Using the Offline Reorg Wizard
As database table and index sizes increase, data becomes more fragmented and query response slows. To improve database operating efficiency, regular table reorganization is required. See this article explaining why reorgs matter and the material below detailing the wizard’s use.
What It Is
IRI Workbench — an Eclipse IDE and GUI for all IRI software products — provides a classic (offline) reorg solution through a purpose-built wizard. The Offline Reorg Wizard facilitates the specification and execution of multiple, large-scale reorgs that keep large tables in query (e.g. join) order without taxing the database itself.
What It Does
The offline reorg wizard builds a step-by-step “Unload-Order-Reload” process, for one or more tables at once, using constituent products of the IRI Data Manager suite. For large scale reorgs, it specifies the configuration of:
- IRI FACT for bulk table unloads
- IRI CoSort for their reordering
- the target database’s load utility for pre-sorted, bulk loads
ODBC select and insert options are also available for smaller-scale or finer-tuned operations.
At the end of the wizard, the job scripts needed to reorg the selected tables are created. The jobs can run anywhere the chosen tools are licensed, and be invoked from the GUI, command line, or batch script (which the wizard also produces). Database users are unaffected in the offline reorg method, although reloads or ODBC updates can alter tables in use.
How It Works
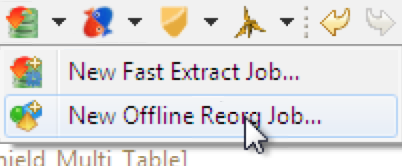
To start the offline reorg wizard in IRI Workbench, navigate to the drop-down list in the FACT menu and select “New Offline Reorg Job…”.
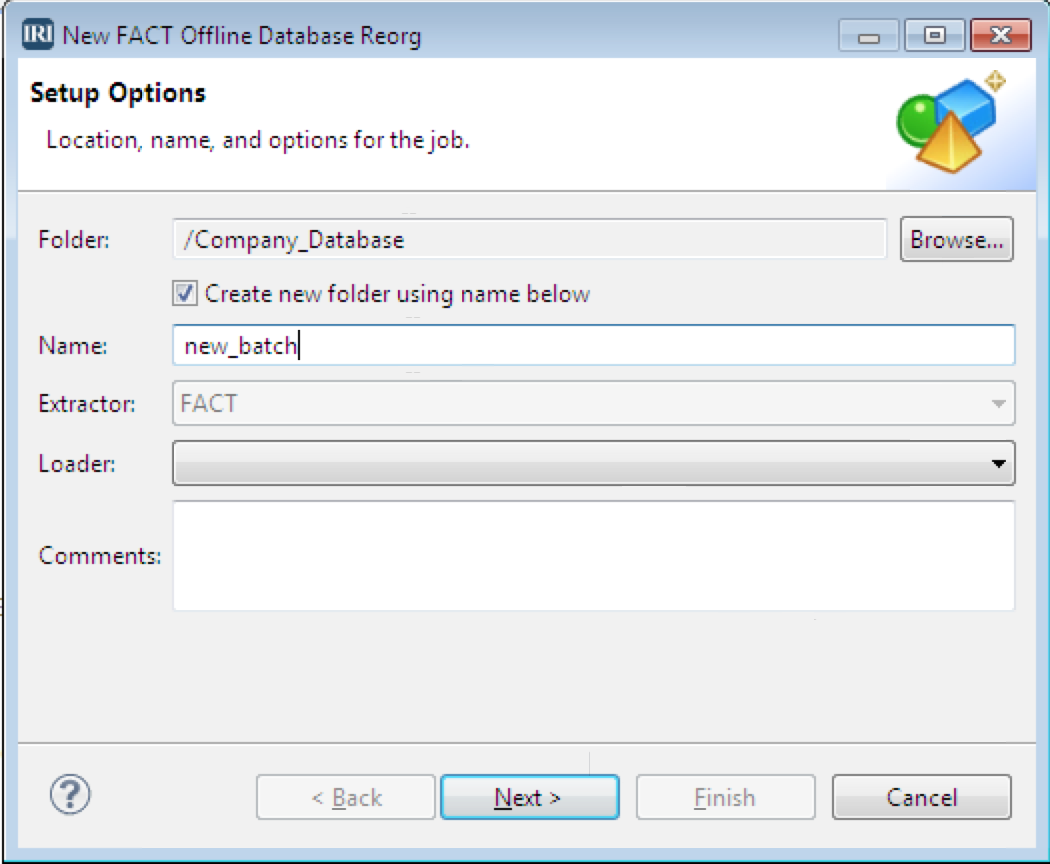
In the first dialog, choose the project folder and name a sub-folder to hold the reorg metadata and sorted results, then specify the table acquisition (unload) and repopulation (load) method.
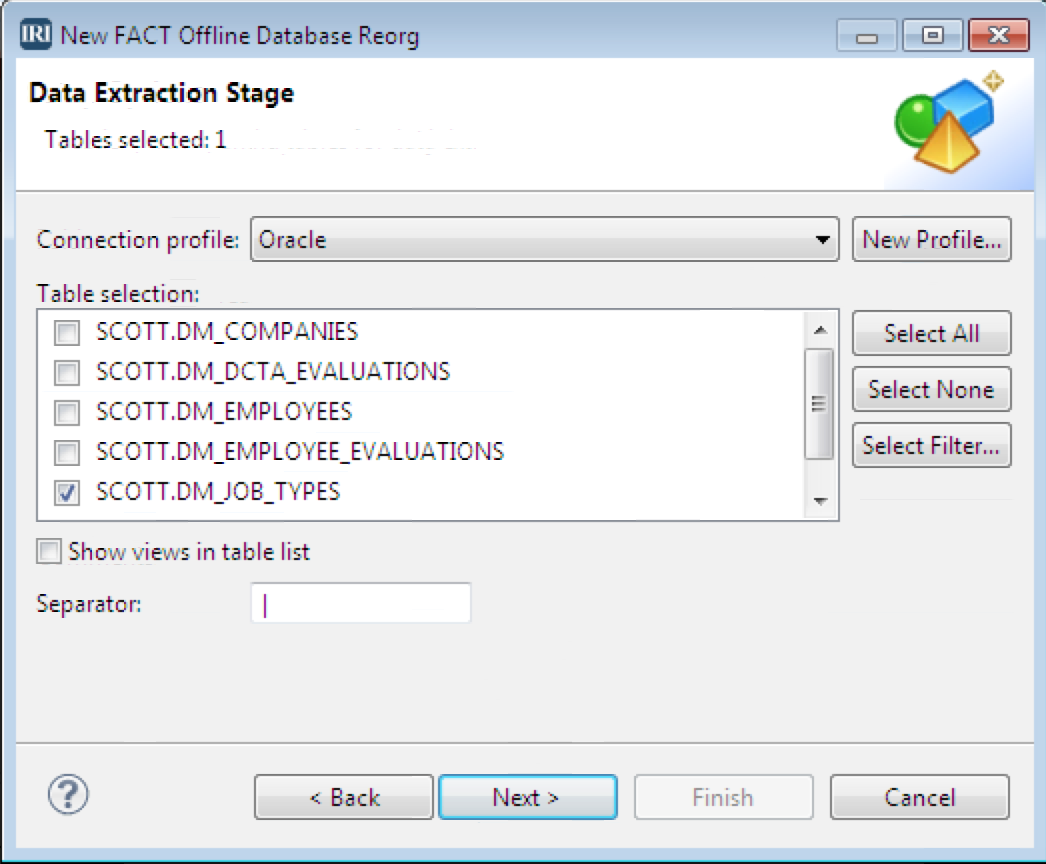
Next is the Data Extraction (unload) Stage. The available database profiles may depend upon what you chose on the previous page in the Extraction field. Select the database from the connection file, and the tables you wish to reorg from those available in the selection window:
Next is the Data Loading Stage, where you specify the target table’s details. Choose the connection profile, schema names, and applicable options for the repopulation (in this case via Oracle SQL*Loader). Click finish to automatically build all the scripts you will need to run the reorg(s).
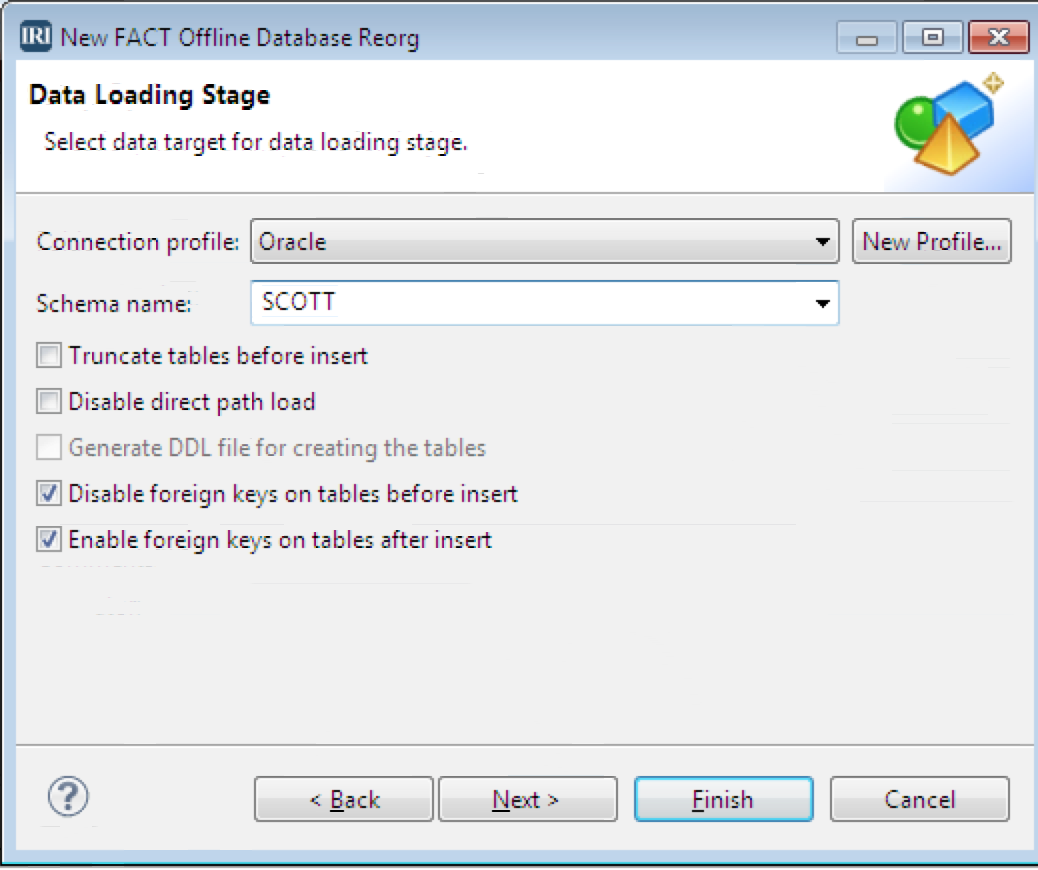
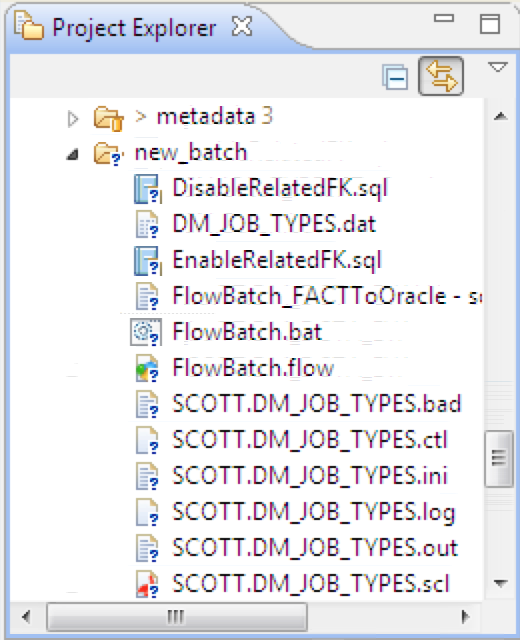
This process produced the files necessary to automatically reorganize only the JOB_TYPES table offline. The unload (FACT .ini), sort (CoSort .scl), and reload (Oracle .ctl) scripts, and ancillary files, are produced along with the batch script necessary to run it all. The .sql files preserve the constraints, and the .flow file supports a visual representation of the workflow in a separate view.
When the batch script (FlowBatch.bat) is run, a table containing the re-sorted data for loading is produced. Following is a view of the table before and after reorganization:
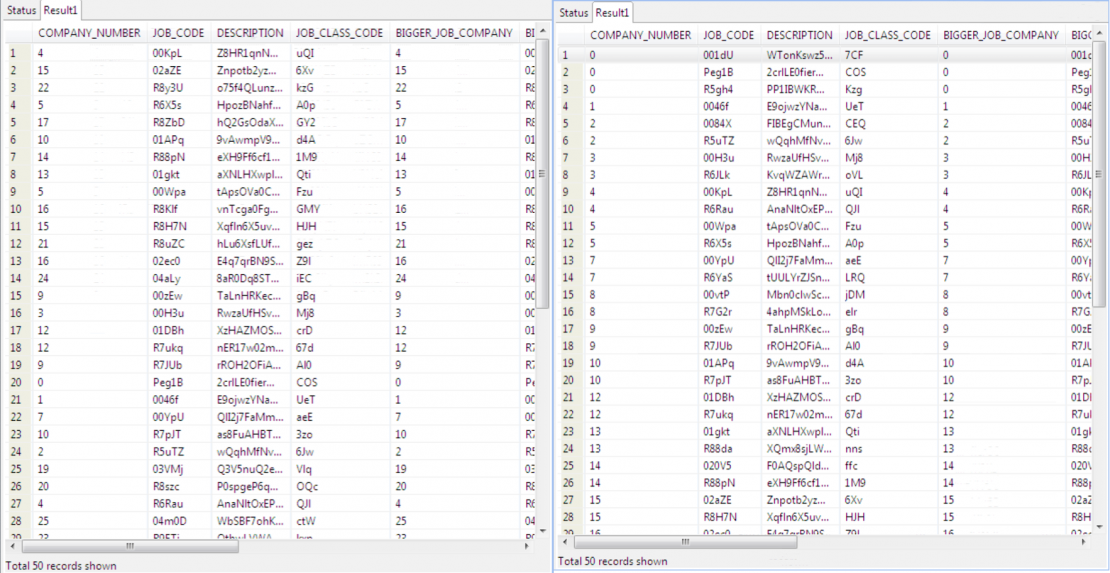
The number of items is the same, but the reorg wizard sorted the table on its primary key by default. You can change the sort key(s) in the .scl job (by hand or through the GUI), if you need the table reordered on another (lookup) column.
Contact info@iri.com if you have any questions about how this wizard works, or if you need access to a demo or these components of the IRI Data Manager suite.