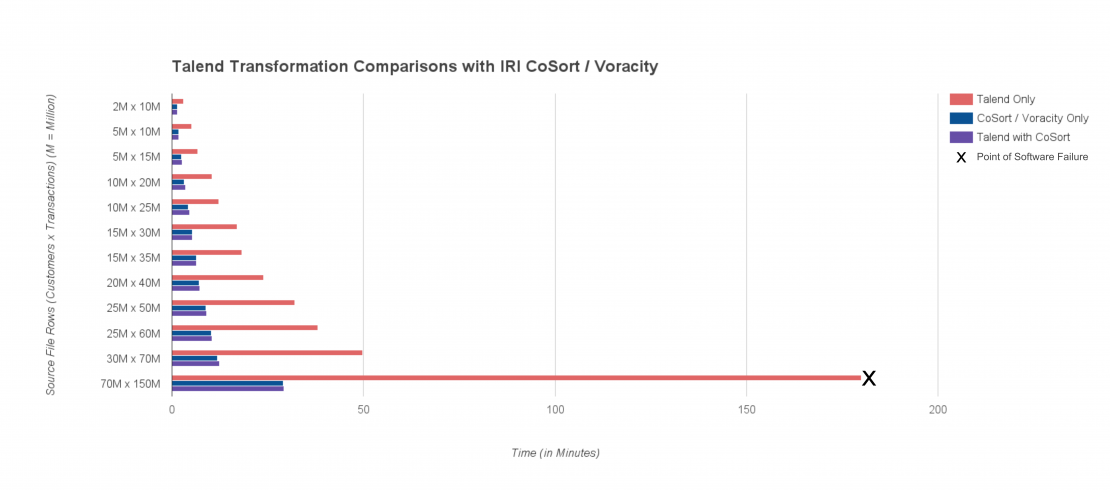
Improving Talend Performance
Talend has been on the market for several years now, and its flexible UI components make it a very reasonable choice for developers when it comes to customization. Read More
Talend has been on the market for several years now, and its flexible UI components make it a very reasonable choice for developers when it comes to customization. Read More
For the last 30 or so years, the precursor to most large scale business intelligence (BI) environments has been the Enterprise Data Warehouse (EDW). A data warehouse (DW) is usually a central database (DB) for reporting, planning, and analyzing summarized, subject-matter data integrated from disparate, historical transaction sources. Read More

Just as production data processing tools like IRI CoSort must handle big data in NoSQL DB environments, so too must a big test data generation tool like IRI RowGen. Read More
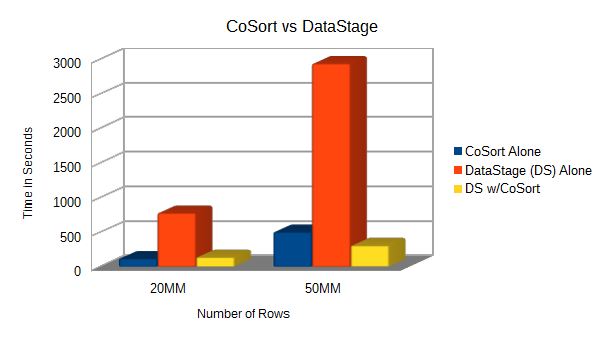
Comparing Filter/Sort/Join/Aggregate Performance
ITKeySource, an ETL consultancy in Jacksonville, FL, recently benchmarked relative performance gains running IRI CoSort — and its SortCL program in particular — alongside IBM DataStage. Read More
IRI CoSort continues to be a low-cost way to accelerate Informatica ETL via pushdown optimization, and IRI RowGen can generate safe, referentially correct test data for any EDW. Read More
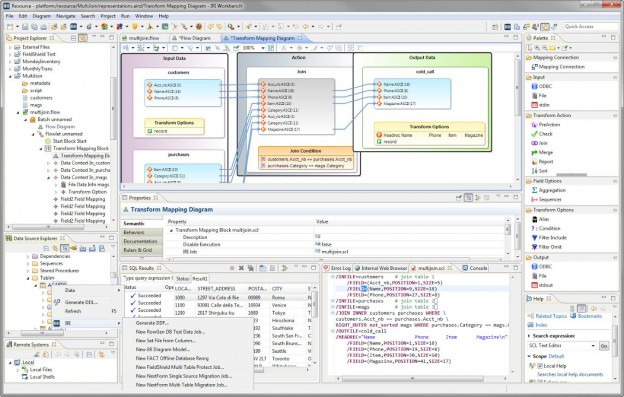
A DSN (database source name) file allows multiple users to connect to a database with information in a flat file. It is used by the database client program — in this case, software in the IRI Workbench — to connect to a database. Read More
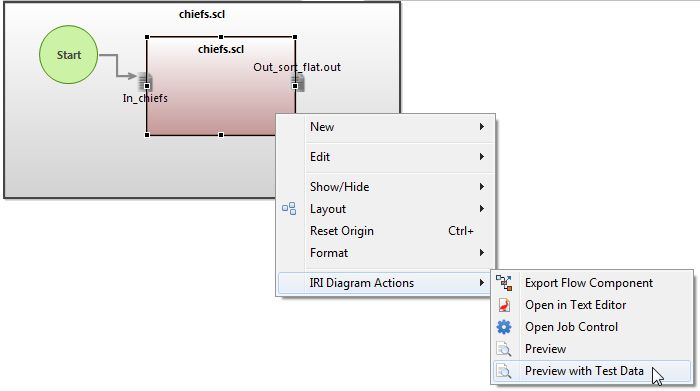
During the design of IRI Voracity workflows in the IRI Workbench (Eclipse) GUI, you can preview the results of one or more transforms before saving or running the project. Read More
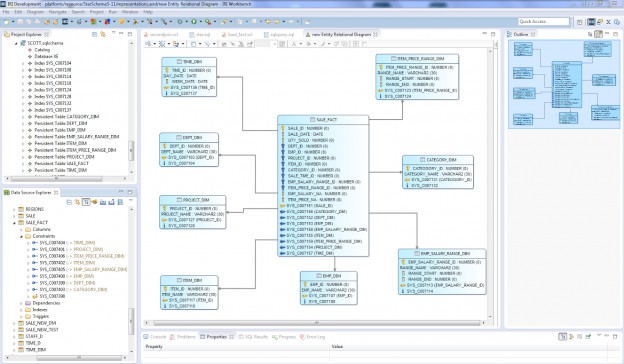
Note: This article showcases the migration of a relational database (RDB) model to star schema using the Eclipse IDE for the IRI Voracity data management platform (and its included products) called IRI Workbench, following an introduction to both types of schema. Read More
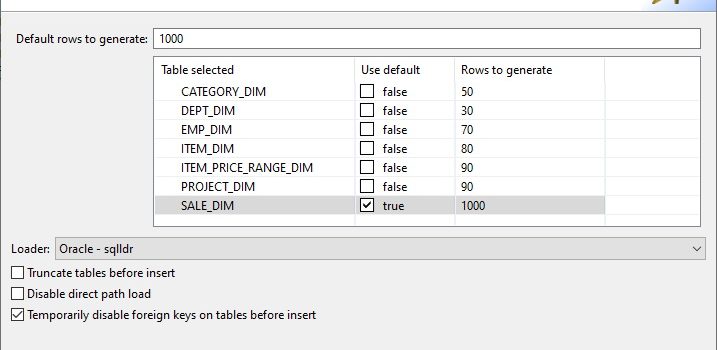
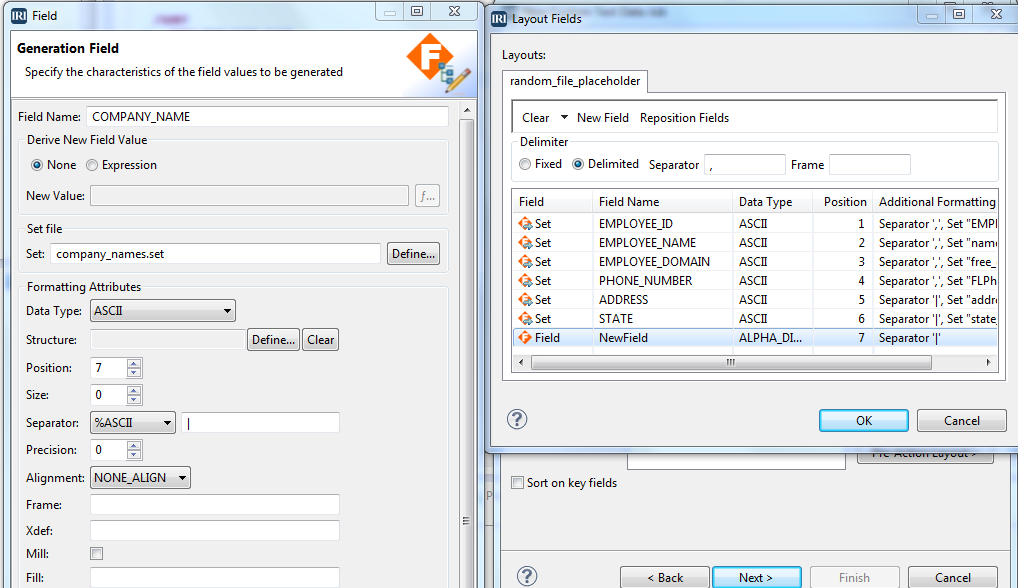
IRI RowGen users can generate structurally and referentially correct synthetic test data for an entire database in a single operation. The test data reflects production characteristics (such as values ranges and frequencies) normally encountered in database or ETL operations, but does not require access to, or the masking of, real data. Read More
XML is a popular file format because of its value in data interchange. For this reason, XML test data generation can be an important part of the Software Development Life Cycle (SDLC), particularly for those applications which need to process XML data. Read More