Before or Instead of Hadoop, Try This …
Before Big Data became a buzz word and Gartner hype cycle fodder (never mind falling into the ‘Trough of Disillusionment‘), companies like IRI were handling it. Huge flat files — such as telco CDR and web logs, mainframe datasets and VLDB table extracts — have been the inputs to CoSort’s massive data sorting and transformation engine on multi-threaded servers since the 90’s.
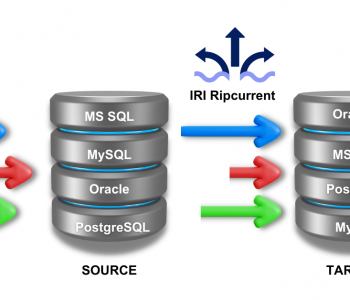
That’s still the case today, and even as we support Hadoop in CoSort’s successor Voracity platform, we pose the question of whether Hadoop is necessarily the best way to process very large data volumes in the first place. That’s especially so when CoSort is also directly addressing big data in relational, non-relational, semi-structured and unstructured sources. And it’s also questionable given that without Hadoop, CoSort’s SortCL program can at once:
- package (integrate, migrate, and reformat) big data, through the consolidation of multiple transforms
- protect big data at the field level, through a choice of data masking functions or big test data generation
and, - provision big data for DW / ODS, federation, and BI targets (with both embedded reporting and hand-offs to analytic and advanced visualization tools)
Again, all this happens in one Eclipse-supported 4GL job script, and in one I/O pass … within your existing hardware, file system, and database infrastructure:

There are still considerable skill gaps around Hadoop, MapReduce, NoSQL, and other hardware-driven technologies like in-memory DBs and ELT appliances. They require an “army of geeks” to set up, and cost a small fortune in servers and software to keep running and producing actionable results. Compare this to the power and simplicity of SortCL, the popularity of Eclipse, and the cost of both (hint: 5 figures + free).
So know your alternatives and their risks as you assess your informational goals and processing needs. Can you stay in the IT fabric you already have, exploit both internal and external data, and identify a clear business benefit for the cost? You may want to consider starting with something that’s more proven, affordable, and non-disruptive before converting to Hadoop.
See our “When to Use Hadoop” article for more information.