Test Data Management: Test Data Generation & Provisioning (Step…
This article is part of a 4-step series introduced here. Navigation between articles is below.
Step 3: Test Data Generation & Provisioning
In prior steps outlined in this series, you have determined the purpose and properties of the data, and who will produce and consume it. But how will your test data actually be generated for the platforms and applications that need it? And given the potential for many complex and large test targets, how will you deliver the test data to those targets? Have you considered consolidating the creation and supply of the test data directly to the target, or at least target formats, to save time?
Commercial-grade test data tools should allow you to specify particular output file and table names, and create multiple target sets in the same generation job (script) and I/O pass. Ideally, the process can be extended to perform pre-sorted bulk loads into relevant tables, and do so in a way that sets up, documents, and automates test table populations so as to preserve those dependencies. Only in this way can billions of rows in multiple tables be created and loaded with structural and referential integrity.
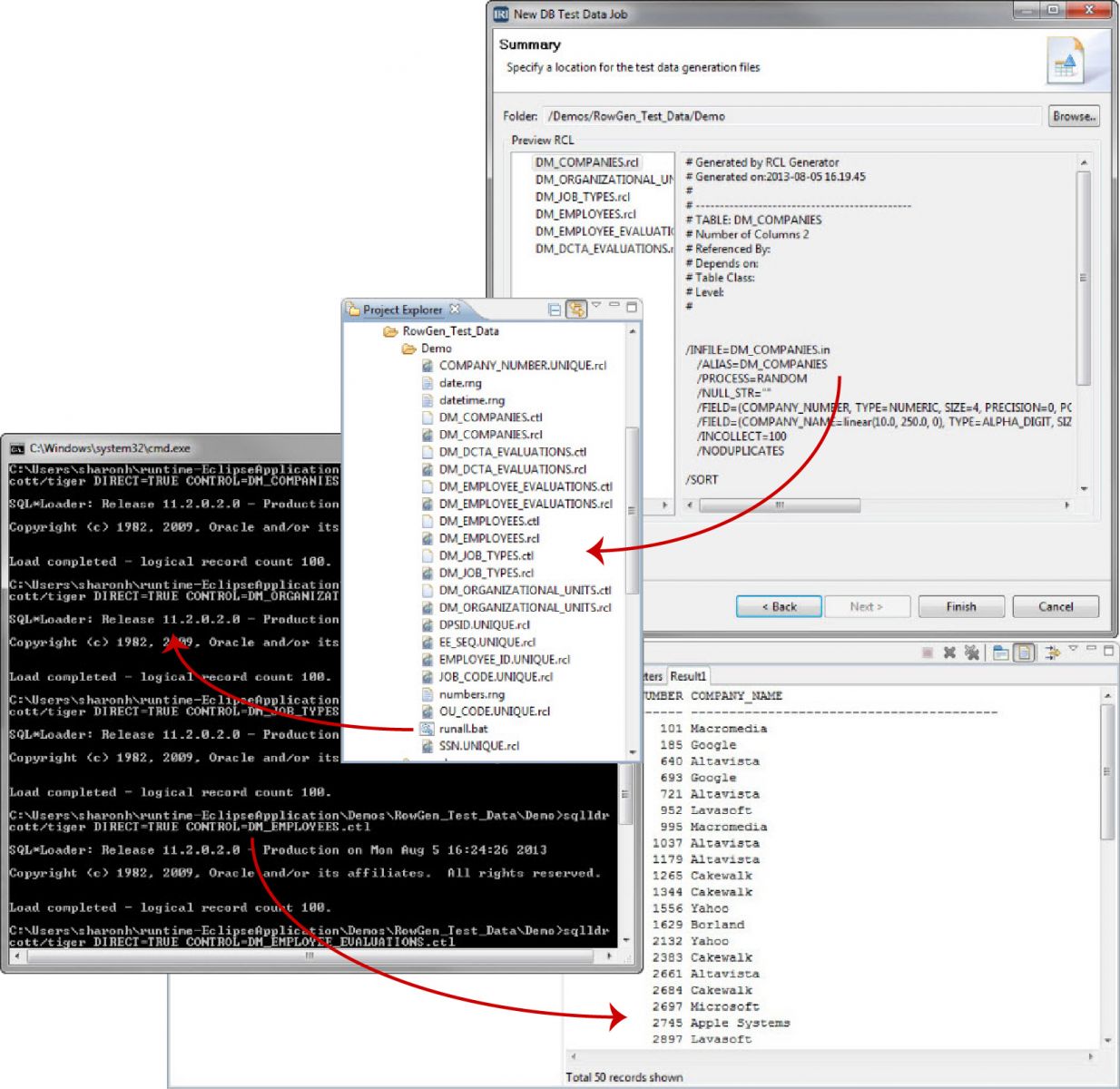
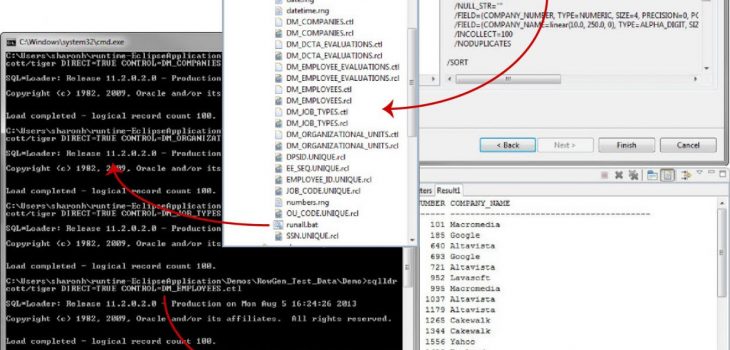
In the case of IRI RowGen (shown in its Eclipse GUI on the right), after all test data properties, rules, and destinations are specified, job scripts are automatically produced to create the test data for each target table, and sort it on the primary key. Also created are parameter (control) files for the target database’s bulk load utility.
A batch script is provided as well to run all the generations and populations in the right order. The multiple table content creation and direct path loads happen together, and referential integrity is preserved. Alternatives to this approach are typically more disjointed, or appropriate for smaller volumes of data.
Providing big test data in DB tables or flat files for software development or platform benchmarks is more straightforward. You should be able to move them around, even if they are created on a node different than the testing node. ETL tools, like DataStage, can trigger and accept RowGen input through the sequential file stage.
In addition to RowGen test data synthesis operations, IRI also supports multiple data masking jobs to realistically de-identify production data in structured, semi-structured, and unstructured sources with tools like IRI FieldShield, CellShield or DarkShield — all of which, along with RowGen and data/database subsetting capabilities, are included in the IRI Voracity data management platform.
To visualize test data for analytics, or to virtualize (deliver) it for downstream testing and prototyping, IRI software users can:
- create custom output reports with detail and summary test values during generation;
- franchise test tables, Excel sheets, or files in CSV/JSON/XML format to BI tools like BOBJ, Cognos, iDashboards, Microstrategy, OBIEE, PowerBI, QlikView, R, Spotfire, and Tableau;
- feed test data directly into BIRT visualizations via ODA in Eclipse;
- populate Cubeware, Datadog, KNIME and Splunk analytic workflows through those published integrations;
- call their synthesis, masking or subsetting jobs directly from CI/CD pipelines like AWS CodePipeline, Azure DevOps, GitLab, Jenkins, etc. in order to deliver test data in line;
- clone and containerize databases and files with this test-ready data using Actifio, Commvault or Windocks software; and,
- leverage advanced, governed test data hubs from Cigniti or ValueLabs which run the IRI jobs above to produce test data.
For testing federated data frameworks, both referential integrity preservation and customization of the build scripts are essential:
Our main goal with the test model is to provide a high-level mechanism for users and developers to represent constraints, dependencies, and relationships. Nevertheless, we are building the testing system such that application-specific test scripts can be executed for cases where the test model is not sufficient. – An Informatics Framework for Testing Data Integrity and Correctness of Federated Biomedical Databases, NCBI
So, also think about a tool supporting automation with respect to model parsing, and manual modification, to address this finer TDM point.
Click here for the last article, Step 4: Test Data Sharing & Persistence, or here for the previous step.