PII Masking in CSV Files
This article demonstrates data masking of a Comma Separated Values (CSV) file using a data manipulation job wizard in the IRI Workbench GUI. In fact, this example shows how PII can be masked from almost any IRI job wizard, though CSV file masking is most often performed from a single or multi-file IRI FieldShield job menu.
A CSV file is a delimited file for tabular data and plain text that uses a comma to separate field values. Files in CSV format can be imported and exported from programs that can store data in tables.
CSV data masking tools like FieldShield should be able to identify and mask atomic CSV column values in files. FieldShield can use data classification (bulk discovery) to find consistently mask CSV files in one or more LAN, Hadoop, or cloud (S3, Azure, GCP) folders, or streaming from message queues, pipes, URLs, etc.
IRI Workbench is the graphical user interface (GUI) and integrated development environment (IDE) for FieldShield and all IRI data management and protection software products, as well as the Voracity platform which includes them.
Note that it is also possible to find and mask sensitive data in CSV (or other delimited file) columns (and even when it’s embedded in free-text columns) in IRI DarkShield, but this article focuses on the older FieldShield method, which retains the advantage of performing additional business logic (including data transformation, cleansing, conversion and reporting) while you mask due to its use of the IRI SortCL data manipulation program. Both tools can leverage common data classes and masking functions; e.g., to find and mask PHI in CSV files using HIPAA data classes.
IRI Workbench features metadata creation, conversion, discovery, and application wizards to help you generate, deploy, and manage IRI task and batch scripts, data definition files (DDF), and XML workflows common to all IRI software, as well as SQL. The wizards in IRI Workbench produce the underlying metadata and rules for:
- data masking & re-ID risk scoring
- data integration (ETL) & CDC
- data migration & replication
- test data (file) generation
My example uses a simple sort and PII mask of data in a CSV file. It sends the output to another CSV file and an Oracle database table. Note
Find My Data
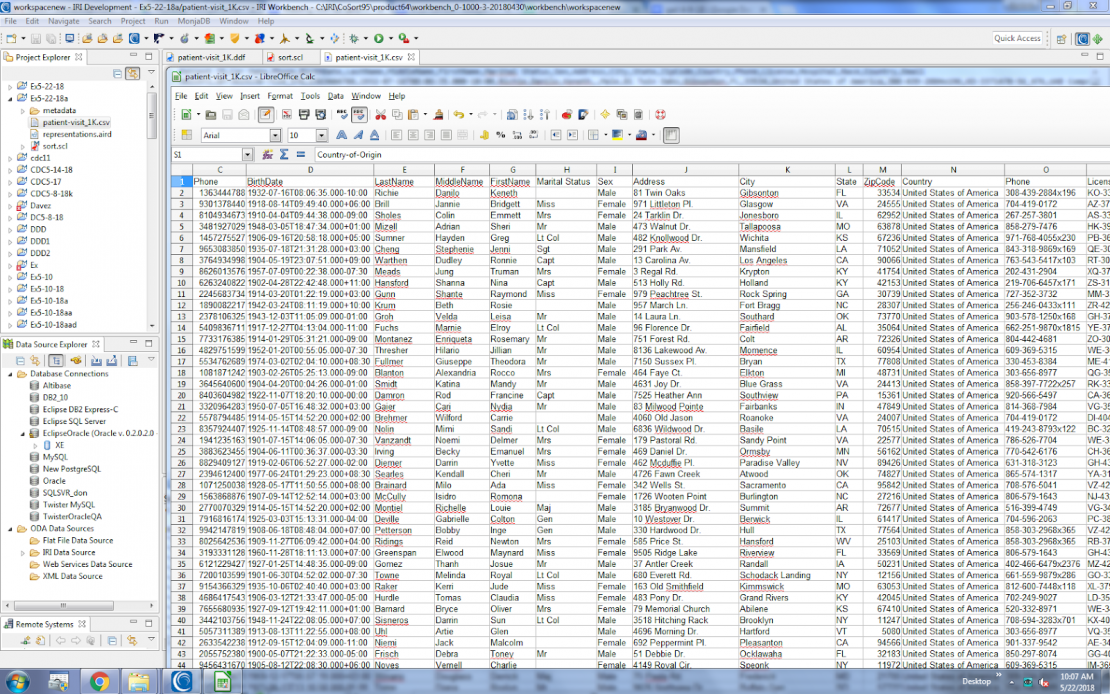
I first locate my data source, a file called patient-visit_1K.csv, which contains a form of PII known as PHI (protected health information). I happen to know about this file. But what if I had many CSV files and I do not know which ones need masking?
FieldShield users seeking PII in CSV can find it through several data discovery tools, including a flat-file profiling tool and Directory Data Class search wizard. A “dark data” discovery facility within IRI DarkShield can also find PII in CSVs and other files — structured, semi-structured, and unstructured — too.
In this case, the PII in my file is considered Protected Health Information, or PHI, that must be de-identified according to HIPAA data privacy rules. I will only show a few of the many available masking techniques here.
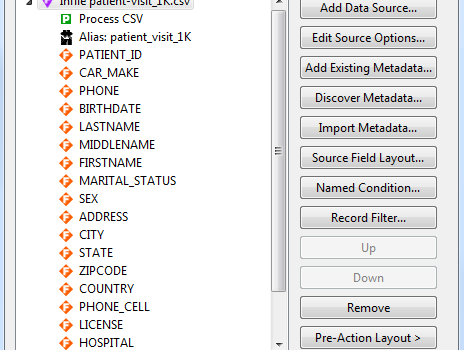
The figure below shows the file’s contents, including FirstName, LastName, BirthDate, Country, Address, City, State, Phone, and License.
Pick and Run a Job Creation Wizard
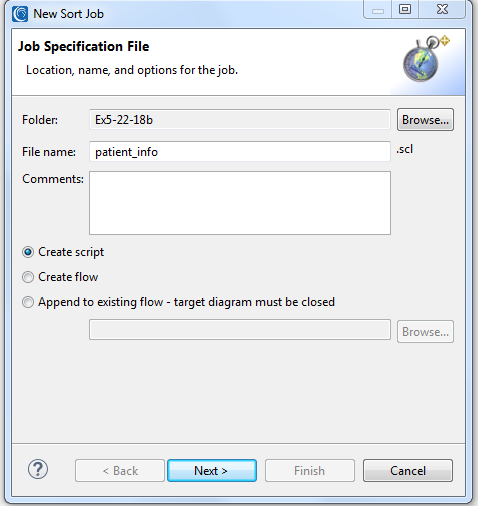
As mentioned, IRI Workbench includes many fit-for-purpose wizards that design discrete tasks (.*cl scripts), or batch jobs (.flow and .bat/.sh files) which run on the command line, through Workbench, your programs, etc. I chose a simple sort job wizard because even its single .scl script result can specify several functions and targets.
That wizard runs from the CoSort menu group (stopwatch) icon from the IRI Workbench toolbar. I select New Sort Job, and specified patient_info.scl as the name of my job:
Data Source Specification
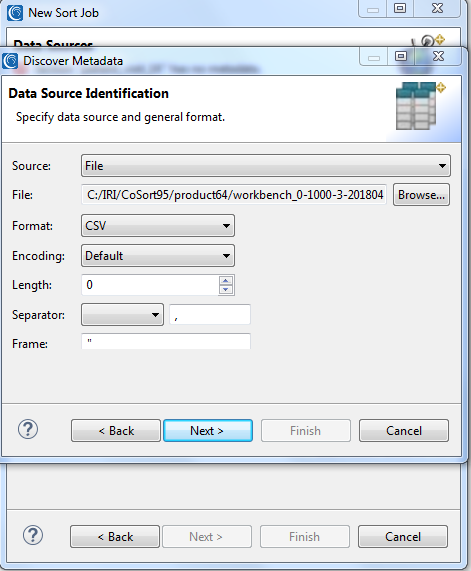
Next I browse to specify the location (path) and name of my input file, plus its field layouts in IRI data definition format (DDF), which all SortCL-compatible programs require. This metadata can be specified directly in the job script, or stand alone in a reusable, shareable DDF file that other IRI programs can use.
It is for this reason that the wizards ask me to use an existing, or auto-create new, DDF metadata for my input file. Because the DDF did not yet exist, I chose the Discover Metadata … option, where a sub-wizard parsed my .CSV file headers into DDF layouts. I then chose to put that layout detail directly into my job script as input specifications, rather than save and refer to them from an external DDF file.
After that, you can see the wizard’s Data Source specification dialog where the Process is CSV and all the fields that were discovered are added in:
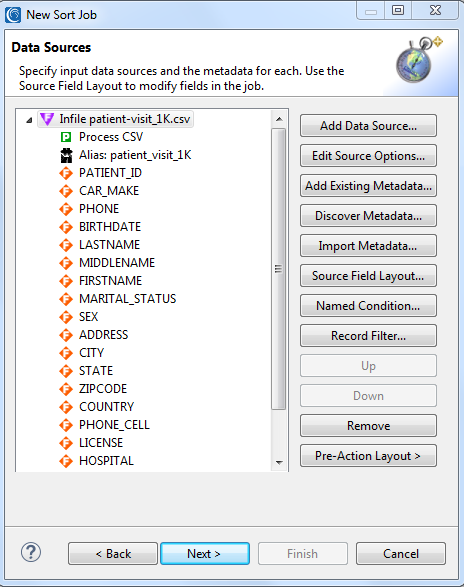
In the next dialog, I specify a sort key field to define the order of data in my target(s). In this case, I will sort by patient_id:
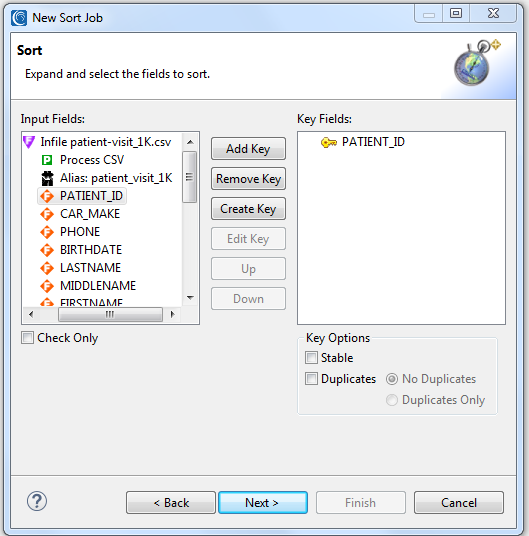
When I click Next >, I am provided with the Data Targets screen where I specify both a table in Oracle and another CSV file to receipt my processed data. Note how their “Process Types” types got added automatically; ODBC for the database insert, and CSV for the other:
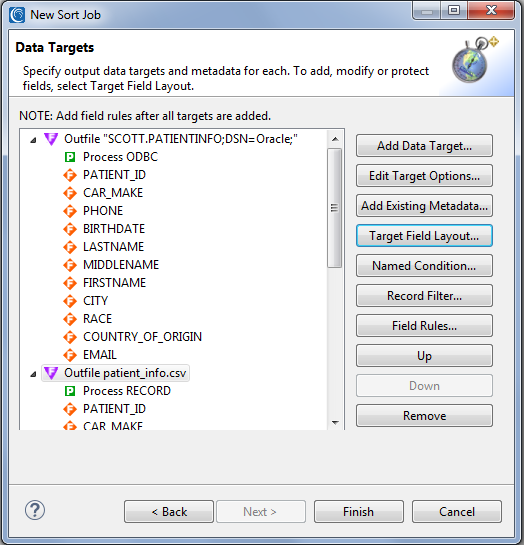
Since I want to also mask some of the sensitive fields, I need to apply some field-specific function rules in the target. So, I click on Target Field Layout … to open the wizard’s top-down, source-to-target mapping dialog. It is within that dialog that I then right click on the fields I want and can chose apply an existing masking rule, or create a new one:

The images below show where I apply hashing and redaction functions for my selected fields.
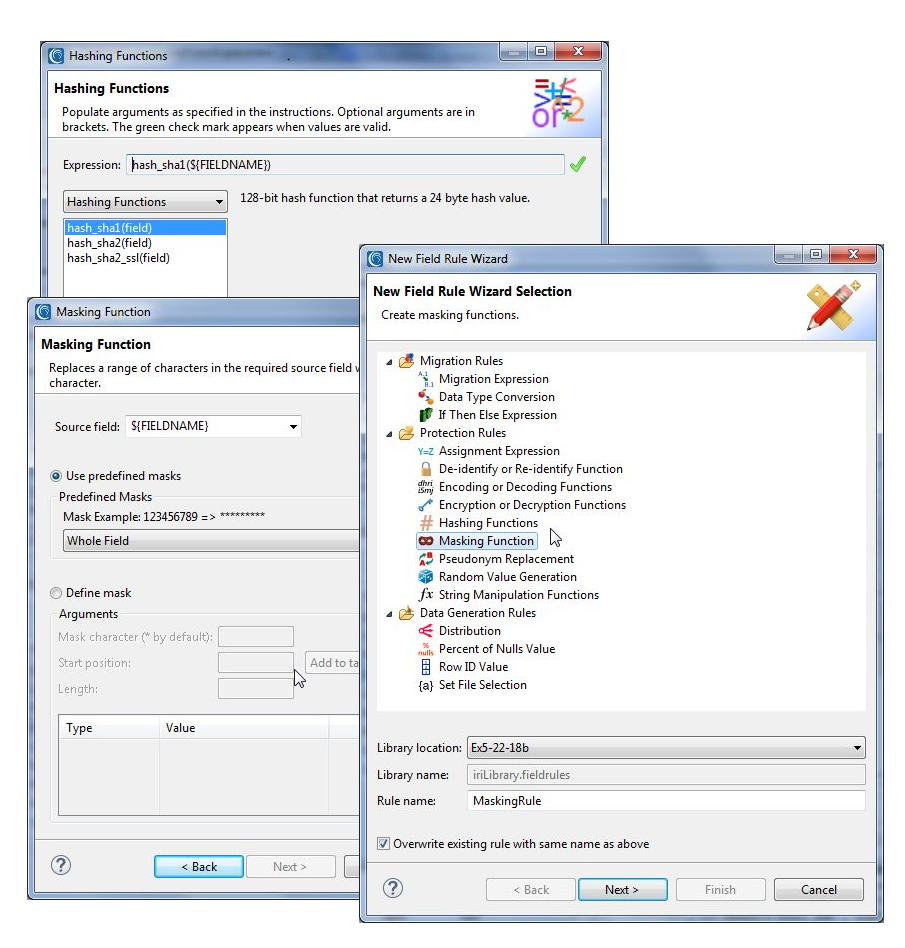
I chose basic string masking to redact the patient_id and license values, and a hash function for the birthdate. Note that IRI also supports both mathematical expressions and random date blurs to shift ISO-formatted dates by a given number of days. See this article for advice on selecting the right data masking function for any given field.
After I am done with these dialogs, the final Data Targets dialog in my job wizard reveals the modifications to be performed on those fields:
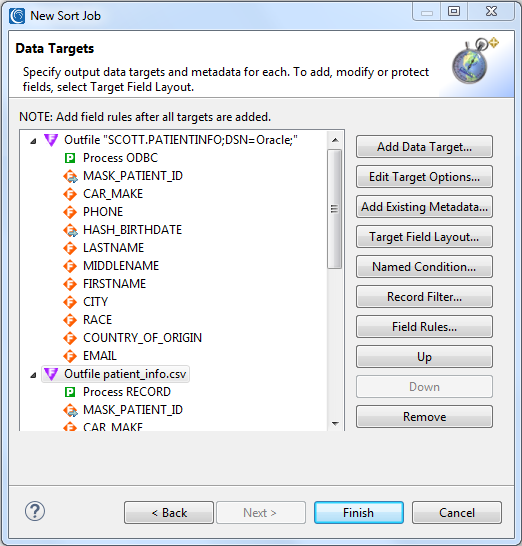
Now that I have designed the job, I click finish to have the wizard save the job in script form, so I can review, modify, share, and run it as needed.
Run the Job
The job script generated by the wizard is automatically displayed in the GUI for review, modification, and execution. That script gets parsed and run in a command-line FieldShield executable, or a SortCL executable licensed for CoSort/Voracity use. I can deploy it from ad hoc or through its task scheduler, or from the command line or any external batch or scheduling program.
Shown below is my final job in script and outline form, as well as the results from running it. See the masked PATIENTINFO table in Oracle, and in patientout.csv: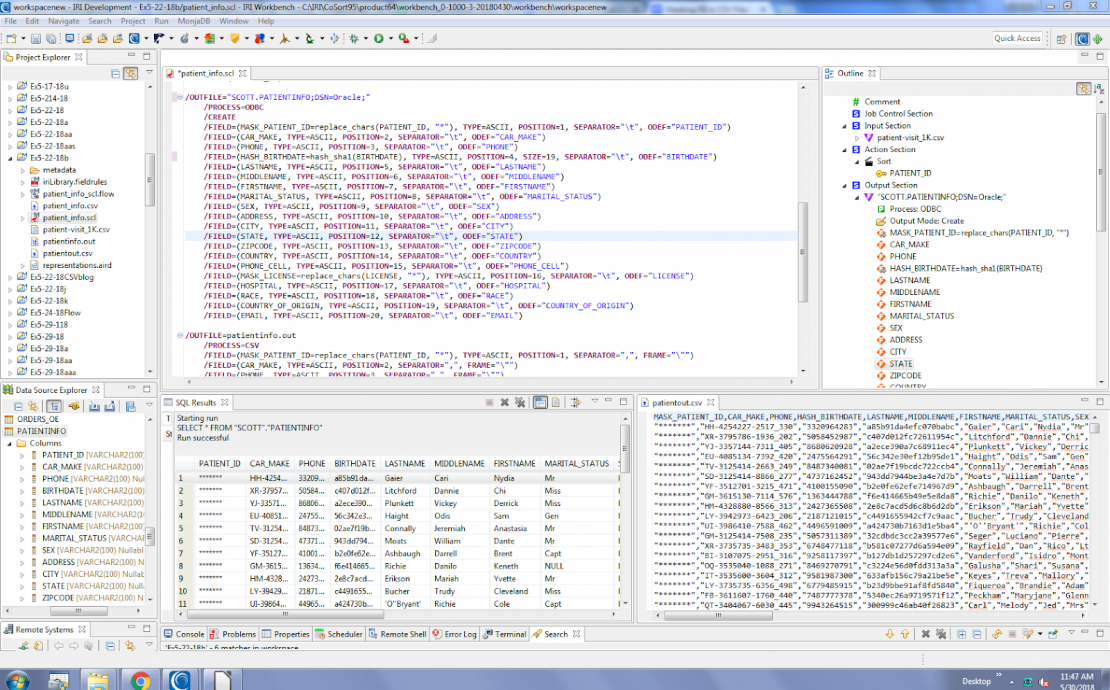
Job Diagram Options
With the .scl job script built in my active project, I can also right click on it, and from an IRI menu of options, build a flow diagram to visualize the task within a project. From within the flow diagram, I double click on the task block to reveal a transform mapping diagram showing the source-to-target field movement I’ve defined:

The orange connections denote those target files that have been derived or transformed; in this case, a data masking function. I can also create modify my job parameters from these diagrams as well, and save the changes to overwrite my job script.
If you have any questions about CSV or other flat file manipulation or masking, leave a comment below, or contact your IRI representative.










