Data Wrangling for Oracle Visualization Desktop
Oracle Data Visualization Desktop, Oracle DV or DVD for short, is business intelligence (BI) software that can organize, aggregate, and visualize data for informational outcomes. What seems to make this BI software unique is its ability to create slideshow presentations from its different visualizations.
Like other BI tools, Oracle DV must establish a connection with file or database table sources. Rather than directly read a file or database table, Oracle DV creates its own datasets from the raw data for use in numerous projects with different visuals and aggregations.
I found that this creation process is the most time consuming aspect in the use of Oracle DV. And, extra process time can also occur from dataset read and aggregation failures. These issues are common during normal operation but are unpredictable as to when or why they happen. I had the same failures occur in both large and small data sets using the same aggregation but they would not appear every time. These issues can normally be fixed by reloading or “refreshing” the dataset or aggregation. It takes about the same amount of time to reload the data as it did to create, thus effectively doubling the total process time.
So as with most other BI and analytic tools on the market, it was apparent that pre-wrangling, blending, or otherwise preparing data outside of DV would be beneficial. My goal for this article is to compare the relative time-to-display in Oracle DV using both native processing capabilities and external SortCL program jobs in the IRI CoSort data processing package. SortCL is also the default manipulation engine in the IRI Voracity data management (data integration, governance, wrangling) platform. The short answer is that again, yes, in volume, external wrangling is better.
Test Environment
I tested CSV files of various sizes and tables from an Oracle 11 database on a Windows 64 bit environment. My test files contained three transaction items: department, store number, and the sales by that store and department. This is meant to simulate data for a department store where sales are tallied by department and by store.
Pre-Processing in CoSort
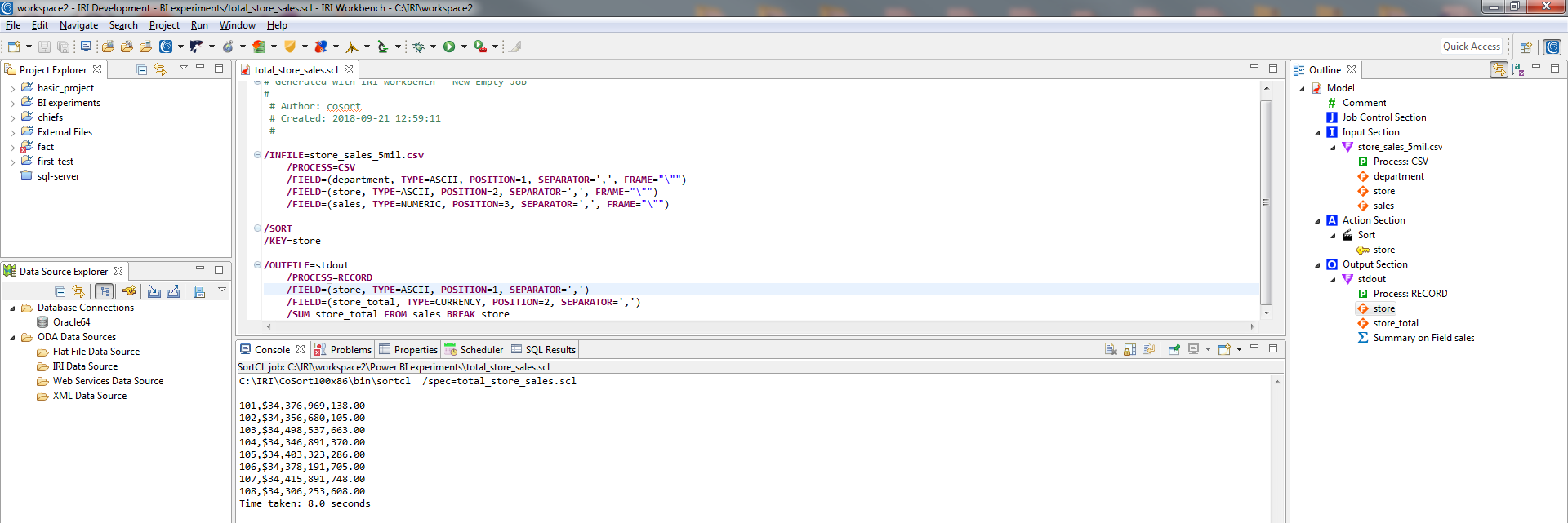
To read and wrangle data in CSV and other sources using SortCL is fairly simple. I used IRI Workbench to create a project and SortCL task to sort and aggregate a CSV data set containing sales information; i.e., to produce a result set that contained the total sales for each store.
To create my SortCL job — which serializes as a text-based .scl script — I ran the ‘new sort job’ wizard in IRI Workbench. The wizard prompts me to select my input data, auto-create its metadata, define the sort key(s), and define the output, where I specify my aggregation rule to the target sales column to sum the sales for each store. After the script is built, I can run it in or outside Workbench; it uses the command-line sortcl* executable.
My final job script and output data are shown in this Workbench screenshot:
The steps to read and process data from database tables are just as simple as they are for flat files. The only difference is that your database needs to be connected via ODBC and JDBC for SortCL and Workbench to interact with the tables, respectively. In such cases, a script might contain these source specification lines instead:
/INFILE=”SCOTT.FIVEMILTABLE;DSN=Oracle64;”
/PROCESS=ODBC
Pre-Processing in Oracle DV
Here are the steps to create a visualization in Oracle DV. To begin, a data source must be selected to create a dataset.
From here, you can select a file or table from a variety of database and storage applications. In my example, I am selecting a CSV file. After my file is selected, Oracle will create a dataset from it, which can also be edited before being used in a project.
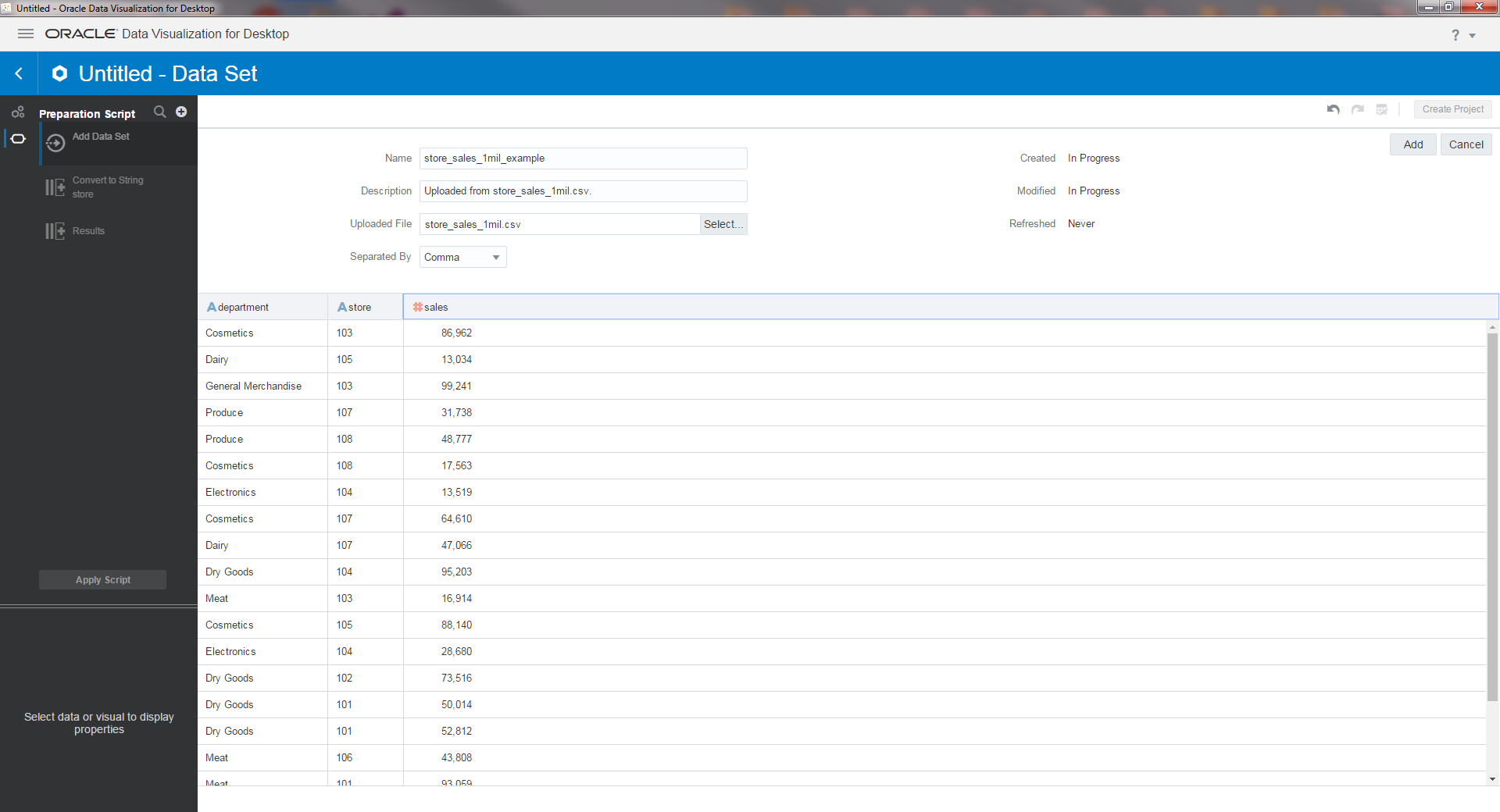
After this page is completed, the data set is now ready to use in a project. Creating a new project asks which dataset you would like to use:
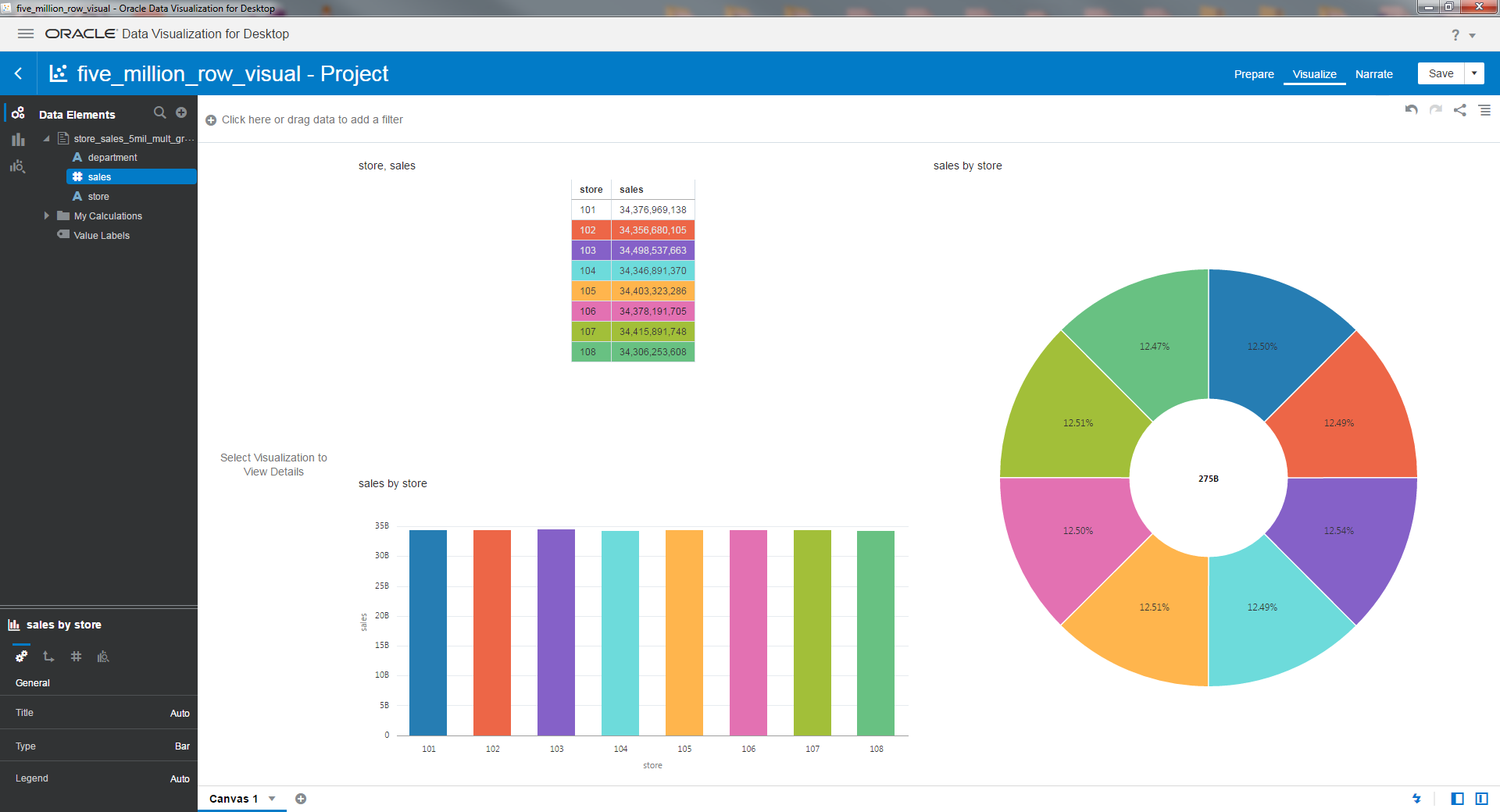
Relative Speed Tables
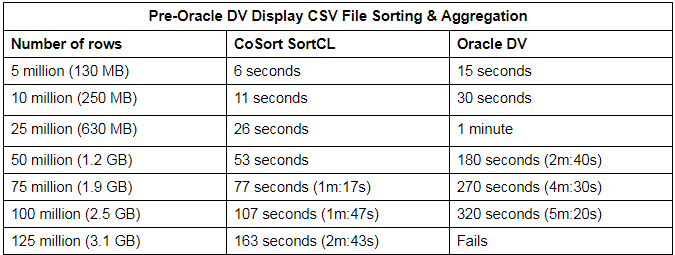
Following are the results of my simple data wrangling tests for both CoSort and Oracle DV. These tables show the time differences to sort and total the same data sets at different input volumes; i.e., before their summary results render visually in Oracle DV.
For Oracle DV, the time needed to create the dataset is also included in the total process time, as that is required to perform any aggregation, visualization, or other process.
As stated, “refreshing” is often necessary for Oracle DV to work correctly. Without refreshing, aggregations will not run, and the visualization will not display properly. However, the need to refresh is infrequent, and varies in duration when reading files. For this reason, refreshes were not included in the total time I allotted for Oracle DV.
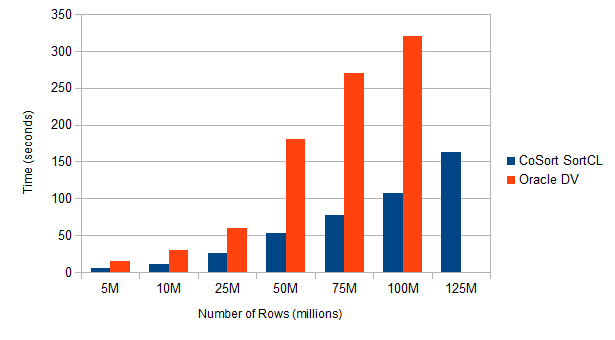
My results show that CoSort SortCL is up to three times faster than Oracle DV at reading flat files. It also shows that Oracle DV fails to read past a certain size.
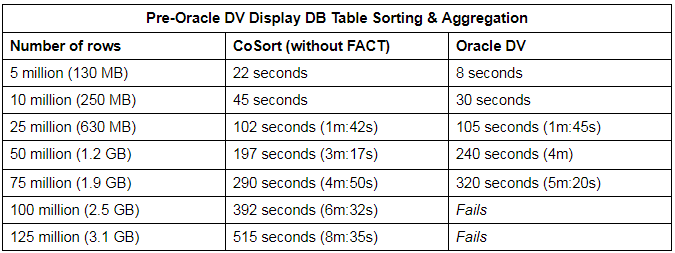
In my next round of tests, I used an Oracle XE database source table of various row sizes to see how both programs would fare. Unlike the previous exercise, the refresh times are included in the total time for Oracle DV, as it consistently needs a refresh every time a dataset is created.
After the initial refresh of a dataset from a database table, another refresh will normally not be needed for future projects. However, if any changes are made to the original table, the Oracle DV dataset will need to be refreshed again.
What these results show is that Oracle reads the data faster using OCI than CoSort SortCL does using ODBC at first — though that should change with the addition of IRI Fast Extract (FACT), which I did not use. Like before, beyond a certain volume Oracle DV could not process the data, while CoSort performance scaled linearly.
Big Data Breakdown(s)
Through my experiments, I found that Oracle DV struggles with large input data volumes. Reading files around 1.5 GB was where Oracle DV began to slow down, and broke down on files larger than 2.5 GB on my computer. Files larger than that caused a runtime error to be displayed after about 5-6 minutes.
As file sizes came closer to the 2.5 GB limit, the visualizer began to have issues using the datasets in a project. Projects sometimes failed to correctly read in a data set and required a “refresh” of the data set. Refreshes may also be needed when visualizations or tables fail to display. Though they normally fixed the problem, refreshes can just as long to complete as creating the original dataset. Thus refreshes can effectively double if not triple the total time Oracle DV takes to prepare source data, sort and aggregate it in this case, for display.
In my largest example of 100 million rows (2.5GB), it took Oracle DV 5m:10s to read in the CSV file and create its data source. Once I created my project and set my data source, I used the store and sales rows to create a table showing the summary of sales for each store. It took close to another five minutes to reload the source data so that those results could be displayed. That’s over a total of ten minutes to complete, compared to SortCL which took just under two minutes to do it once.
As for database table reads, Oracle DV was only faster until a certain point, and fails to process or read any table larger than 2GB. Database table reads also have an issue where the created dataset must be reloaded in order to work properly. However, once the dataset is refreshed, another one will not be needed unless the source database table is modified.
Conclusion
The SortCL program in IRI CoSort or Voracity can improve the reliability of, and the time to display in, Oracle DV by processing larger data sources externally. As my simple comparisons demonstrate, SortCL took only seconds to sort, aggregate, and write its results into a file or table that Oracle DV can display, whereas Oracle DV always took longer, and failed in volume.
A best practice for BI architects with high volume data sources is to employ a high-performance data wrangling tool to handle these preparatory workloads ahead of time. In other words, use a fast, fit-for-purpose data manipulation program like SortCL externally, and then analyze the results in the visualization tool you prefer.










