The Enterprise Data Warehouse, Then and Now
For the last 30 or so years, the precursor to most large scale business intelligence (BI) environments has been the Enterprise Data Warehouse (EDW). A data warehouse (DW) is usually a central database (DB) for reporting, planning, and analyzing summarized, subject-matter data integrated from disparate, historical transaction sources. An EDW uses technology to move internal and external data sources into a cross-functional DW.
The typical EDW environment includes:
- disparate storage and systems that provide the source data
- data integration and staging through extract-transform-load (ETL) processes
- data quality and governance processes to ensure the DW fulfills its purposes
- tools and applications to profile sources, feed the DW DB, and analyze the results
The basic architecture of the EDW has remained more or less as follows:

Source: Oracle Corp.
Traditional data sources are relational DB tables, flat files, and web services; but now CRM, ERP, IoT, NoSQL, social media, web log, public, and other “big data” sources are in the mix.
Unlike source OLTP DBs with normalized tables optimized for complex queries and modeled in E-R diagrams, the DW DB is denormalized for simple joins, and thus faster OLAP queries. Its data models reflect more advanced “star” or “snowflake” schema. They are also considered “nonvolatile” and “time-variant” because they produce the same reports for different periods in time. Modern EDWs and logical data warehouses (LDW) are more volatile.
Data marts are smaller, departmental-level DWs that either use subsets created from the main DW (dependent), or they are designed for one business unit (independent). The operational data store (ODS), which we’ll cover separately, is an interim DW DB, usually for customer files.
(Slightly) Deeper Dive
Though there are variations of “back room” DW/BI architectures to stage and integrate data (including extract-load-transform (ELT) and hybrids of either), IRI subscribes to the Ralph Kimball ETL convention, with BI data stores in the “front room” and presentation services in between:
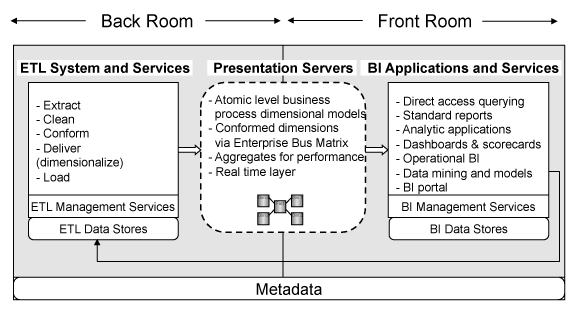
Source: The Data Warehouse Lifecycle Toolkit, Second Edition.
Beyond basic ETL vs. ELT decisions is a long list of other considerations, including the hardware and software systems running in the bottom (DW/ETL), middle (OLAP), and top (BI) job tiers of the EDW. As a threshold matter, EDWs mostly use SQL-driven relational DBs; though with data pushing into petabyte ranges, mainframes, multi-core Unix servers, and Hadoop data nodes are now the norm, along with SQL layers on NoSQL DBs like MongoDB and MarkLogic.
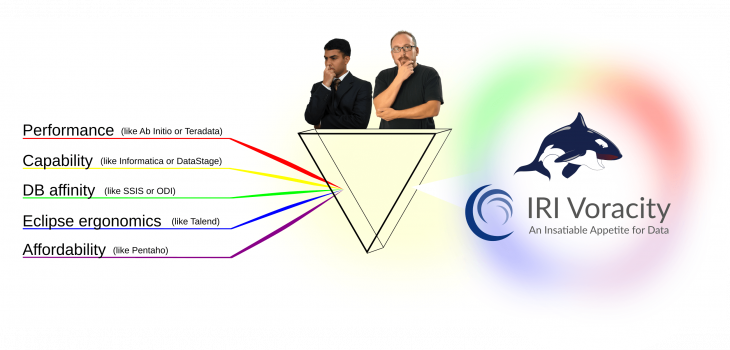
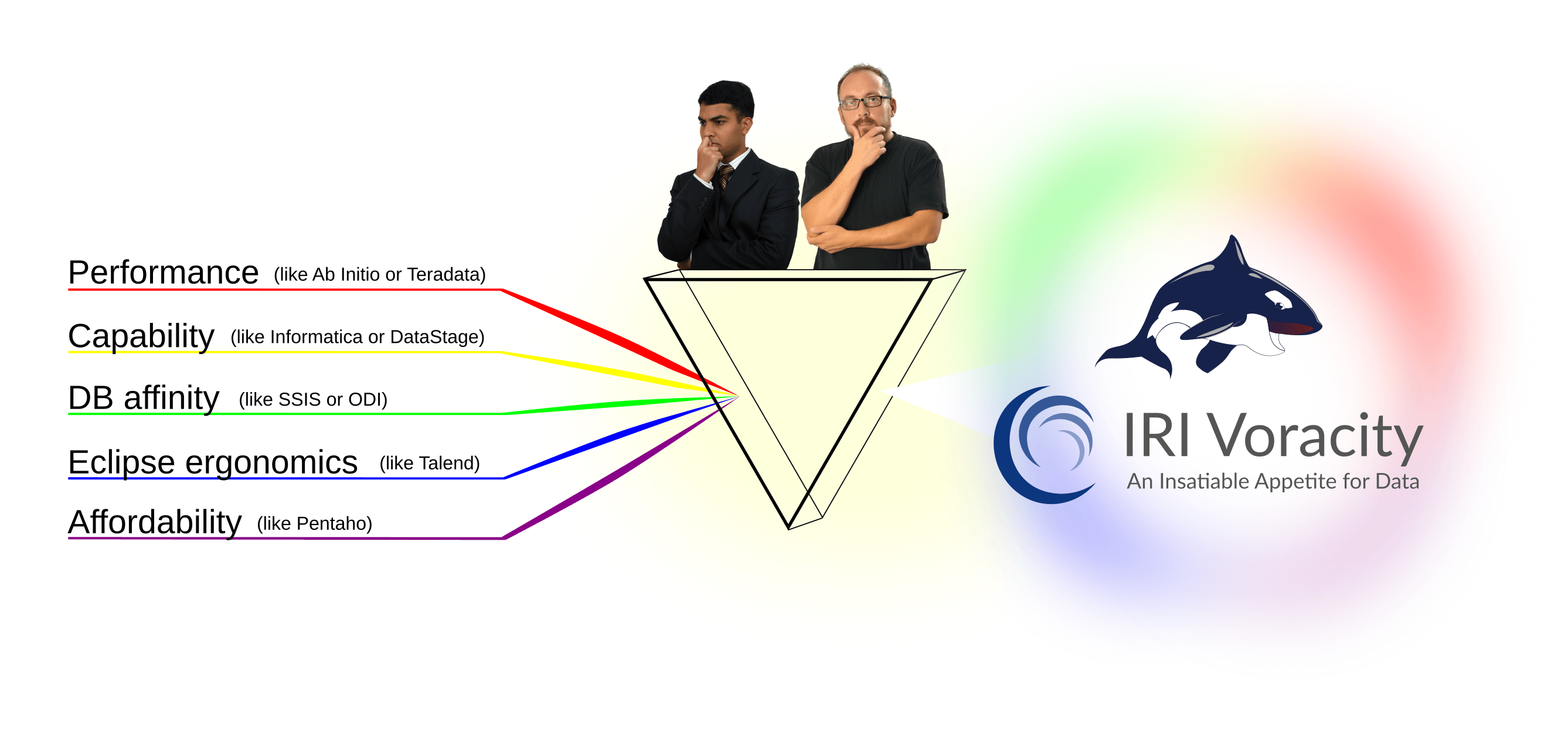
In the bottom tier, IRI Voracity and other vendor offerings handle ETL and related data delivery issues, including change data capture, migration and replication, and various ‘types’ of slowly changing dimension updates. In addition to built-in data discovery, masking, test data and BI capabilities, Voracity’s advantages lie in uniquely combining the strengths of its competitors:
In the middle tier, the choice of a MOLAP or ROLAP is usually made, where the DB is either multi-dimensional and stores “facet” views (like sales by time) in arrays, or relational, where similar results require SQL queries. MDDBs are thus faster at analytic processing, but RDBs are more common in EDWs, where BI tools feed off them in the top tier instead. Choices of both partitioning strategy and normalization form are thus often made to speed the RDB’s queries.
In the top tier, the choices for BI and data mining are virtually endless, and dictated by reporting or analytic (diagnostic, predictive, prescriptive, etc.) requirements. Here, an external data preparation solution — such as CoSort-powered data blending or munging jobs in Voracity — removes integration from the BI layer, and speeds popular visualization platforms up to 20X.
EDW Uses and Benefits
In his TechTarget article, DW consultant Craig Mullins delineated that an EDW can:
- track, manage, and improve corporate performance
- monitor and modify a marketing campaign
- review and optimize logistics and operations
- increase the efficiency and effectiveness of product management and development
- query, join, and access disparate information culled from multiple sources
- manage and enhance customer relationships
- forecast future growth, needs, and deliverable
- cleanse and improve the quality of your organization’s data.
Specific industry cases from IRI CoSort or Voracity ETL sites show DW and EDWs are used to:
- Assess call, click, and other consumption habits
- Detect insurance fraud or set rates
- Evaluate treatment outcomes and recommend drug therapies
- Manage goods inventories and shipments
- Monitor device/equipment health and service levels
- Optimize pricing and promotion decisions
- Predict crime and prevent terrorism
- Streamline staffing, fleet, and facilities.
A key technical benefit of EDWs is their separation from operational processes in production applications and transactions. Mullins explained that performing analytics and queries in the EDW delivers a practical way to view the past without affecting daily business computing. This, in turn, means more efficiency, and ultimately, profit.
Also, from a financial point of view, the EDW is a relative bargain among data delivery paradigms, especially compared to less open, stable, or governed ones, like appliances, Hadoop, and data lakes. And thanks to competitive tool and talent markets, the barriers to entry have dropped for those who previously found EDWs too expensive or complex to implement.
EDW Evolution
The EDW emerged from the convergence of opportunity, capability, infrastructure, and the need for converting transactional data into information, all of which have increased exponentially in the last twenty years. As related information technologies evolved, many business rules were changed or broken to make way for data-driven rules. Processes fluctuated from simple to complex, and data would shrink or grow in an ever-changing enterprise environment.
Now, in the era of big data, many more sources and targets are in play. There are well-known challenges of data volume, variety, velocity, veracity, and value putting pressure on traditional EDWs. These concepts and their consequences are creating shifts in enterprise data management architecture from older paradigms like the operational data store to newer ones, like the Enterprise Data Hub (EDH), logical data warehouse (LDW), and data lake, which were designed to also accommodate more modern data stores and analytic needs.
As a result, some data management experts now consider EDWs to be a legacy architecture, but one still able to perform routine workloads associated with queries, reports, and analytics.
Voracity and the EDW
The IRI Voracity platform for data discovery, integration, migration, governance, and analytics supports traditional EDW architectures, as well as operational data stores, LDWs, and data lakes. Voracity is powered by the multi-threaded IRI CoSort transformation engine by default, or by Hadoop MR2, Spark, Spark Stream, Storm, or Tez engines against data in HDFS.
Both use the same metadata and Eclipse IDE for job management, so that execution choice is just a (seamless “map once, deploy anywhere”) click-to-run option. Either way, the goal is data warehouse optimization and big data integration through fast, consolidated data transformations.
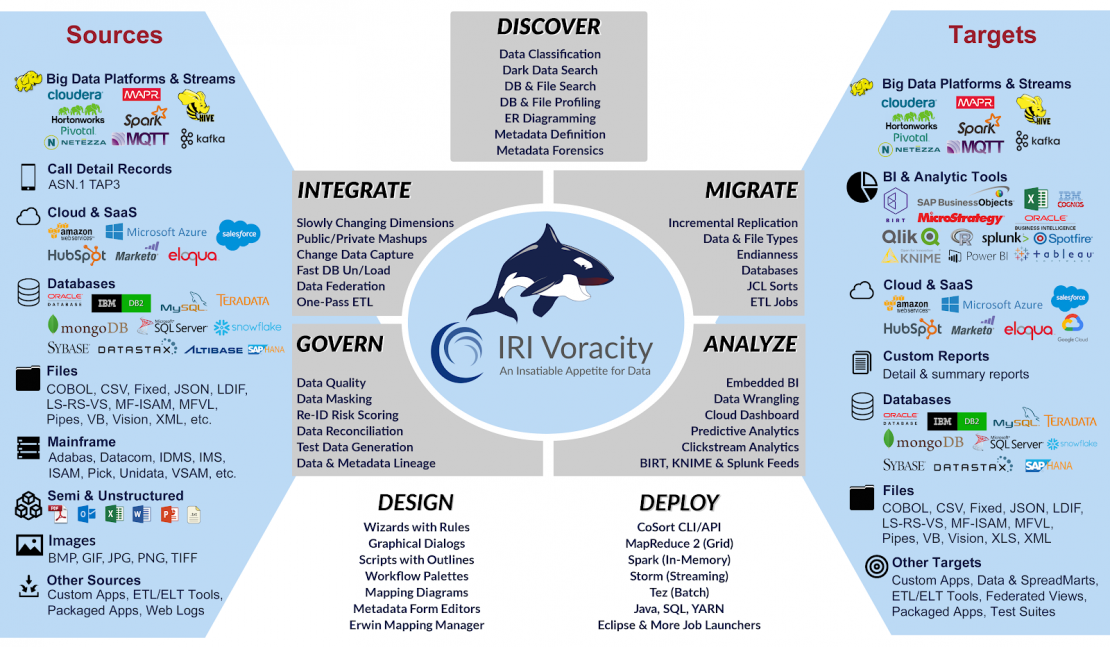
Voracity handles a wide range of data sources and targets, and addresses a number of data warehouse-related requirements, including: data profiling and classification, ETL diagramming, plus wizards for slowly changing dimensions, change data capture, pivoting, and master data management. Scripts support complex transformations, data quality, and elaborate reporting. All of its design and deployment facilities are exposed in the one GUI.
Governance-minded data warehouse architects should appreciate Voracity’s data discovery and protection wizards, which automate PII data identification and masking. Its subsetting and test data generation wizards facilitate the database and EDW prototyping as well. Metadata management is available through cloud-enabled asset repositories, with graphical lineage impact analysis through Erwin EDGE (formerly the AnalytiX DS Governance platform).
For users of existing DB, BI, and DW software — and ETL tools in particular — Voracity can either accelerate or replace them. For example, Voracity engines can be called into existing workflows to optimize unloads, transforms (especially sorts, joins, and aggregations), and loads (through flat-file pre-sort). A
lternatively, Erwin Mapping Manager and CATfx templates can automate a re-platforming process by converting most of the code in a legacy ETL tool into the equivalent jobs in Voracity. This effort can be undertaken and validated before any Voracity costs are incurred, but once complete, would free up hundreds of thousands of dollars and CPU cycles no longer needed.
Email voracity@iri.com for more information on the use of Voracity in an EDW, ODS, LDW or data lake.










