Masking & Mapping Data in a Snowflake Database
Finding and masking personally identifiable information (PII) in Snowflake® data warehouses works the same way in IRI FieldShield® or Voracity® installations as it does for other relational database sources. This article shows how I masked some of the columns in an online table after connecting my Snowflake warehouse in AWS to IRI Workbench.
IRI Workbench™ is the graphical IDE built on Eclipse™ for the design, deployment and sharing of data lifecycle management activities in the areas of data discovery, integration, migration, governance and analytics. Powered by fast, interchangeable IRI CoSort® or Hadoop® engines, the IRI Voracity platform and its subset IRI products cover a wide range of use cases involving:
- Data profiling, classification, and extraction
- Data migration, replication and change data capture
- Data integration for data warehouses, data lakes, and production analytics
- Embedded BI reporting, or data wrangling for visualization tools
- Data cleansing, validation, and unification
- Data masking, subsetting, and test data generation
The sample jobs filter, sort, mask and remap data selected from a Snowflake source table out to both a Snowflake target table and flat file. All the capabilities listed above share the same look and feel in Workbench.
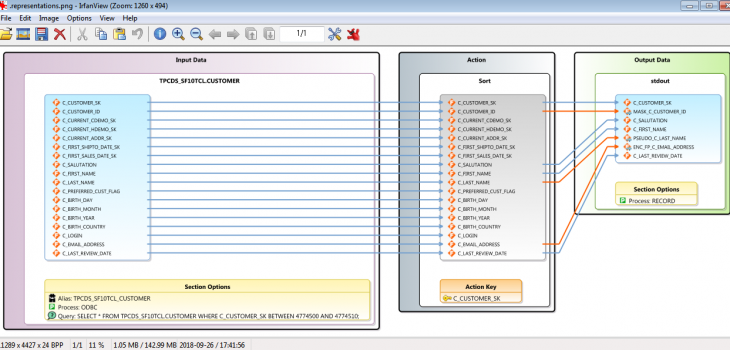
In the before/after views below, you see that I pulled seven columns out the CUSTOMER table and masked three of them. Specifically, I applied: a partial redaction (obfuscation) of the ID column, a set-lookup pseudonymization for the last name, and an AES-256 format-preserving encryption function to the email address.
This one goes from a read-only into a masked file:
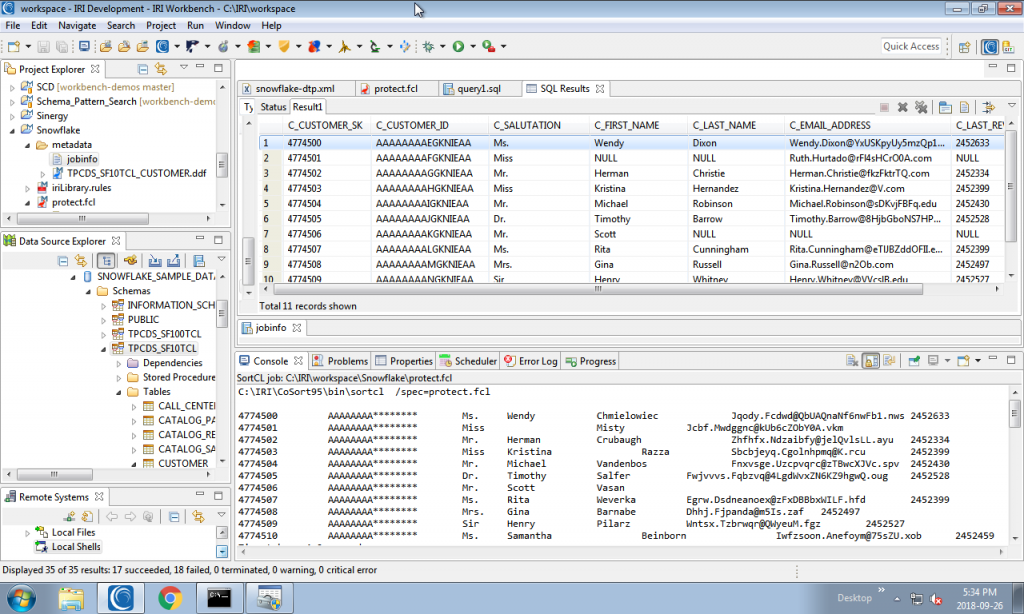
And this job takes data from a similar table in a read/write Snowflake database called IRI_POC and out to a file and another Snowflake table:
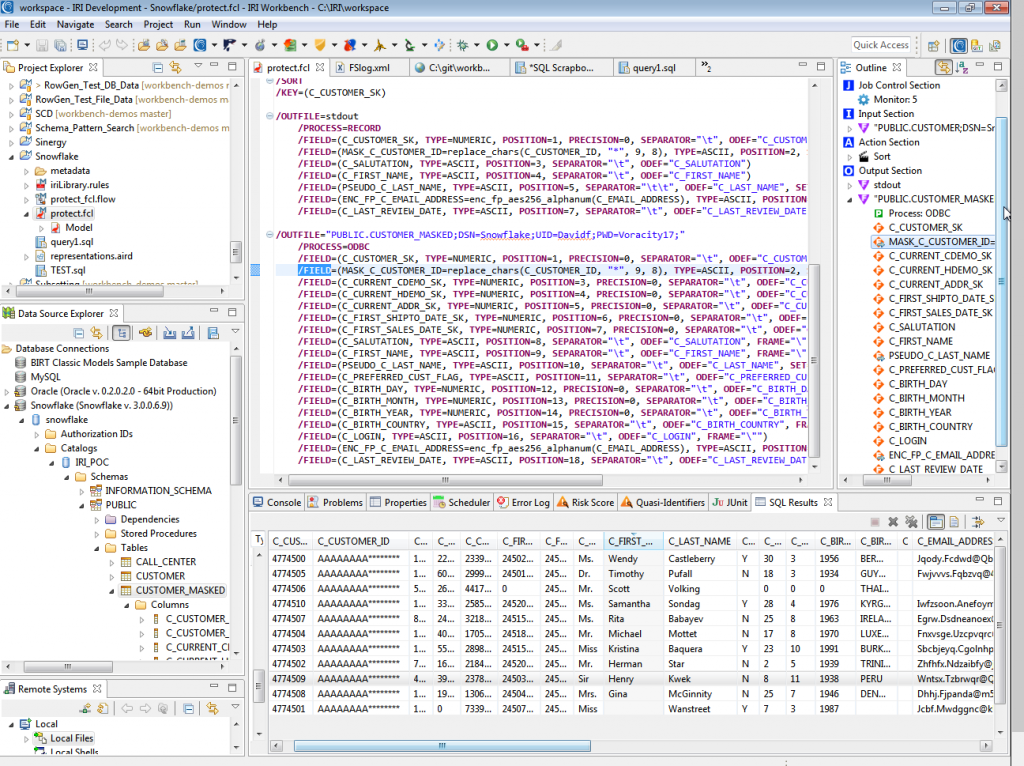
You can see my ETL/masking task specified in the 4GL job script and its interactive outline above. Though the scripts are nice to have, share, and modify by hand, there is no need to learn or hand-code them however. These “SortCL”-based jobs can be created and tweaked graphically in automatic job building wizards, dialog, and mapping diagrams like this one:
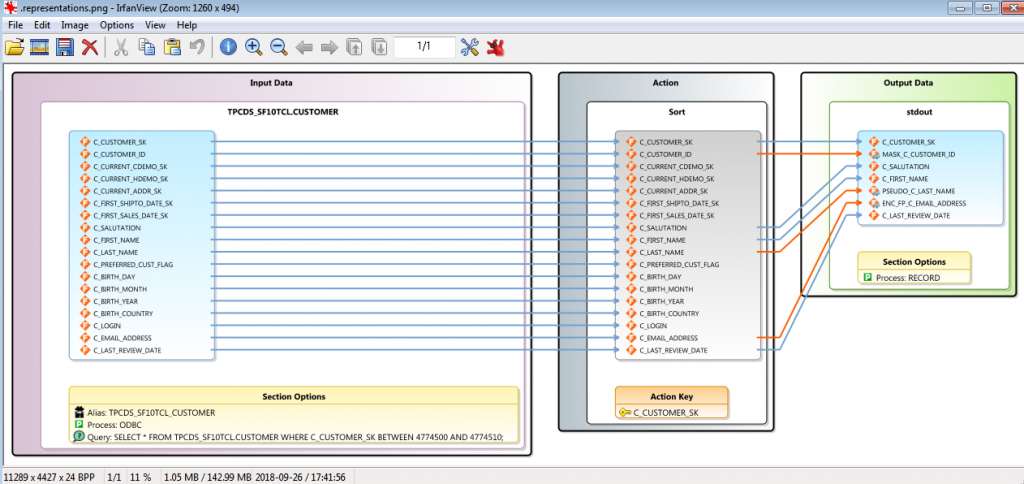
The orange connection lines indicate field derivations; in this case, masking functions. Note that this diagram shows just a few of the many data manipulation functions that can be performed and combined in a single job script and I/O pass. Process optimization and consolidation are just a few ways that IRI users can accelerate data movement and management.
In addition, multiple, multi-function task blocks like this one can be part of larger diagrammed workflows that IRI Workbench automatically serializes into Unix or Windows batch scripts. You can launch or schedule individual task scripts or batch jobs to run from Workbench, or execute them from your own command line, application, or automation tool.
Contact your IRI representative if you need help connecting or managing data from Snowflake.










