
Keeping AI Models GDPR-Compliant with Data Masking
Maintaining GDPR compliance while creating AI models doesn’t have to feel impossible. The key lies in using GDPR data masking techniques, which safeguard privacy without hurting how well models work.
Why AI Privacy is Now a Bigger Deal
Companies training AI with personal data deal with tough compliance challenges. Breaking GDPR rules can mean fines as high as 4% of yearly revenue, which could put entire projects at risk. Strong data anonymization methods can reduce privacy risks while keeping the data useful.
Key Techniques of GDPR Data Masking
- Tokenization swaps out sensitive information for safer placeholders but ensures the relationships in the data stay intact for effective AI training.
- Format-preserving encryption keeps data looking the same as it did. This prevents AI systems from noticing that any changes were made.
- Synthetic data generation makes fake datasets that behave like real ones but do not expose anyone’s personal details.
- Pseudonymization replaces personal identifiers with fake ones to connect data while keeping individuals anonymous.

For more information about these functions, please review the tabbed pages in this section.
Using Data Anonymization in AI Workflows
AI teams today must add privacy protections into their usual workflows. To achieve this , they should focus on a few key steps.
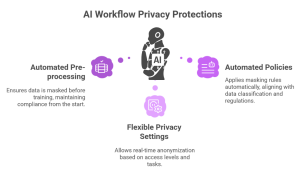
- Automated pre-processing: Mask data before it enters training systems to follow rules right from the start.
- Flexible privacy settings: Set up live tools to anonymize data based on the access level or task needed.
- Automated Policies in Action: Use tools that apply masking rules automatically. These rules match the data’s classification and meet the needs of regulations.
Note that the IRI DarkShield data masking tool is specifically designed for structured, semi-structured, and unstructured file and database data sources that feed AI models. It enables the consistent, automated application of deterministic or non-deterministic data masking rules. These rules are based on privacy settings and are associated with predefined data classes.
Finding the Right Balance Between Privacy and Performance
Top companies say they see very little drop in accuracy, less than 2 percent, when using high-end GDPR data masking tools. The secret lies in picking methods that keep data patterns intact but remove anything that could identify someone.

Key success steps include:
- Keeping model accuracy over 98 percent
- Making compliance audits simpler
- Cutting down on legal risks
- Ensuring data remains useful to train AI systems
Smarter Solutions for Big Business AI

Large AI projects require advanced platforms to mask data. These platforms handle policies from one place and can generate automatic compliance reports. They work with popular AI tools and include role-based controls to follow GDPR rules.
A tool like DarkShield supports multiple data anonymization techniques. This lets GRC and DevOps teams pick the right masking methods for their data sources and targets/tasks.
Frequently Asked Questions
Q: How is GDPR data masking different from deleting data?
GDPR data masking swaps out sensitive details with realistic replacements that keep statistical patterns intact. Deletion, or erasure per the Right to Be Forgotten DSAR, removes data. Masking helps keep data useful to train AI while meeting privacy rules.
Q: Do anonymization methods affect AI model accuracy?
Advanced anonymization methods aim to keep key data patterns unchanged. Any effect on accuracy is very small, often under 2%. Tools that follow GDPR masking standards protect data and still keep models performing well.
Q: What’s the smartest way to add AI privacy to current workflows?
Begin by using automated pre-processing to apply masking rules before feeding data into your AI pipeline. This approach protects privacy and avoids upsetting current development setups or causing major changes to workflows.
Q: When is it a good time to update data masking rules?
Update masking rules every three months or when introducing new data types into your AI systems. Performing frequent audits helps ensure your anonymization methods stay effective as laws change and AI projects grow.










