Building & Loading ‘Big Test Data’ into MarkLogic
Just as production data processing tools like IRI CoSort must handle big data in NoSQL DB environments, so too must a big test data generation tool like IRI RowGen. This article explains how a RowGen product or IRI Voracity platform user would leverage the test data generation facilities in their common IRI Workbench GUI to generate — and the MarkLogic Content Pump to load — test data into MarkLogic.
RDB vs. NoSQL
First, for RowGen and other users already familiar with relational database tables, it’s helpful to understand how a NoSQL ‘document data’ model differs from the relational database model:
Relational vs. Document Data Model
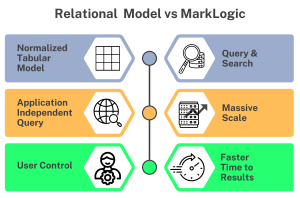
When data gets too big for a relational table, you must either add columns, or modify the data. Both of these options are untenable when the volume and variety of data grow too fast. For this reason, some data architects turn to enterprise NoSQL databases like MarkLogic to keep up.
The MarkLogic DB
MarkLogic is a NoSQL DB designed to store, search, and handle large amounts of heterogeneous data. Relational databases need a schema to define what data are stored, how it is categorized in tables, and the relationship between the tables. In MarkLogic, documents are the data and there is no schema per se.
In a document data model, all the data is typically contained in the same document, so the data is already denormalized. Blog content, press releases, user manuals, books, articles, web pages, sensor data, and emails are modeled as documents. MarkLogic helps complex applications interact with large JSON, XML, SGML, HTML, RDF triples, binary files, and other popular content formats.
Populating MarkLogic
There are several ways to load data into a MarkLogic database, including:
✓ MarkLogic Content Pump (MLCP): command line tool to import and export data
✓ Auto Loader: monitors files and automatically loads new records into MarkLogic
✓ Hadoop: UI for connecting a MarkLogic Server to a MapReduce source or target
✓ XQuery: loads documents using XQuery functions
✓ Node.js: client API to read, write, and query documents and semantic data in a MarkLogic database
This article demonstrates how IRI software populates data for MarkLogic in the same Eclipse GUI (IRI Workbench) using test data created with the IRI RowGen engine. Other IRI software in the same Eclipse GUI, like FACT, CoSort, FieldShield, NextForm — or the Voracity ETL platform that includes them all — can be used to prepare or protect production data headed to or from MarkLogic.
Creating Test Data
In addition to creating test data for RDB targets, RowGen can also generate very large, complex test files. To populate a NoSQL DB with test data, files are the way to go. I used the IRI Workbench GUI for RowGen to design a 12-million-row test CSV file-generation job and load its data into MarkLogic Server through MLCP.
The fields in my test file are:
ACCTNUM, DEPTNO, QUANTITY, TRANSTYPE, TRANSDATE, NAME, STREET ADDRESS, STATE, CITY
By default, RowGen randomly generates field values according to their data type. It can also randomly select values (using different pick techniques) from set files to enhance data realism. Use your own or IRI-supplied set files, or create them on the fly (from database columns, in-line ranges, or compound data value builds) in the GUI’s “New Set File” wizards. I used transdate.set, names.set, address.set, state_city.set.
Building Test Data via RowGen in the IRI Workbench GUI
Creating the test file requires a single RowGen job control language script. This can be written by hand or auto-generated in the RowGen new test data job wizard in the Workbench.
IRI Workbench is an integrated development environment (IDE) built on Eclipse that is used to create, run and manage data connections, metadata and job scripts. The language is easy to use. GUI can build them automatically with an end-to-end job wizard or a Visual ETL workflow (palette).
Refer to this link to see how to build a test file with both randomly generated and selected data fields. It is also possible to create and depict RowGen jobs in the workflow and field detail (“transform mapping”) diagrams used in the IRI Workbench GUI for Voracity, built on Eclipse:

From the IRI Workbench Remote Systems Explorer (RSE) panel (on the lower left), right-click on Local Shells, and click Launch Shell. From that prompt, change into the MarkLogic bin directory and enter this command to load the CSV test file into MarkLogic with the content pump:
C:\Program Files\MarkLogic\mlcp\bin>mlcp.bat import -host localhost -port 8000 -username admin -password admin -database Cosortdb -input_file_path
C:\Mlogic\foutput.zip -input_compressed true -input_file_type delimited_text -delimited_root_name Cosort -output_uri_prefix /iri/ -output_collections iri
Once the file is loaded into the server, I can use the query window in the IRI Workbench internal browser (pointed to http://localhost:8000/qconsole). In that client view, I just select the database from the dropdown and can see the test data:

For help building RowGen test data or populating your targets directly, email rowgen@iri.com. See this article for information on connecting to and using MarkLogic data in IRI Workbench operations.