 Business Intelligence (BI)
Business Intelligence (BI)
Multiply Aggregation
As CoSort users have known for a long time, the Sort Control Language (SortCL) program supports multi-level, conditional aggregation functions on a static or running basis. Read More
Business Intelligence (BI)
As CoSort users have known for a long time, the Sort Control Language (SortCL) program supports multi-level, conditional aggregation functions on a static or running basis. Read More
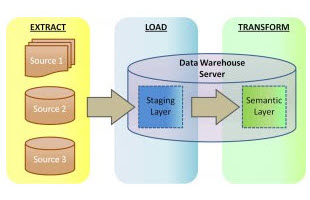 Data Transformation
Data Transformation
Full disclosure: As this article is authored by an ETL-centric company with its strong suit in manipulating big data outside of databases, what follows will not seem objective to many. Read More
 Data Masking/Protection
Data Masking/Protection
Abstract: This article explains a method of protecting credit card data with tokenization using the IRI FieldShield data masking tool.
Submitting one’s credit card details electronically can be disconcerting (e.g., Read More
 Test Data
Test Data
This article discusses the generation of computationally valid social security numbers for the purposes of testing applications specific to Korean business interests. If you are interested in US social security number test data generation, see this article. Read More
 Big Data
Big Data
Data profiling, or data discovery, refers to the process of obtaining information from, and descriptive statistics about, various sources of data. The purpose of data profiling is to get a better understanding of the content of data, as well as its structure, relationships, and current levels of accuracy and integrity. Read More
 Business Intelligence (BI)
Business Intelligence (BI)
There are many proven business intelligence and analytic tools on the market than can transform raw data into meaningful information. Because this process can be complex and involve large volumes of data however, it makes sense to use the right technologies at each step in the process … tools and techniques that combine well to deliver the fastest, most accurate results for business decision making, and make the process of metadata management and report design simpler and more efficient. Read More
 Big Data
Big Data
Note: This article was originally drafted in 2015, but was updated in 2019 to reflect new integration between IRI Voracity and Knime (for Konstanz Information Miner), now the most powerful open source data mining platform available. Read More
 Test Data
Test Data
Database and solution architects depend on realistic test data to:
help create new databases, prototype ETL jobs or applications benchmark performance in new or existing platforms stress-test systems protect confidential information in existing systems if database work is outsourced or used for demonstrations. Read More Data Masking/Protection
Data Masking/Protection
The increasing sophistication of software applications and the expanding role of database testers require high volumes of high quality, realistic test data that can faithfully represent existing, and stress-test new, platforms. Read More
 Business Intelligence (BI)
Business Intelligence (BI)
There are a number of business intelligence tools available today than can transform raw data into meaningful information. Because this process can be complex and involve large volumes of data however, it makes sense to use the right technologies at each step in the process … tools and techniques that combine well to deliver the fastest, most accurate results for business decision making, and make the process of metadata management and report design simpler and more efficient. Read More
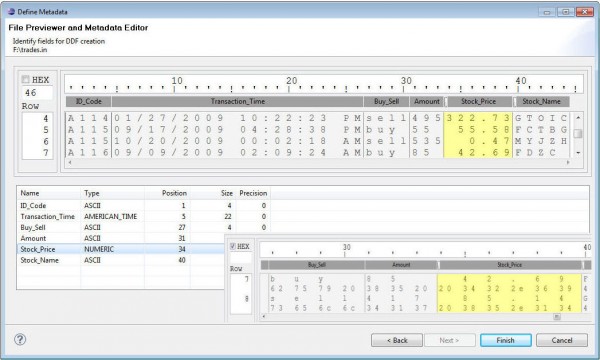 Data Masking/Protection
Data Masking/Protection
IRI’s data management tools share a familiar and self-documenting metadata language called SortCL. All these tools — including CoSort, FieldShield, NextForm, and RowGen — require data definition file (DDF) layouts with /FIELD specifications for each data source so you can map your data and manage your metadata. Read More
{kind=link}