IoT & IRI – Aggregation on the Edge
As a follow-on to my introduction to IoT and MQTT, this article describes how device data collected from standard climate sensors and sent through an MQTT (Message Queuing Telemetry Transport) server can be rapidly and inexpensively pre-aggregated by a single SortCL program (in IRI CoSort) on a tiny edge device or gateway.
The resulting data (and metadata) can also feed a low-cost, high-performance hub — or enterprise IoT platform — where the larger IRI Voracity data management environment can affect more data integration, analytics, and alerts.
Advantages of IoT Computing on the Edge
As IoT devices become more prevalent, focus has shifted to the benefits of gathering and examining data while it is being generated, as close to the original source as possible. This relatively new concept is called edge analytics, which WhatIs.com defines as “an approach to data collection and analysis in which an automated analytical computation is performed on data at a sensor, network switch or other device instead of waiting for the data to be sent back to a centralized data store.”
The main advantage of edge aggregation and/or analytics is that it decreases latency in the decision-making process. Instead of using more traditional methods on previously stored data, many enterprises learned that it can be faster, easier, and more practical to process and analyze data closer to its source. These same shops discovered this just as they realized that much of their growing data volumes did not have the relevance or utility they once thought, especially the data coming from IoT devices. In fact, some of it is not worth storing at all:
“A lot of the data that comes from IoT may not necessarily be data that we need to keep at an atomic level. I think we’re all enjoying the ability to keep more data, analyze more data, and get richer and deeper insights from all of these vast volumes of information. That said, just because you can, doesn’t mean you should.” – Shawn Rogers, Quest Software
Holding onto all that data can also be costly, and involve complexity and security issues. Dealing with it on the edge precludes those issues and enables faster response times and easier places to decide what, if any, data is worth keeping. And, analytics that occurs on the edge can be performed in real-time, and thus be more useful. Finally, it can allow for more dexterity, scalability, and choices for distributing the data to various platforms, like Hadoop.
Our First Forays
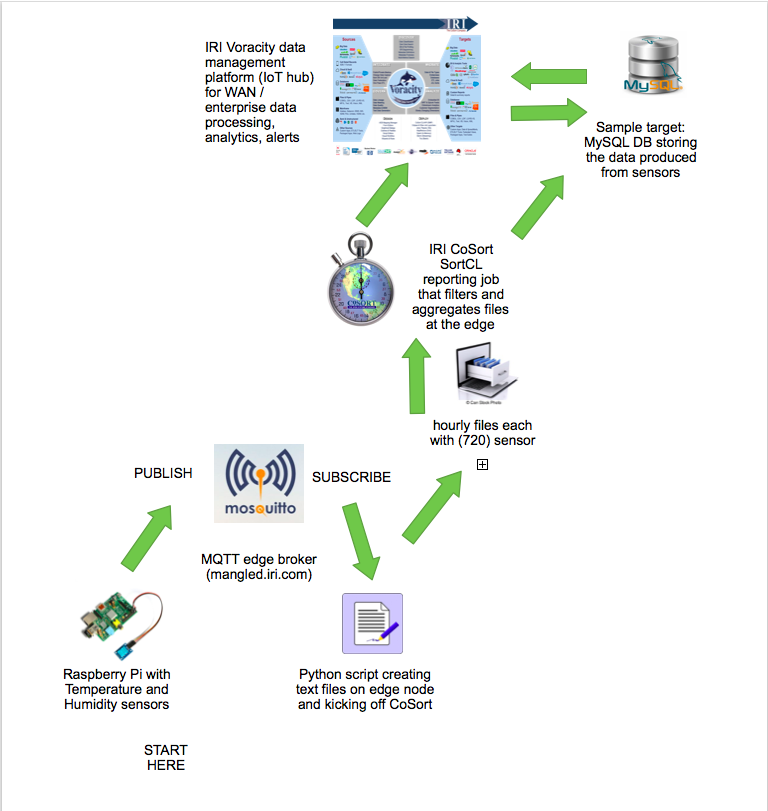
Starting at the bottom of this diagram and working up, you can see the components involved in my job, and their interaction with each other:

As you review these steps, consider how they could work in (or be modified to suit) your environment:
- A python script on a Raspberry Pi 3 Model B edge device tries to read sensor data every 5 seconds. The Raspberry Pi is a single board computer running Raspbian GNU Linux 8, attached to an HTU21DF temperature and humidity sensor.1
- If the data is read successfully, it is published to an MQTT broker, along with the timestamp of the sample, on a separate Linux system. We used the Eclipse “Mosquitto” implementation of MQTT.2
- Another python script running on the collection system subscribes to the same topic from the MQTT broker.
- Each time that the second script reads a message from the broker, it writes it to a file that corresponds to the hourly period in which it was collected.3
- When a message is received, which has a new hourly period in the timestamp, that second Python script also fires off a CoSort SortCL program that aggregates all the data in the file for the previous hour. Each file may contain up to 720 samples if there were no errors reading the sensor. This is aggregation on the edge, but SortCL can also do analytics as it reports (embedded BI), feed data directly into BIRT or Splunk, and/or prepare data for another analyzer like R or visualizer like Tableau.
Note … the Python scripts and intermediate files described in steps 3-5 above have recently been obsoleted by the CoSort v10 engine in IRI Voracity wherein streaming IoT data over MQTT feeds in real-time to SortCL processes; see the demo video below.
- The SortCL program sends the minimum, average, and maximum temperature and humidity values, along with the hourly period and the total number of samples, to a MySQL database table via ODBC.4 Note that a future version of SortCL will process MQTT streams directly, which will preclude the need for the second Python script in steps 4-6 altogether.
- Generating reports, charts, alerts, and further analysis of the SQL (or any form of streaming or persistent data) can also be performed on any downstream server running the IRI Workbench GUI for Voracity, built on Eclipse. Voracity uses CoSort or Hadoop engines for SortCL jobs in (scheduled or ad hoc) ETL workflows, making it both an enterprise data management platform and IoT hub.
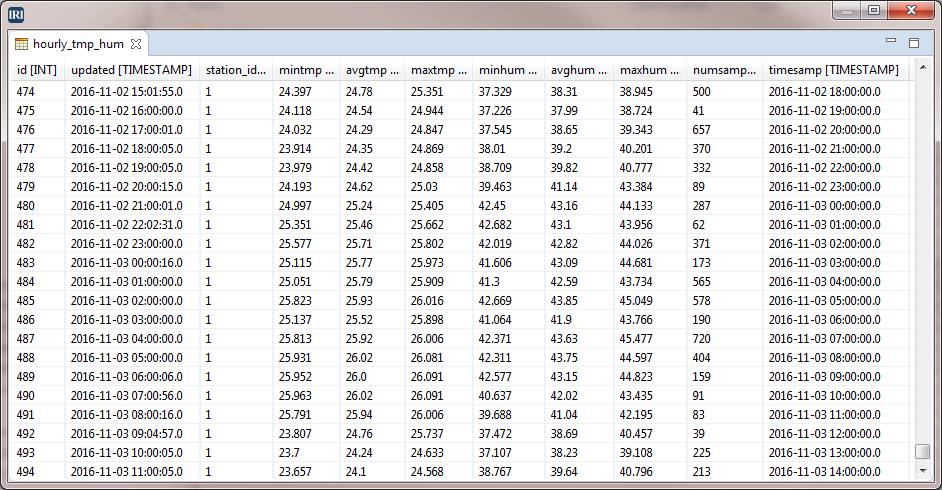
Collected aggregate data in MySQL
IRI’s Advantages on the Edge
- Lightweight CoSort SortCL applications can run wherever Linux CoSort can be licensed, from a Raspberry Pi device, to a gateway server to which multiple devices are connected. Its small command-line execution footprint means the program loads and runs quickly on the edge.
- The same SortCL script(s) can process small or large batches, or streaming data, so no design changes are needed when the processing requirement does.
- Since we are reading data from sensors, at some point in time, there might be a breakdown or communication fault at the edge. By quickly counting and aggregating the data collected in any given hour, we can spot missing entries and, nevertheless, maintain accurate summary information on any data that was registered.
- SortCL programs can filter, transform, reformat, mask data at the field level (to protect PII), generate reports, and create multiple file and table targets, all in the same job script and I/O pass. This means applications using different repositories and formats can use the same data without it needing to regenerate or synchronize it separately.
- Solutions are easier to configure and modify in SortCL than in a Python or 3GL program because SortCL uses simple 4GL. You can tweak its self-documenting parameters in text scripts, or use IRI Workbench graphical dialogs or diagrams supporting its syntax. The same data and SortCL metadata can be used in Voracity, so you do mashups and analytics on larger data sets in the hub/platform layer (see below). In a Voracity hub, those same job scripts can also run in Hadoop.
Then in the Hub …
The IRI Workbench GUI for CoSort (or Voracity), built on Eclipse, can run on any Windows box. Just set up your connection to the data stores and job scripts, wherever they happen to be. Use it to design and run the jobs, and to analyze and take action on the data being collected and aggregated.
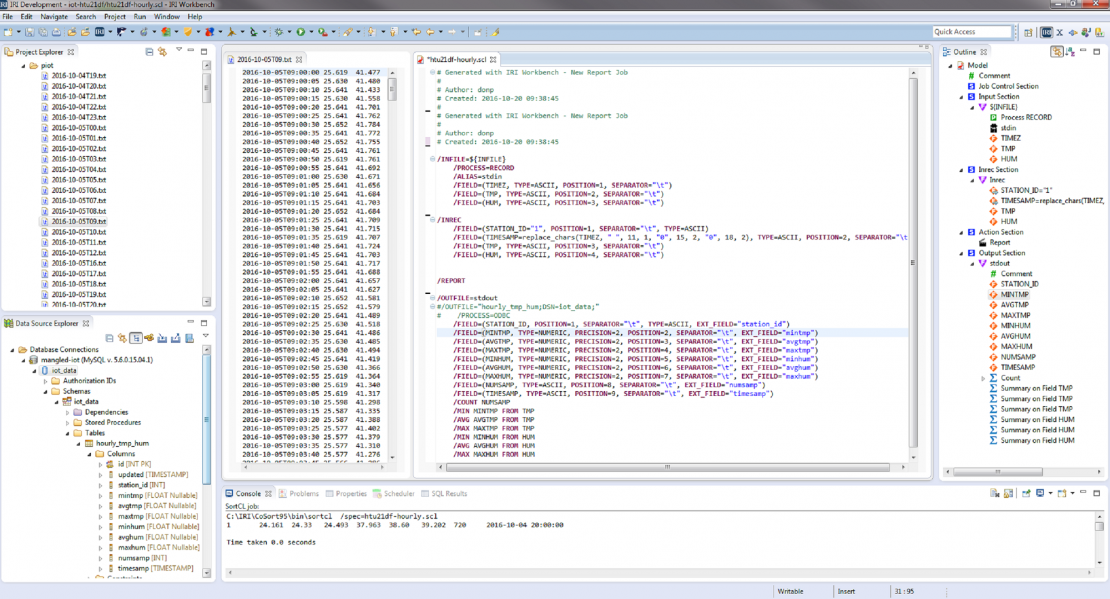
This screenshot of the IRI Workbench shows the input files, the data stored in one of them, the color-coded SortCL aggregation script (and its GUI-connected job outline), the MySQL database connection with details about the target table (lower left). The bottom console window shows the summary output of the job script.
IRI has also directly integrated SortCL data preparation with BIRT in Eclipse to produce visual analytics like this:
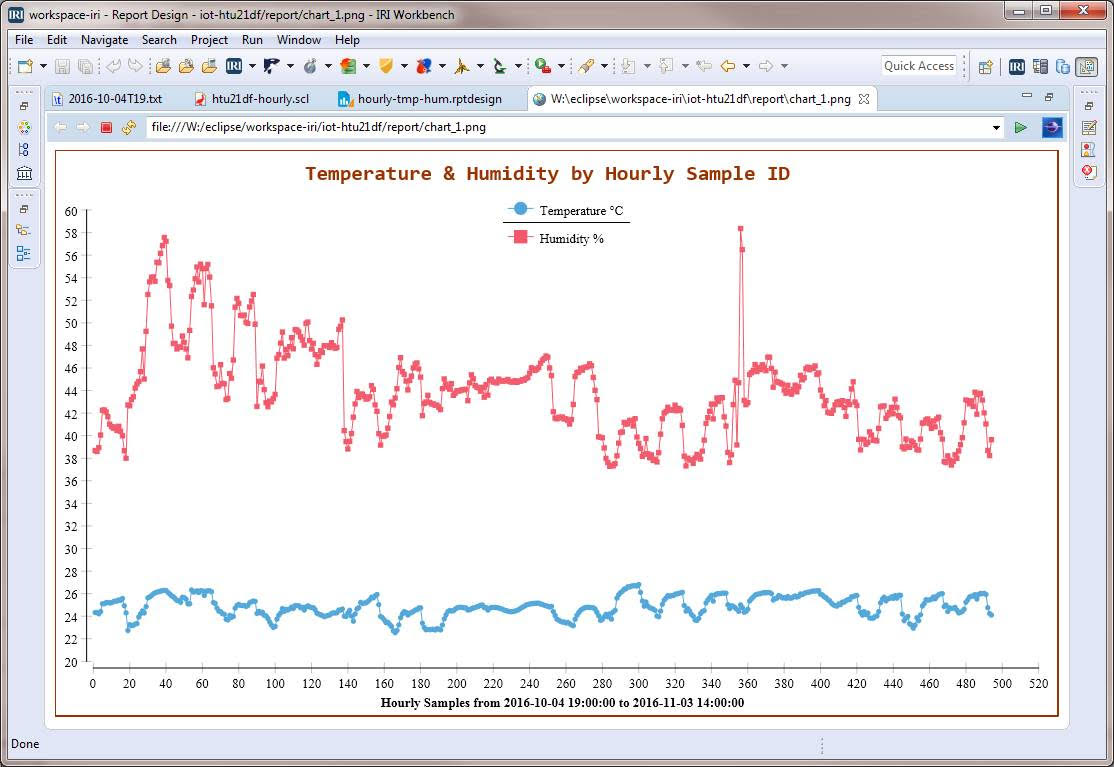
This sort of descriptive analytics can also be predictive.
Watch how IRI Voracity can aggregate IoT data on the edge in this presentation:
For more information, please contact voracity@iri.com.
- Our Raspberry Pi device is connected to an HTU21DF sensor, which uses the I2C communication protocol. I2C allows multiple ‘slave’ chips to access a ‘master’ chip. It is good for short distance communications with a single device and requires two signal wires to exchange information. In our environment, this edge node is:
• piot.iri.com – Raspberry Pi 3 Model B – Raspbian GNU/Linux 8 (Jessie) - Eclipse Mosquitto™ is an open source message broker that implements the MQTT protocol. MQTT provides a lightweight method of brokering messages using a publish/subscribe model. In our environment, the MQTT broker runs on:
• mangled.iri.com – Ubuntu 15.04 x86-64 - That simple Python script reads from the queue, and outputs the message content to a text file with sequential rows (event records). This script uses on_message() callback functionality to write the messages into a new file each hour based on the timestamp column. Theoretically, barring any sensor breakdowns, a reading occurs every five seconds, for a total of 720 event entries in each file. The Python script will call a pre-configured CoSort SortCL program to process (aggregate the data in) all the files back to any specified start date. That data quickly adds up, which is why the power of SortCL matters, and why pre-aggregation on the edge is an important efficiency step for downstream enterprise IoT analytics in the hub.
- The MySQL table structure, along with the Python and SortCL scripts, are in GitHub.










