Do You Use Change Data Capture Solutions?
Introduction: This blog discusses a brief overview of how IRI handles change data capture (CDC) solutions. Since the posting of this blog, IRI has created a wizard specifically for CDC solutions found in IRI Workbench. For more information on the CDC wizard and creating change data capture reports, you can find the blog here.
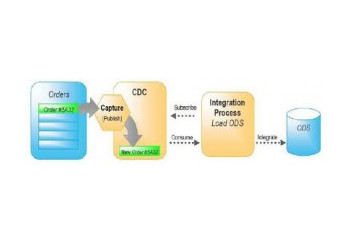
Change Data Capture (CDC) refers to the identification of, and reporting on, data that has been added to, updated (modified), or removed from sources like relational tables or flat files.
Most CDC operations make use of database log files to monitor and report on these changes. CDC makes the information about these changes available for use by applications or individuals, and can also be used to log changes in data manipulation language (DML) programs like SQL procedures.

Prior to the advent of Change Data Capture solutions, whenever there was a need for tracking modifications done on ETL jobs, you needed to create triggers and log the changes in the tables. With most modern CDC solutions, change tracking is automated at the product level. The CDC product can be further used to load only the new or changed data from the source system. However there are limitations to the database log approach, including: being specific to a given database, relying on the availability and completeness of the log, and not allowing for customized reporting of the changes.
Other methods include Source Data-Based Change Data Capture, which uses table timestamps or examinations of the last loaded rows for changes. The changes are stored in a ‘status table’ (Pentaho Kettle), or Snapshot CDC that compares record-by-record when timestamps or row IDs do not exist. DBAs can also create a trigger in tables with timestamps or row IDs that can be used to select the changed rows, which get written to a separate table. That can be complex, and tough to maintain across the database over time.
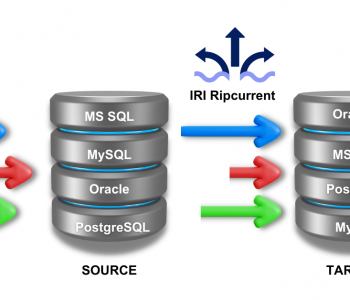
IRI’s approach to CDC is data-centric, and not tied to a given database or log system. It involves a full-outer join in CoSort’s Sort Control Language (SortCL) program to compare the source and target table (or flat file) to find matches and non-matches. The non-matching rows can be further identified as deletes (now missing), inserts (newly added), and updates (changes) based on conditional selection logic. The changes can be flagged, masked, and/or reported to one or more target tables or output delta reports in custom formats. The CDC reporting wizard in the IRI Workbench GUI for both CoSort and the IRI Voracity platform automates the creation of these jobs and supports but cumulative and incremental CDC operations.
This approach also allows cross-calculations, look-ups, and other functions to be performed across the old and new data values while these changes are being reported and targeted as needed. In addition to being platform-agnostic, data-centric, and efficient (since transformation, protection, reporting and population occur simultaneously), the external nature of the process lends itself to big data change data capture operations; databases and other tools may not produce the same results as quickly above ten million rows.