Process and Protect HL7 Data with Voracity
Editors Note: It is now possible to discover, deliver, and de-identify PHI in text-based HL7 files directly using the IRI DarkShield data masking product for semi-structured and unstructured files, which is also included in the IRI data management platform mentioned in the discussion below where the HL7 files are structured. See this article on how to discovery and de-identify PHI in HL7 files directly with the fit-for-purpose HL7 search/mask wizard in DarkShield.
This article shows how you can use IRI Voracity to rapidly integrate and mask sensitive healthcare data in the HL7 file standard we introduced here.
The process begins as HL7 messages are converted into a relational format using Flexter Data Liberator software from Sonra. The output of that process will be an Oracle database — which means easy metadata discovery and data manipulation/masking job creation in Voracity.
Flexter is XML parsing software for any industry data standard, including HL7. Voracity is a data management platform for data discovery (profiling), integration (ETL), migration, governance (DQ, masking, line age, etc.), and analytics (BI and data preparation), built on Eclipse.
We will invoke Flexter’s REST API to process the data from a Linux client. In the configuration file for the client we specify the REST end point, the output data store, and the connection details to our database:

We execute the command:
./push_full.sh ADT_01.messages.xml ADT_01.schema.zip
Then, we pass the filename of the XML message ADT_01.messages.xml and the filename of the XSD ADT_01.schema.zip to the command.
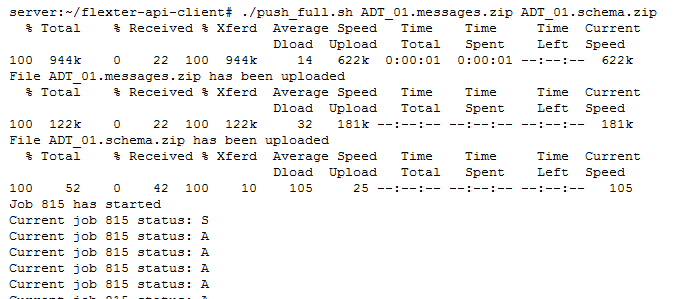
It takes a few seconds to process the file. XML parsing in Flexter happens in three steps:
- Flexter analyses the XML schema and collects sample statistics from the provided XML files. It uses this information to generate an optimized and simplified relational target schema.
- Flexter generates the mappings from the XML source elements to the relational target attributes.
- Flexter processes the data locked away in the XML files and loads it into the target data store; e.g., an Oracle DB. It also generates the primary and foreign keys, constraints, and indexes.
Note: Flexter uses a pluggable architecture, which allows us to easily add new input and output data stores or even different data formats such as JSON, EDI, etc. Flexter and Voracity can also run atop Spark to optionally distribute large processing loads across multiple servers.
Once Flexter has finished creating the target schema and we have successfully staged the HL7 data in our Oracle database, we can use Voracity to transform it further downstream.
HL7 Data Processing & Protection in IRI Voracity
Now that we have processed the HL7 XML data into a usable format, we can utilize Voracity for ETL, cleansing, masking, reporting, or other processing.
In this example, Voracity used the Oracle schema that Flexter generated, and it simply needed to execute the SQL command against the provided DDL to populate the tables. That script was only needed because Flexter and Voracity were not on the same server; in most cases, they would and this process would be automatic (no DDL needed).
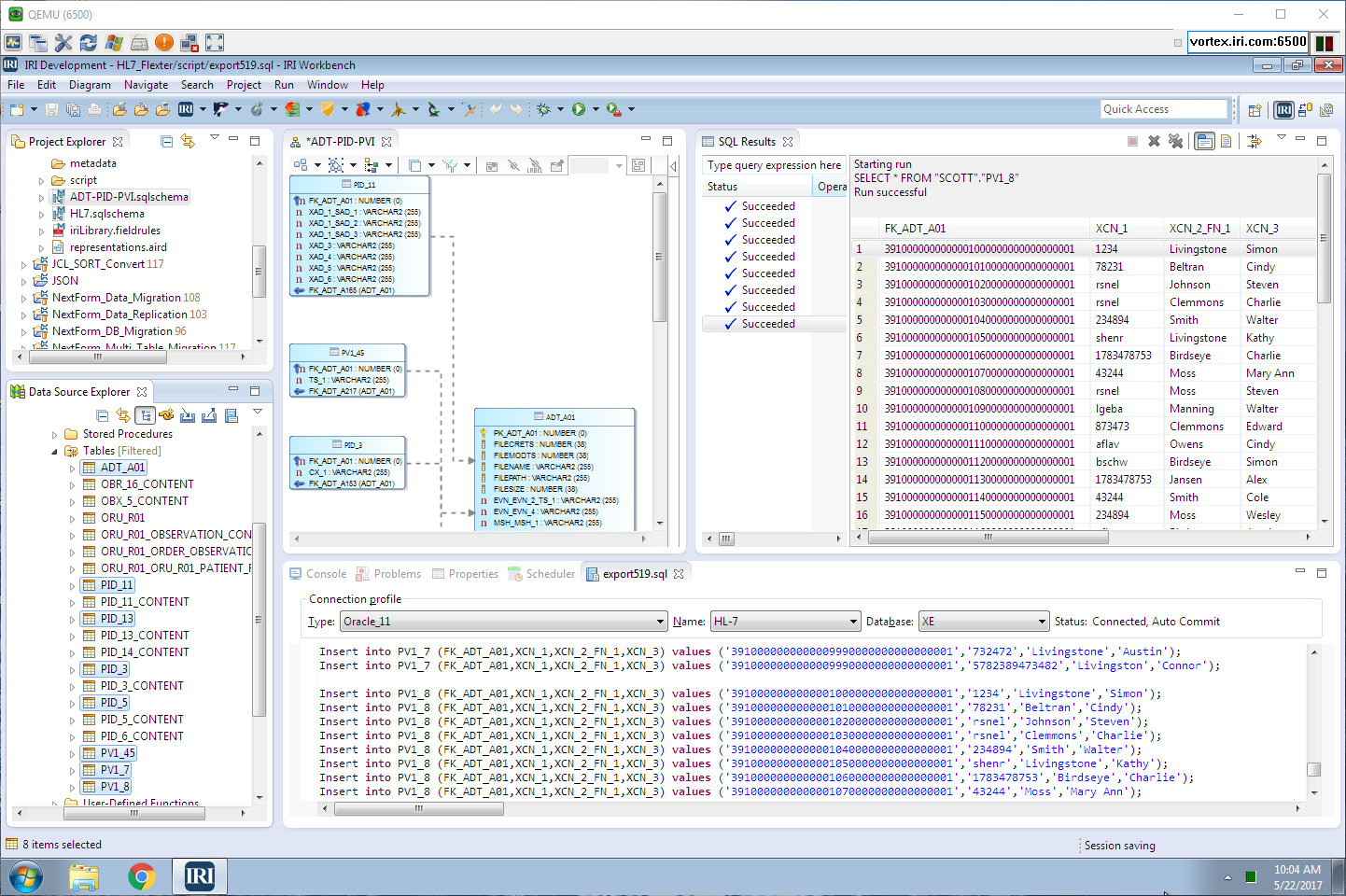

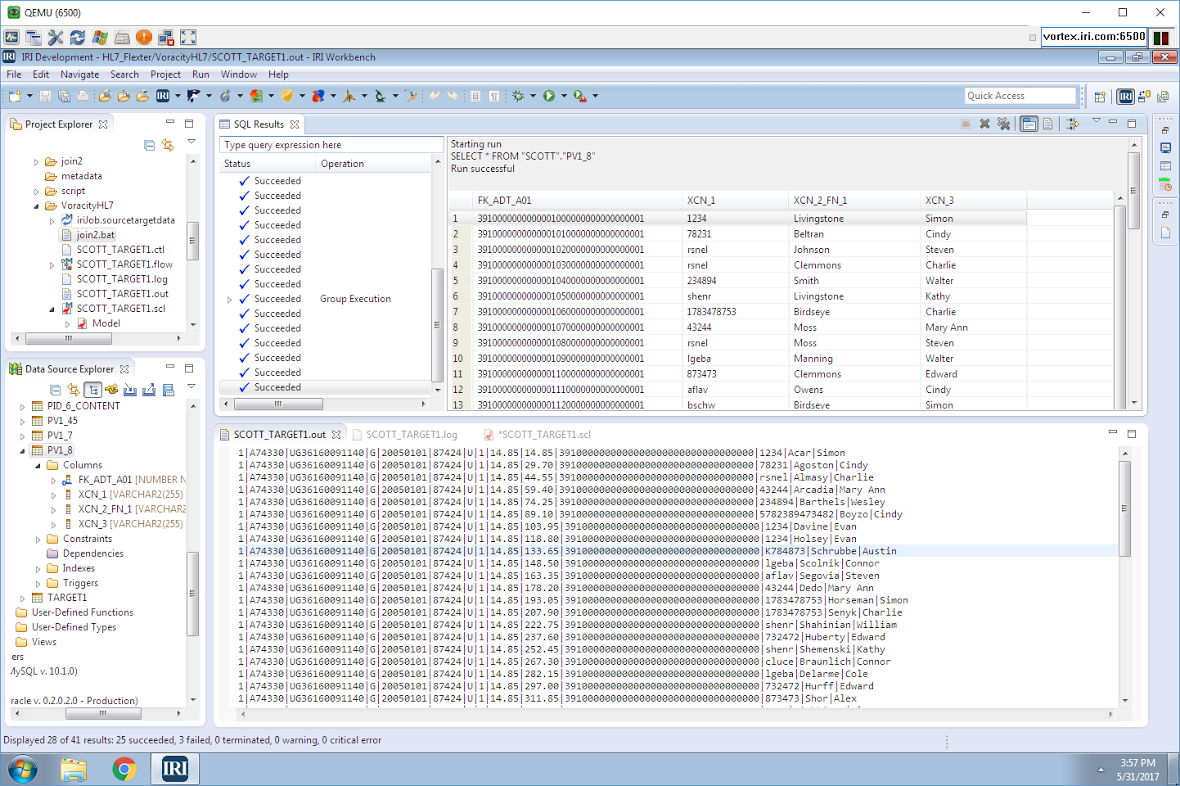
Shown above in IRI Workbench — the free Eclipse IDE for Voracity — are the HL7 tables in Oracle and their auto-exported content on display. On the right is the auto-built E-R Diagram and the SQL display of the target table we created and populated, again all in the same environment.
I created a single Voracity job to simultaneously (in the same script and I/O pass):
- sort and join the ADT_01 fact table to the PV1_8 first and last name dimension table
- aggregate, on a running basis, the price column in the fact table
- encrypt the driver license value in the fact table with AES-256 format-preserving encryption
- pseudonymize only the last name value in the PV1_8 dimension table from a look-up set
- collect only the first 50 records (to save time and space)
- bulk load the pre-sorted data into a new target table
The same wizard that helped me create this job also created the create table and SQL*Loader control file to bulk-load the pre-sorted data into my new target table.
I used dialogs like this one to modify it apply the masking rule:
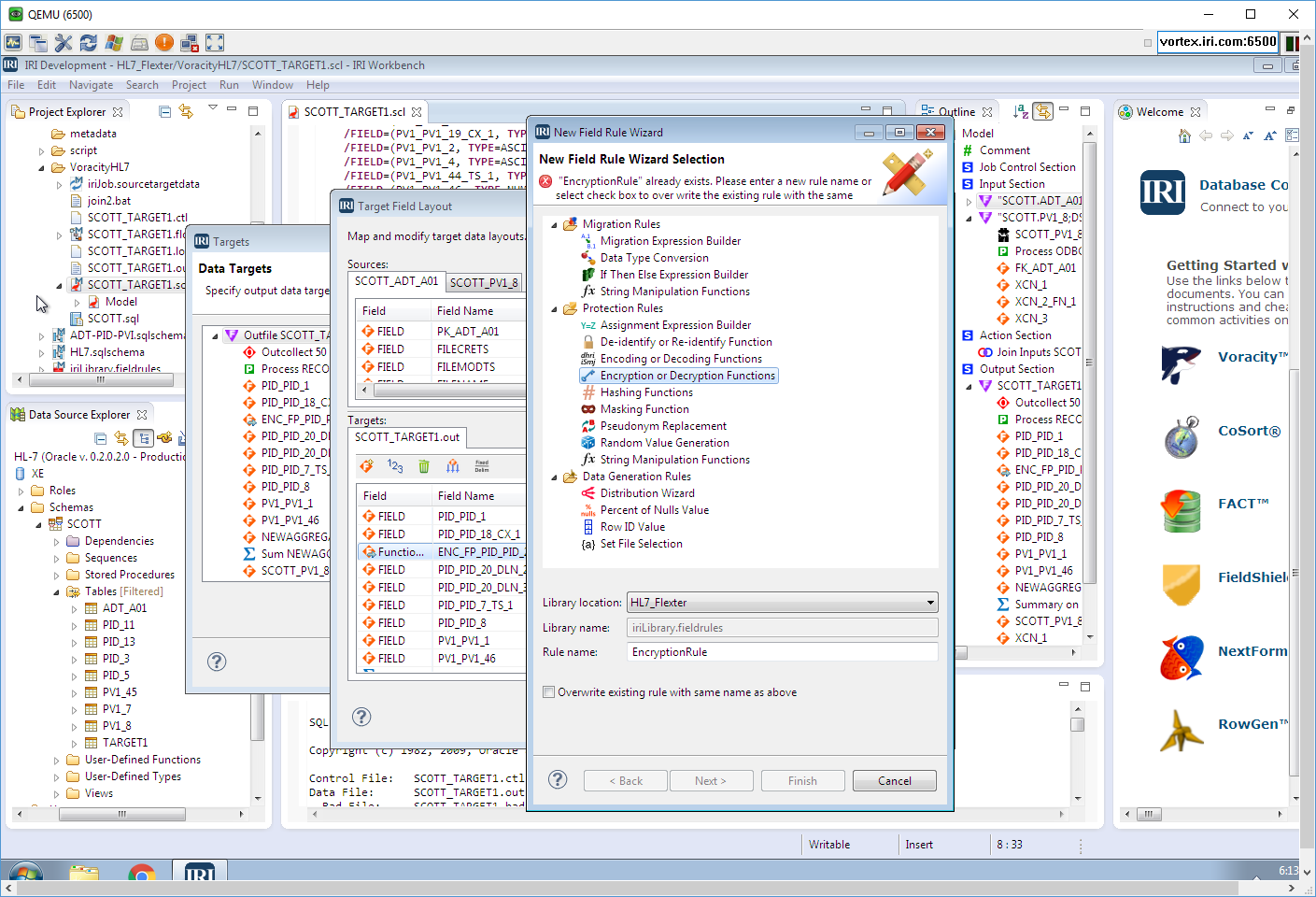
and a menu function to abstract the job into a workflow. Inside that workflow is my combinatory job script, a dynamic outline that interacts with it (and the rest of the GUI), and its representative transform mapping diagram alternative that ETL architects often prefer:
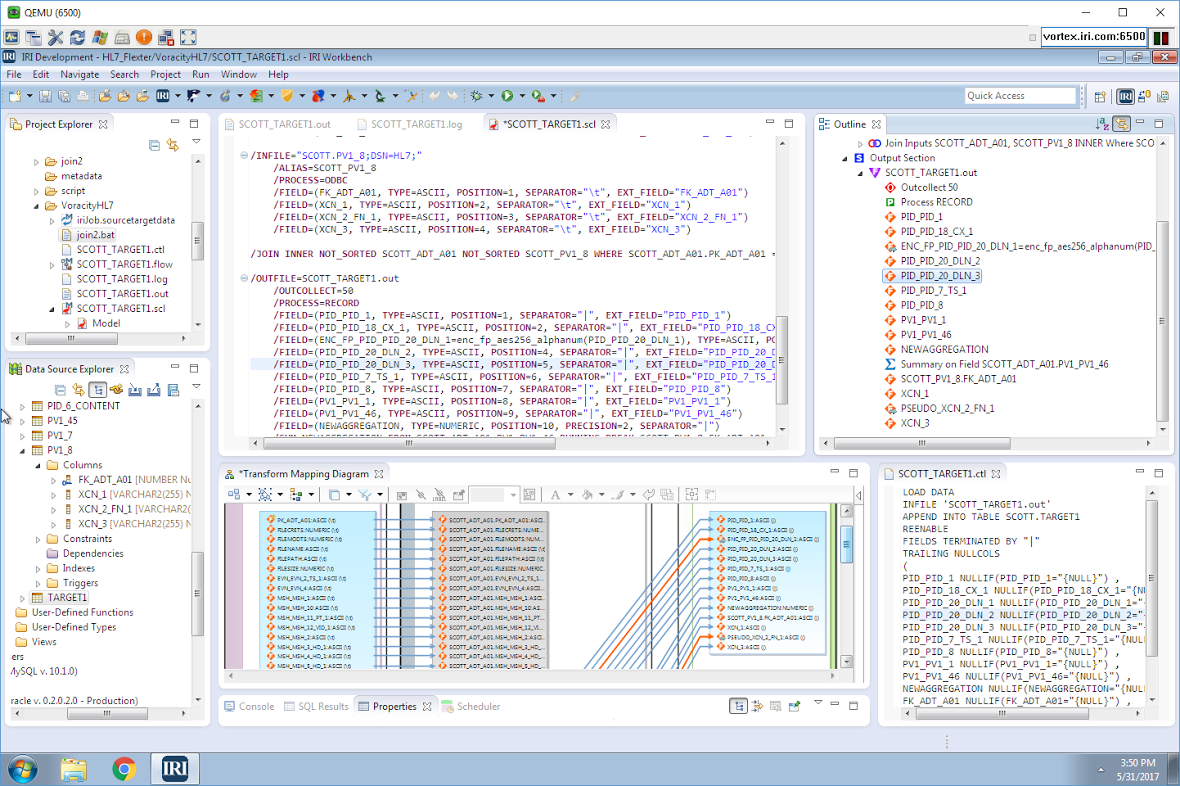
Voracity serializes workflows into a batch file that runs the mapping/masking and load jobs together, and produces the final result in load file (and table) form:

The driver’s license (DL) and price column values in the target did not have the variability I would have liked, as the original values provided by NIST appear to have been planted with redundant test data. However, it does make it easier to show the changes Voracity made to the data, and to demonstrate that the masking rules applied consistently which proves referential integrity is preserved.
During this same processing pass in Voracity, I could have specified more targets, including custom-formatted detail and summary reports, or hand-offs to third-party business intelligence or reporting tools.
Contact IRI if you are interested in using either Flexter Data Liberator and/or the Voracity platform.










