
Using CoSort on Restructured Data in the IRI Workbench
This is the final article in a three-part blog series introducing IRI’s new data structuring technology. The first blog introduces “dark data” and the unstructured sources the wizard can analyze. The second in the series offers a deeper overview of how the Data Restructuring wizard works and this article shows how that newly structured data can be leveraged in the same GUI by various IRI software products.
The preceding article discussed the use of the Data Restructuring wizard in the IRI Workbench GUI to parse data from unstructured data sources. Recall that we extracted the data based on search patterns into a structured text file, and automatically defined the new layout in a data definition file (.DDF) available for use in any IRI CoSort or other IRI software application.
This article picks up where that one left off … to show how a structured data file and its DDF can be used to process the extracted data in the same GUI for CoSort. The data can be transformed, reformatted, protected at the field level, and reported upon in the same job script and I/O pass in CoSort SortCL programs. SortCL outputs can be sent to multiple file and database targets at once:

In our first application, we will sort our text file by phone number, and remove the duplicate record. We will also mask the first 12 digits in the credit card account numbers (green line in image below), and encrypt the social security numbers (purple line in image). A report header was added to clarify the output (red line).
Note that the RegInfo.ddf metadata repository created by the Data Restructuring wizard is referenced in the input section to define the fields. In this example, the output is sent to standard out (stdout) to display in the console:
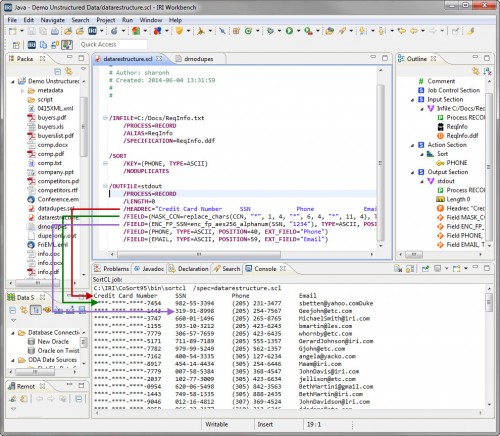
Changing the SortCL job script produces the duplicate records.
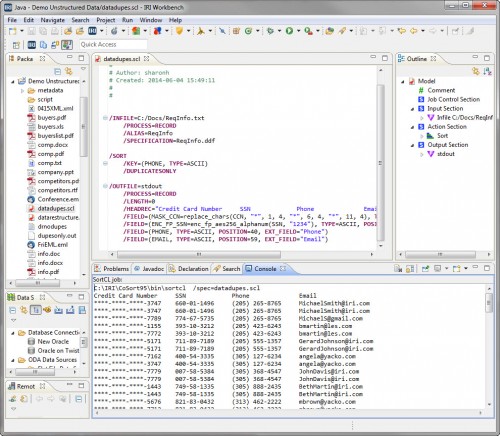
In conclusion, the unstructured data we first structured in the IRI Workbench has now been re-structured once again in the same Eclipse GUI, and can be re-fit for any use. There are in fact no limits to the possible permutations in, and purposes for, SortCL job scripts, nor in other IRI Workbench products that use .DDF files, including:
- IRI NextForm – for data migration, replication, federation and reporting
- IRI FieldShield – for data masking and encryption
- IRI RowGen – for test data generation
Let IRI know if you would like to see more packaging and provisioning manifestations of such big data processing, including ad hoc reports in BIRT, hand-offs to other analytic tools, pre-sorted bulk database loads, etc.
To see what unstructured data sources and dark data can be analyzed by the Data Restructuring wizard, visit our blog Finding Dark Data in Unstructured Sources. To see how to use the wizard to discover unstructured data, visit our blog Using the Data Restructuring Wizard to Unlock Unstructured Data.











2 COMMENTS
I understand that you can use CoSort or its compatible tools in the Workbench to process the data once it’s been flattened by the wizard. What kinds of transforms can I do, and why would it be more efficient to do them in CoSort than in a DB? And would be easier than SQL, a language I already know?
It would be more efficient to transform the data in CoSort (outside the database) if you have hundreds of thousands or millions of rows. The transforms it supports are shown in http://www.iri.com/solutions/data-transformation, along with the reasons why it’s faster. CoSort is a high-performance data movement and manipulation utility that runs in the file system (or if used in IRI Voracity for ETL, also in Hadoop) with I/O and memory-optimized, multi-threaded techniques atop specialized algorithms for sorting, joining, and aggregation that can be combined in a single pass. The language of CoSort, SortCL, is similar to SQL, but is actually easier to write and maintain (and works in the file system), and can be generated automatically by new job wizards in the free IRI Workbench GUI, built on Eclipse. In addition to running about 10 times faster with CoSort, new metadata conversion software from AnalytiX DS can also convert SQL jobs into SortCL script.