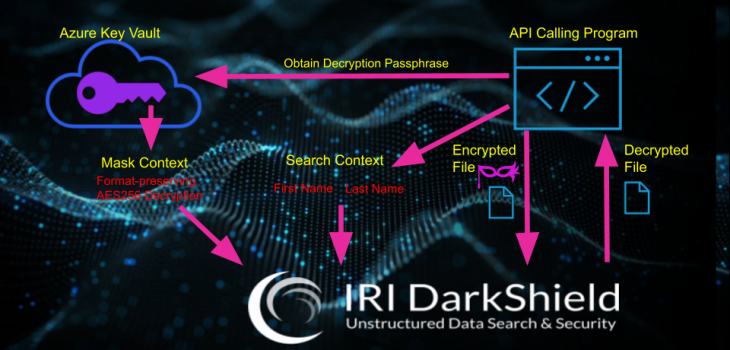
Restoring Masked Values with IRI DarkShield
IRI DarkShield data masking software focuses on discovering and masking sensitive data in a wide variety of sources, including unstructured and semi-structured files, documents, and databases. In some cases though, it may be necessary to restore masked values to their original values.
 Fortunately, reversing a masking process is possible in DarkShield, just as it is in IRI FieldShield and IRI CellShield, but only with certain encryption algorithms and search methods. In DarkShield, reversibility requires that you can find the data you masked, by matching back to either its content, or location (structure) within a specific file format.
Fortunately, reversing a masking process is possible in DarkShield, just as it is in IRI FieldShield and IRI CellShield, but only with certain encryption algorithms and search methods. In DarkShield, reversibility requires that you can find the data you masked, by matching back to either its content, or location (structure) within a specific file format.
For this article, we will use examples of the DarkShield API for Files. Refer to its description, and explanation of DarkShield search matchers in this article, for helpful background material.
When using a DarkShield search context (matcher) on the content of data, any encryption operation is irreversible. That is because the content of the text or file has now been altered, and the items that were encrypted cannot be found using the same search matchers again.1
On the other hand, search matchers that match on the specific structure of a file can be referenced again even if the text at that specific structure location has been altered due to masking. However, not all types of masking, even in this case, are reversible.
Types of reversible masking include pseudonymization and encryption. In the case of encryption, the decryption algorithm corresponding to the originally used encryption algorithm must be used, along with the exact same passphrase (key) if one was specified.
Pseudonymization is reversible when a two-column lookup, or ‘set’, file is used to store original and replacement values. A set file is a list of entries with each column separated by a tab. The first column is the list of values to match, and the second column maps each original value to a consistent replacement, or pseudonym.
To reverse pseudonymization, a similar set file can be used with the first column swapped with the second column, and the file sorted on the first column. Multi-column set files must be sorted on the first column in order to be used as a lookup table.
An example of search matchers matching on the structure of a file is shown below. These are specified in a file search context, which is a search context for use with files.
 Image demonstrating a file search context with JSON path search matchers that match on the structure of a JSON file.
Image demonstrating a file search context with JSON path search matchers that match on the structure of a JSON file.
A context only needs to be set up once, and can be referenced by the DarkShield API until it is destroyed or the server shuts down.
Decrypting Encrypted Values
In this example, any JSON keys with a name of firstName or lastName will have the associated value masked based on the masking rule associated with the matcher that gets set up in the file mask context.
This same file search context can be used for encryption or decryption. The only change needed to distinguish between encryption and decryption is the masking rule in the file mask context.
All IRI encryption algorithms follow a syntax where the first three letters of an encryption function are enc, while the first three letters of a decryption function are dec. Every IRI encryption function has an associated decryption function.
For a JSON document, values can be matched against the structure of the document using JSON path matchers. In this example, the corresponding values of all JSON keys with a name of either firstName or lastName will be matched against, regardless of the exact position or depth in the JSON structure.
Captioned images below detail the process of encrypting and decrypting values in a JSON document.
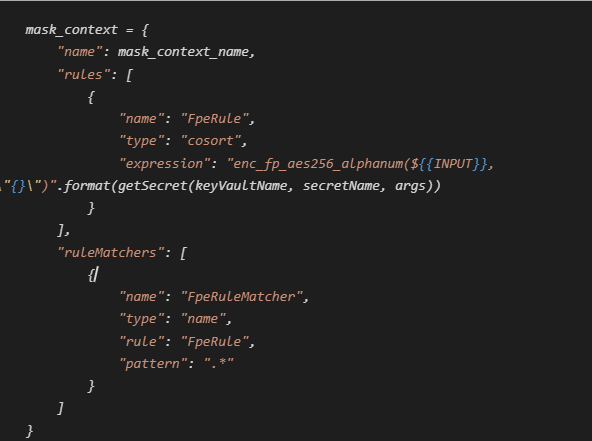 Image of a DarkShield API masking context that associates every search matcher with a masking rule to encrypt values with AES-256 alphanumeric format-preserving encryption using an encryption passphrase (key) obtained from Azure Key Vault. The same setup replacing enc with dec will decrypt values instead.
Image of a DarkShield API masking context that associates every search matcher with a masking rule to encrypt values with AES-256 alphanumeric format-preserving encryption using an encryption passphrase (key) obtained from Azure Key Vault. The same setup replacing enc with dec will decrypt values instead.
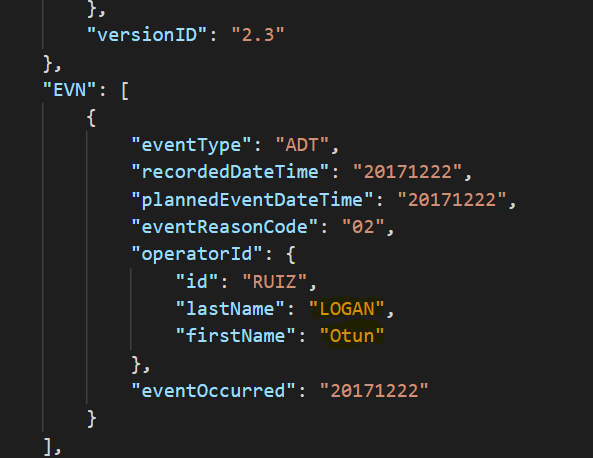 Original ADT message containing PHI in HL7/JSON EDI format
Original ADT message containing PHI in HL7/JSON EDI format
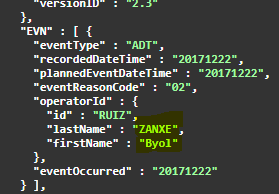 Encrypted message – first names and last names encrypted with AES-256 format-preserving encryption.
Encrypted message – first names and last names encrypted with AES-256 format-preserving encryption.
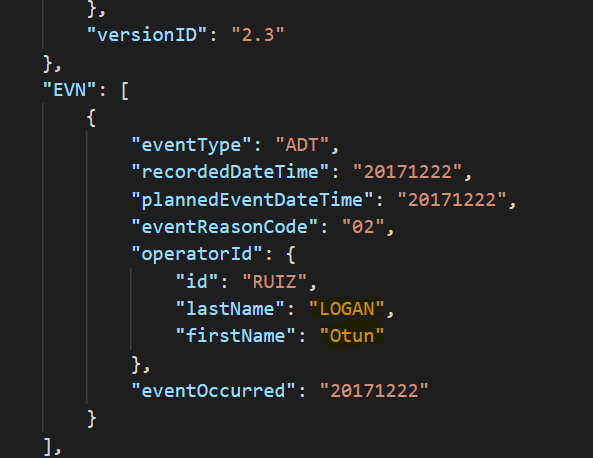 Decrypted message – Using the same setup, but with the corresponding format-preserving
Decrypted message – Using the same setup, but with the corresponding format-preserving
AES-256 decryption function and same passphrase, first names and last names can be restored
to their original values by sending the encrypted message to the DarkShield API.
Decryption can also be performed against only a portion of the values that were originally encrypted. For example, when setting up a mask context for decryption, only the search matcher for first names might be referenced in the mask context.
The encrypted file can then be sent back to the DarkShield API with a reference to the name of the decryption context. The file returned by the DarkShield API in its response will have first names decrypted, but not last names.
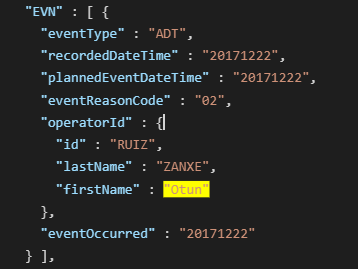 Selectively decrypted message – Using the same setup, but with the corresponding format-preserving AES-256 decryption function and same passphrase used, and the ruleMatcher set to only match against the matcher for first names, only the first names are restored to their original values when sending the encrypted message to the DarkShield API.
Selectively decrypted message – Using the same setup, but with the corresponding format-preserving AES-256 decryption function and same passphrase used, and the ruleMatcher set to only match against the matcher for first names, only the first names are restored to their original values when sending the encrypted message to the DarkShield API.
DarkShield Decryption Process Summary
To decrypt an encrypted file with DarkShield, there are several prerequisites:
- The original search matcher used must have matched on the structure of the file rather than the content of the file.
- The original encryption algorithm and encryption passphrase (if used) must be known.
- A masking context should be set up to use the corresponding decryption algorithm to the original encryption algorithm used with the original passphrase (if used). The masking context should set up a rule matcher to match the decryption algorithm with at least one structured type of search matcher that was used in the original masking of the file.
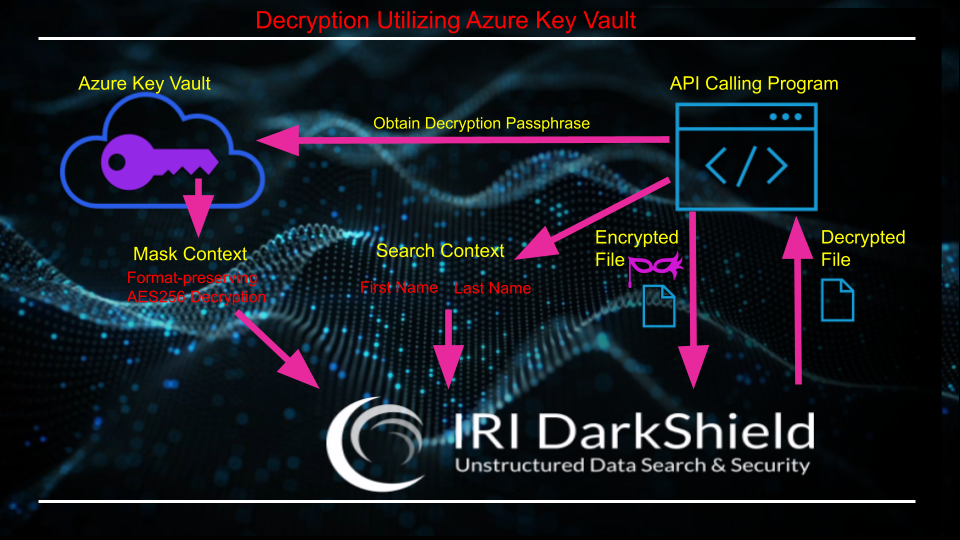
The masked file is sent to the same endpoint used to mask the original file. Even though the endpoints reference the word mask, as this is their typical use, they can be used to apply any function to data that was matched. In this case, the encrypted file is being sent instead of the original file, and the function applied decrypts (instead of encrypts) matched values.
Reversing Pseudonymization
Pseudonymization is another reversible masking method. It can be more tedious to set up than encryption in some cases, but it produces more realistic masked results, and can be reversed even when using search matchers that match on the content of data rather than just the structure of the file.
For example, I will demonstrate pseudonymization and restoration of names in an unstructured text file using the DarkShield API.
Here is the original text file, for reference:

A ‘set’ refers to a file with a series of entries. I set up a set matcher with the DarkShield API that will match on any of thousands of common names, ignoring the case of the names.
I also set up masking contexts, which define what to do with, in this case, names. I set up separate masking contexts to pseudonymize and restore names.
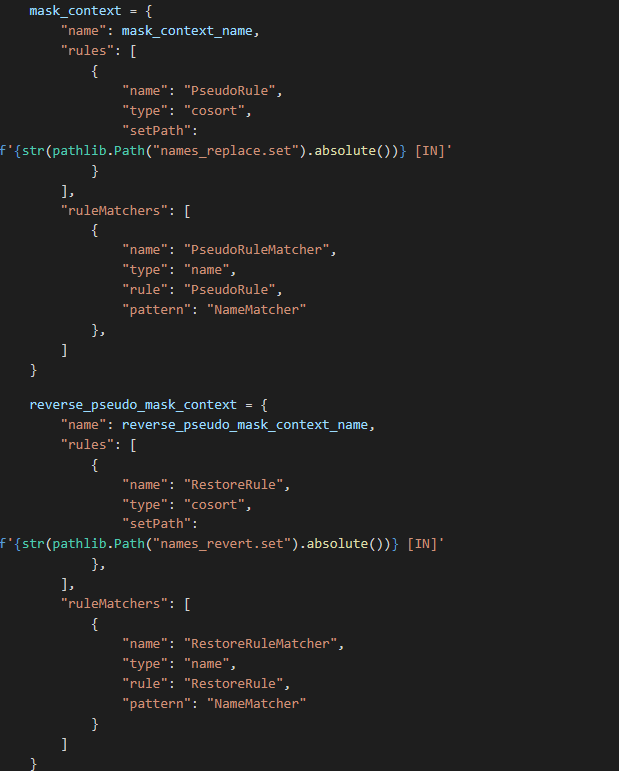 Python glue code snippet to set up masking contexts for pseudonymization and restoration of names.
Python glue code snippet to set up masking contexts for pseudonymization and restoration of names.
To set up for pseudonymization, a two-column, tab-separated file containing a list of names mapped to other names should be created. To set up for restoration, a restore file (where the first and second columns are reversed) is needed for recovery of original names. The first column of each file MUST be sorted alphabetically, and have no duplicate entries.
These ‘set’ files for pseudonymization and recovery can be produced easily from many sources of data. In this case, I created them automatically in the IRI Workbench IDE, built on Eclipse.
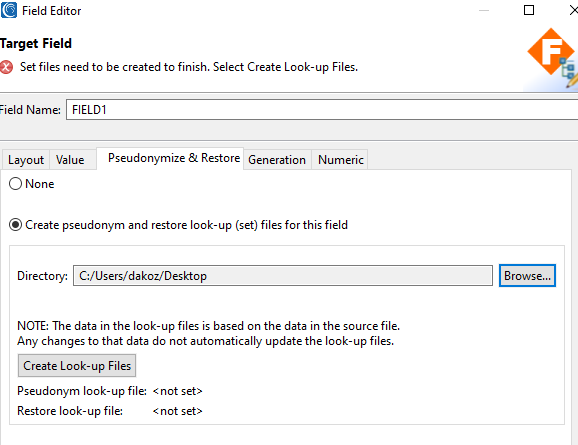 The Pseudonymize & Restore dialog in IRI Workbench can be used to generate both pseudonym and restoration look-up files from existing data sources.
The Pseudonymize & Restore dialog in IRI Workbench can be used to generate both pseudonym and restoration look-up files from existing data sources.
 Set file used to replace names consistently with other names, and to search for names in the file sent to the DarkShield API.
Set file used to replace names consistently with other names, and to search for names in the file sent to the DarkShield API.
Set file used to restore names that were pseudonymized.
 Masked file with names pseudonymized. Note that the common last name ‘Duke’ between the two names has been consistently replaced with ‘Madison’, preserving referential integrity.
Masked file with names pseudonymized. Note that the common last name ‘Duke’ between the two names has been consistently replaced with ‘Madison’, preserving referential integrity.
 Restored text file
Restored text file
DarkShield Pseudonym Reversal Process Summary
Reverse pseudonymization is another way DarkShield can reveal masked data. Pseudonymization has distinct benefits and drawbacks when compared to encryption, but one similarity between the methods is that they are both reversible.
Similarities:
- Masked values are consistently, and can thus preserve referential integrity
- Reversible
- Secure and compliant algorithms
Differences
- Pseudonymization produces more realistic masked values
- Pseudonymization is more versatile in implementation
- Pseudonymization can be more complex to set up and maintain
- Pseudonymization can be more compute-intensive given a very large set of values.
Conclusion
The ability to reverse masking depends on the type of masking function used. Some forms of masking, like redaction of characters, deletion, and black boxing sections of images, cannot be reversed.
For DarkShield, the ability to search for values that have been masked in the same way they were originally found is necessary to reverse masking.
Pseudonymization and encryption are the two most common reversible types of masking. The benefits and limitations of each method have been discussed. The demos used in this article for pseudonymization/restoration and encryption/decryption are available on GitHub.
Contact darkshield@iri.com with any questions regarding the reversal of data masked by DarkShield.










