If the data were randomly generated, there would be no way for human validation of the results.
Weighted distributions to mimic real value occurrence rates
RowGen can also create realistic test data that reflects the way real data occurs in production, or in nature. The default distributions in RowGen are linear, bell curve, weighted, and weighted with items. RowGen users can also define their own distributions should the test data need to adhere to a different frequency pattern.
Computationally valid value generation
A number of field-level generation functions have been created for RowGen users for synthesizing realistic – in both format and value terms – national ID and credit card numbers, including social security numbers. See the articles throughout this section of the blog for what’s available.
For more information on RowGen version 3 and its ability create realistic test data, please refer to RowGen’s product page or review the other articles in the “Test Data” section of the IRI blog, like this one on creating fake PII.










