Discovering Spreadsheet Metadata in IRI Workbench
Abstract: Getting the correct metadata in a simple way is an important part of building structured data processing, protection, presentation, and prototyping jobs in IRI software. SortCL, the underlying data manipulation engine behind most IRI products, can now transform, migrate, consolidate, mask, and cleanse — among other functions — data in Excel spreadsheets, and IRI Workbench offers an intuitive interface for building out this metadata and the jobs that use it.
The previous article covered the creation of Data Definition Format (DDF) metadata files for IRI SortCL-compatible applications from spreadsheet data layouts via the xls2ddf conversion utility. That same metadata can also be generated in IRI Workbench more graphically through the Discover Metadata wizard, which will also display a preview of data in any connected sheet.
This wizard can also run within new job wizards launched from the IRI Workbench top toolbar menus for Voracity, CoSort, NextForm, FieldShield, and RowGen during their Data Source (or Target) specification phase. The metadata discovered therein can immediately populate the /INFILE (or /OUTFILE) section in the ultimate job script, or be saved to a .DDF file for re-use in other SortCL-compatible applications.
When selecting an Excel file from the Browse … feature in the Discover Metadata wizard, the file extension (XLS or XLSX) will dictate the /PROCESS format specified in the SortCL job script automatically. There are then a few options regarding the layout of the workbook itself to choose from.
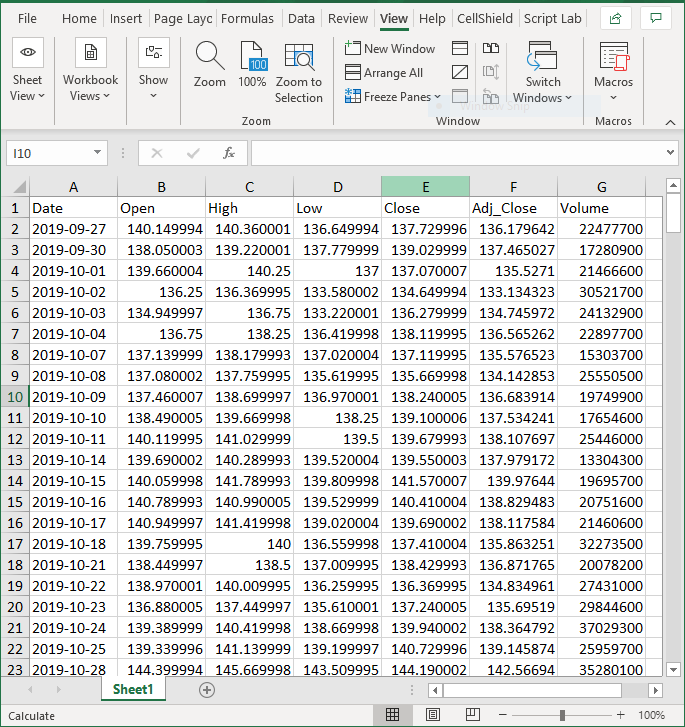
Following are images and descriptions demonstrating the use of the Discover Metadata wizard on a spreadsheet (in either .xls or .xlsx format). Our example uses this spreadsheet data:
Displayed below is the first page of the wizard: Data Source Identification. Here, the file is selected, format is determined, and options can be set such as sheet name, whether the sheet includes a header, and whether the data is oriented with each column representing a new record, rather than a new field.
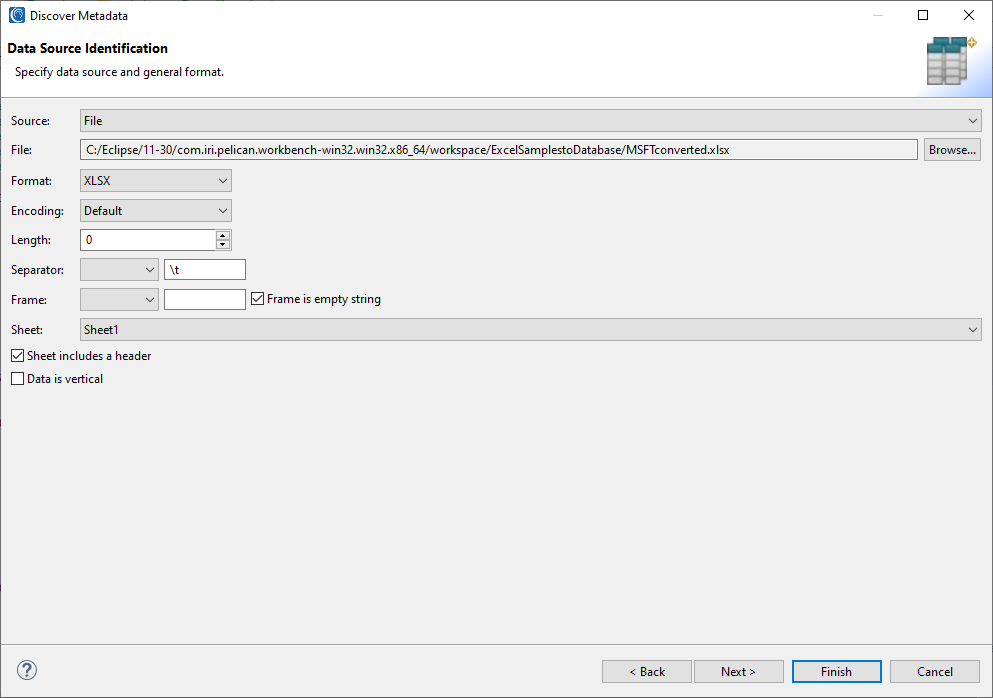
There should be a list of all the sheets in the workbook to choose from in the wizard. Only one sheet of the file can be selected per /INFILE section of the ultimate SortCL-compatible job script. If multiple sheets in the workbook must be processed, then multiple /INFILE sections must be specified.
Additionally, there are checkboxes to indicate whether the sheet includes a header row (or column) and whether the data is vertically arranged (i.e., rows should be processed vertically rather than horizontally). If the option to indicate the sheet includes a header is selected, the field names will be taken from that header row; otherwise, field names are produced generically (FIELD1, FIELD2, etc.).
All these options must be specified in the /(IN/OUT)FILE line. When the spreadsheet file has been selected through one of the IRI Workbench wizards, all of the options specified during the wizard will be put into the /(IN/OUT)FILE line.
Note that the DDF file generated by the Discover Metadata wizard will have a file line with all that information included in a commented-out line near the top of the file. File line options can also be modified, created, or deleted by hand of course, or graphically through the Edit Source Options menu, accessible from the Edit Sources menu in the IRI context menu viewed by right clicking a SortCL script.
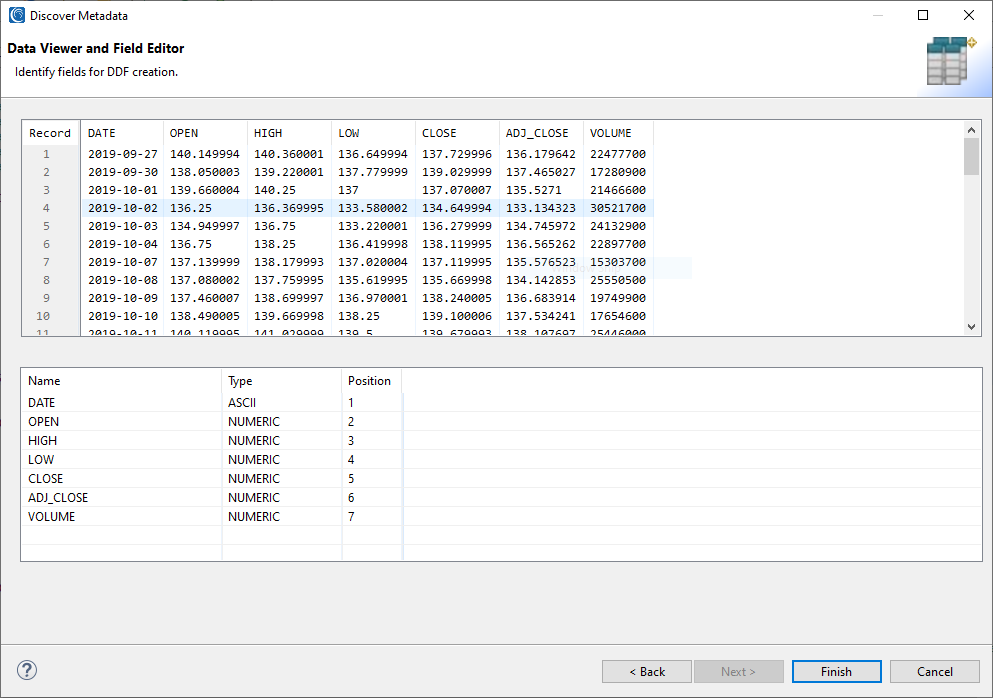 Displayed in this image is the second page of the Discover Metadata wizard, which includes a preview of the data from the file and sheet selected on the previous page.
Displayed in this image is the second page of the Discover Metadata wizard, which includes a preview of the data from the file and sheet selected on the previous page.
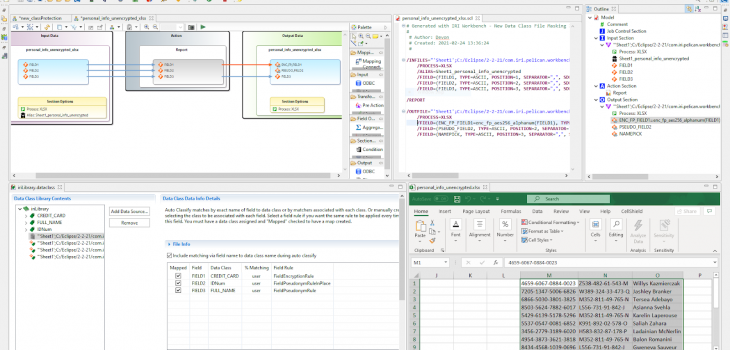
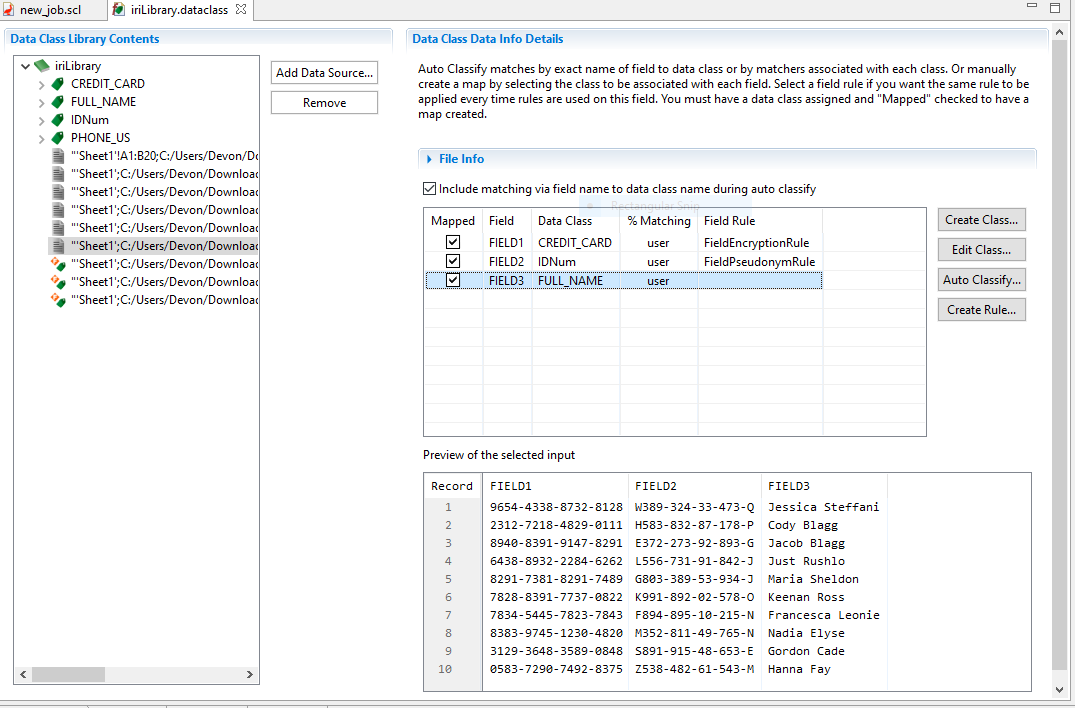
In addition to discovering spreadsheet metadata, IRI Workbench can generate a Data Class library with files that can include XLS and XLSX file types. This feature is especially useful in configuring data masking jobs for PII in Excel sheets using IRI FieldShield or Voracity ETL scripts to protect that data directly.1
This is done by traversing through the New Data Classification Source Wizard. Sensitive data, or specific data in general, can be searched for through values matching patterns (Java regular expressions), strings in set files (files with a set of values to match against), or in the case of DarkShield and CellShield EE, Named Entity Recognition *NER) models which use Natural Language Processing (NLP).
The method and details of the search can be saved as a data class and given a name. Then, rules can be set up to determine what manipulations should be performed when a certain data class is matched with a high enough percentage (or user specified).
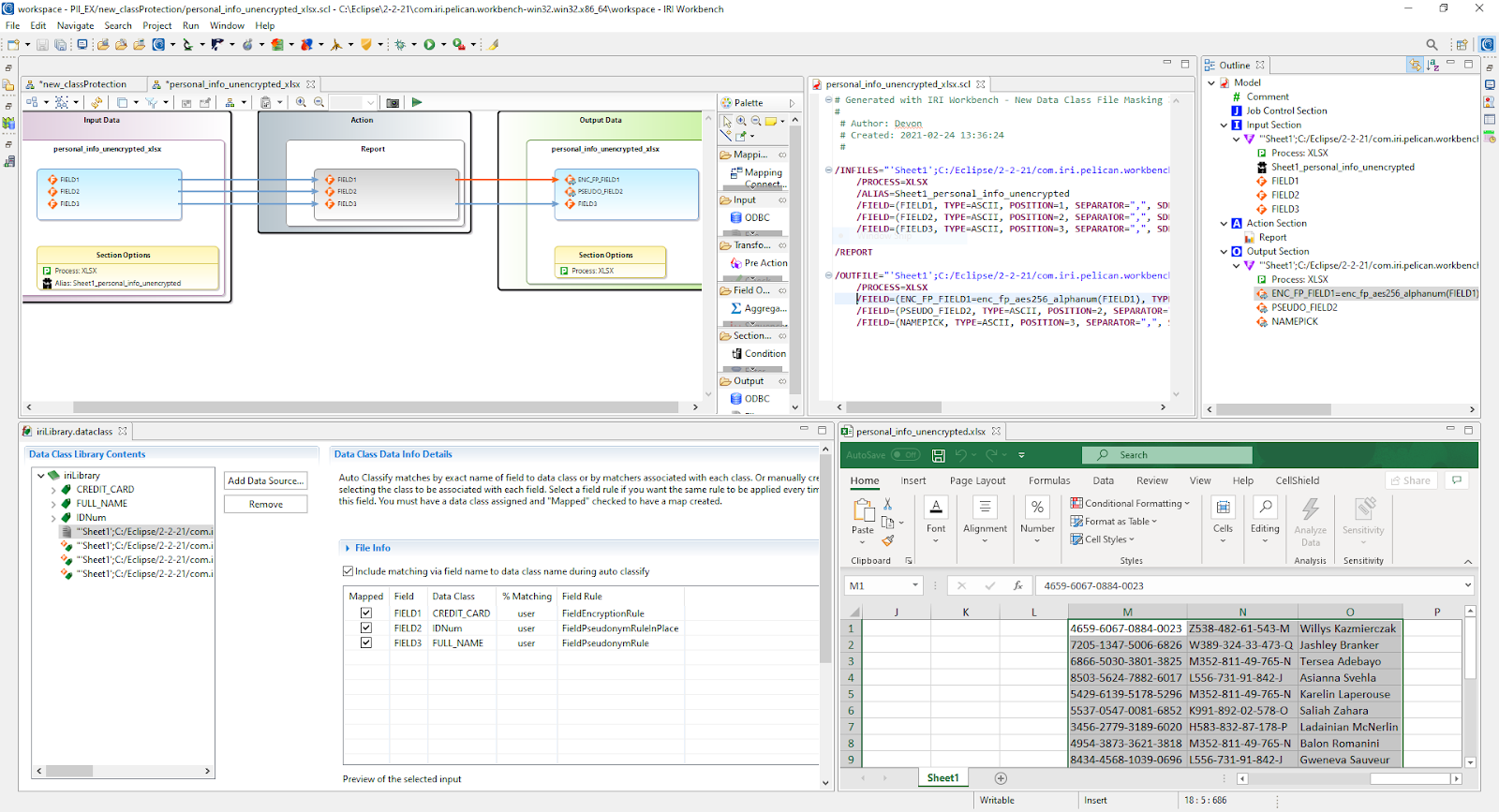
After setting up rules to protect the sensitive data in this file, the New Data Class File Masking Job wizard can be run from the FieldShield menu. This will take the rules and files in the data class library to generate a flow diagram, a batch script, and resulting SortCL scripts.
In this example, rules were set to protect the three fields with format preserving encryption, in-place pseudonymization/shuffle (using a set file of the existing data), and external pseudonymization (set file with data of the same category but likely not containing the same entries), respectively.
Across the top of the IRI Workbench screenshot below are three different views of the same SortCL job transforming the data defined in DDF /FIELD layouts. The data class library editor leveraging those layouts is shown bottom left, and the masked data results are shown in the Excel pane bottom right.
This concludes our series on IRI software support for XLS and XLSX spreadsheets in SortCL-compatible programs that process, protect, present and prototype structured data. To return to the first article, click here. For additional information, contact your IRI representative.
- Note that with this feature, IRI FieldShield becomes the third data masking product in Voracity, after CellShield EE and DarkShield, to directly mask data in Excel sources (and targets). The three tools are all front-ended in the same UI, IRI Workbench, leverage the same global data class definitions, and share the same core masking functions (encryption, redaction, pseudonymization, and hashing). By virtue of its SortCL framework, FieldShield can thus offer what the other shield tools do not: metadata compatibility and same-script data processing (beyond masking) for data in sheets (along with other structured data sources), including data integration (ETL), cleansing, migration, reporting.










