Voracity Software Support for Cloud File Stores
Public and private cloud file systems are becoming increasingly popular places for businesses and government agencies to store their data. Several major competitors have arisen in the cloud storage provider space, with Amazon, Microsoft Azure, and Google Cloud Platform at the top.
IRI Voracity and its core structured data processing program, SortCL, already supported the processing of flat files stored in Amazon S3 buckets. With the latest updates to IRI CoSort and IRI Workbench, however, support for cloud storage has been expanded to encompass Google Cloud Storage and Azure Blob Storage, too.
This article explains how to configure Voracity software and its SortCL program jobs specifically to use flat files in the three aforementioned cloud stores as data sources and/or targets. My first demonstration will be with simple report job. My second demonstration reads from one cloud provider and writes to another after applying some FieldShield data masking rules.
Note: Searching and masking sensitive PII located in semi-structured and unstructured data in Azure Blob Storage, Google Cloud Storage, and S3 is possible using IRI DarkShield. Read this article to learn more.
Providing Metadata for Cloud Files
As a quick aside, although IRI Workbench normally supports the discovery of metadata for files, there are a few exceptions. One of these exceptions includes discovering the metadata of files hosted in the cloud. When metadata cannot be discovered, users have two options:
The first option would be generating DDF files manually. This requires that they know the structure of the files in the cloud beforehand. The second option is to download a copy of the file from the cloud and get the metadata from it.
With a copy of the file stored locally, you can run the Discover Metadata wizard in Workbench to generate a DDF file automatically – in the same way, you would normally discover the metadata of files on the same PC or mounted in your LAN.
Demonstrating with Cloud Files
To start this demonstration, I will open the Report wizard in IRI Workbench by clicking on the dropdown arrow next to the stopwatch. From the dropdown menu, select the New Reporting Job wizard.
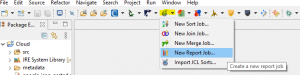
From here a wizard opens to create a SortCL job script with an extension of .scl. In the first dialog, select which IRI project folder in the workspace where the future job script will be placed, and specify a meaningful name for the job. Once that’s done, move on by clicking Next >.
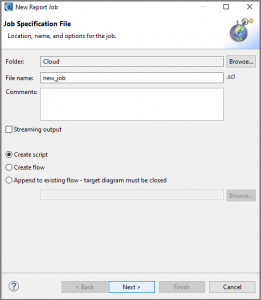
The next page of the wizard has us specify our data source:
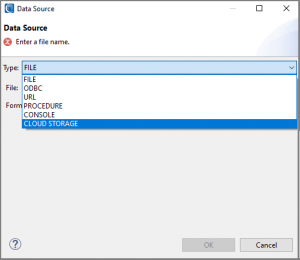
SortCL jobs support several source types:
- Files (local to the PC or a LAN drive);
- ODBC (for direct connections to RDB tables);
- URL (for HDFS, HTTP/S, FTP/S, MongoDB, and where S3 connections were before);
- PROCEDURE (for runtime-linked, custom input programs written in C/C++);
- CONSOLE (stdin); and, now,
- CLOUD STORAGE.
For this demonstration we will select CLOUD STORAGE as the data source type:
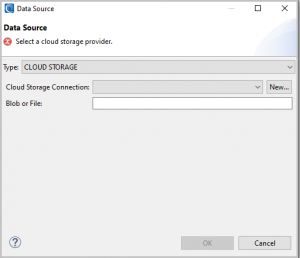
We now need to select either an existing (previously created) cloud storage connection, or create a new connection. Saved connections will be selectable in the Cloud Storage Connection drop-down list.
If you choose to create a new connection at this time, instead of using a previously created connection, a new connection will be created via the input the user provides in another window. That new connection gets added to the list of saved connections.
For this demonstration, I will create a new connection, and thus click New… to bring up this window:
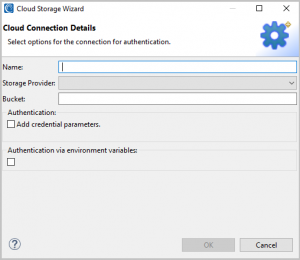
A new sub-wizard for cloud storage connections opens to help create a connection string in our job script’s /INFILE section. This tells SortCL to access files stored in a cloud store.
This wizard requires a unique name for the cloud connection we are making, and to specify which cloud storage provider we will access. In the dropdown menu for Storage Provider we can choose from Amazon S3, Google Cloud Storage, or Azure Blob Storage.
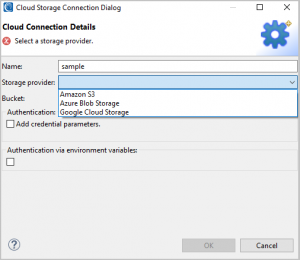
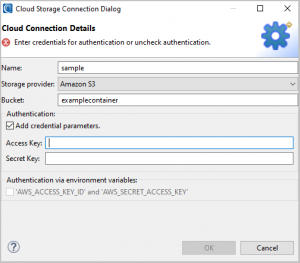
Amazon S3 provider form fields
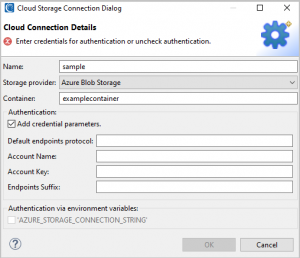
Azure Blob Storage form fields
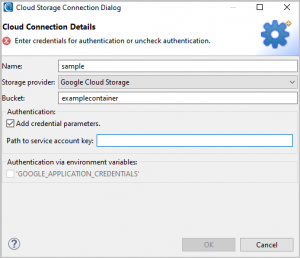
Google Cloud Storage form fields
Notice that for each of the different cloud providers there are two options to choose from for authenticating. Credentials can be added as parameters to the SortCL script, or through system environment variables.
Unlike the environment variables specified in SortCL job scripts (and prefixed by a $)1, system environment variables are stored by users on their machine and accessed by the operating system.
If you choose to use system environment variables, you will need to store your credentials in system environment variables with names specific to the storage provider. Notice in the images above, it is clearly stated what environment variables names need to be set (with the appropriate value) for each corresponding cloud storage provider.
See these links for S3, Azure, and Google environment variable setup.
If you are manually providing credentials you will need to supply different credentials based on the selected cloud provider’s requirements:
- Amazon S3: an access key and a secret key are needed for authentication.
- Azure Blob Storage: a default endpoints protocol, account name, account key, and endpoints suffix parameters are needed for authentication.
- Google Cloud Storage: the path to a service account key file.
To indicate which form of authentication we wish to use we need to check one of the following checkboxes.
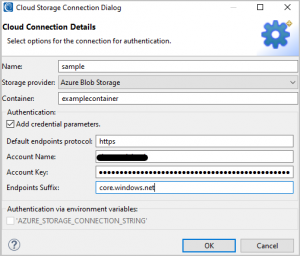
Once this page is completed, click OK to be brought back to the main Data Source wizard.
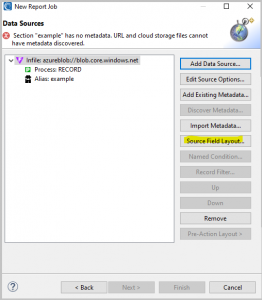
Because IRI Workbench cannot discover metadata for files in the cloud, you will have to create your source field layouts manually from the specifications of the file in the cloud.
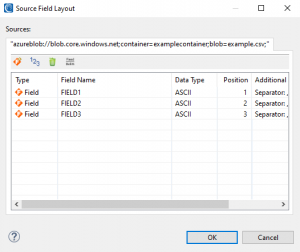
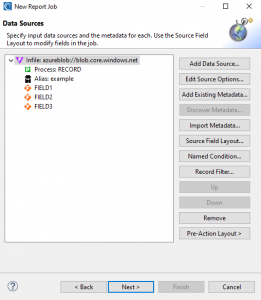
After setting up the /INFILE source fields, click Next > to set up the target file(s). For this demonstration, I will just choose CONSOLE (stdout) as the target.
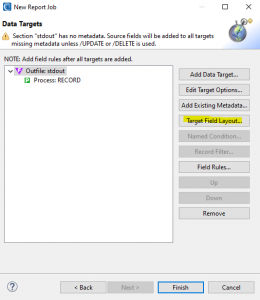
As with the target, I will need to specify output file /FIELD statements, either manually or automatically by mapping them through the target field layout editor. For a walkthrough and more elaboration on how to use the Source Field Layout and Target Field Layout options, I recommend reading this article.
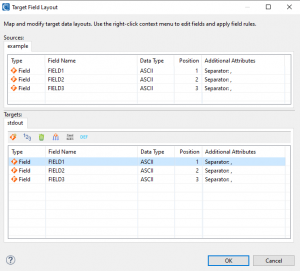
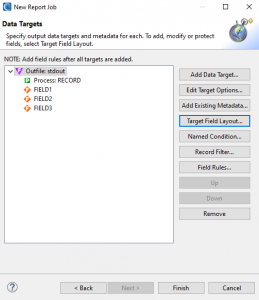
Once this process is completed, I can click Finish to have the job script auto-generated.
The finished job script will appear slightly different based on whether you chose to provide parameters for authentication or chose to use environment variables.
Job Scripts with Credentials
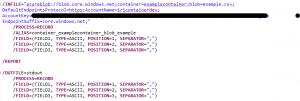
Azure Blob Storage with parameters provided for credentials
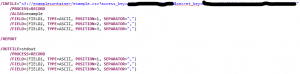
Amazon S3 with parameters provided for credentials

Google Cloud Storage with parameters provided for credentials.
Dissecting the connection strings when parameters are passed:
“azureblob://blob.core.windows.net” + “;” + “container=” + name of target container + “;” + “blob=” + name of blob, file, or object (include the path for any folders it resides in) + “;” + “DefaultEndpointsProtocol=” + http(s) (Azure supports both http and https, but https is recommended) + ”;” + “AccountName=” + account name value + “;” + “AccountKey=” + account key value + “;” + “EndpointSuffix=” + your endpoint suffix + “;”
“s3://” + name of the S3 bucket + “/” + name of blob, file, or object (include the path for any folders it is in) + “?” + “access_key=” + value of your access key + “&” + “secret_key=” + value of the secret key
“gcs://storage.googleapis;” + “bucket=” + name of target bucket + “;” + “object=” + name of blob, file, or object (include the path for any folders it is in) + “;” + “path_to_key=” + path to service account key (a JSON file generated by Google that contains credentials) +”;”
Job Scripts using Environment Variables
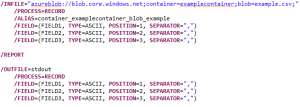
Azure Blob Storage using environment variables

Amazon S3 using environment variables
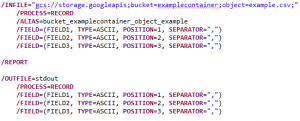
Google Cloud Storage using environment variables
Here is what the job script syntax looks like using environment variables:
“azureblob://blob.core.windows.net” + “;” + “container=” + name of target container + “;” + “blob=” + name of blob, file, or object (include the path for any folders it resides in) + “;”
“s3://” + name of the S3 bucket + “/” + name of blob or object including any folders it is in
“gcs://storage.googleapis;” + “bucket=” + name of target bucket + “;” + “object=” + name of blob, file, or object (include the path for any folders it is in) + “;”
FieldShield Masking Job Example Reading and Writing to Different Cloud Stores
Until now I have shown some simple examples on how to read and process flat files from different cloud storage locations and write to the console. That said, far more is possible in terms of processing and targeting.
By way of example, the IRI FieldShield job (.fcl script) below reads a file from an S3 bucket, performs some masking operations on the file, and then writes the file to an Azure Blob Storage container after performing masking operations on first names, last names, and birth dates.

The original employee.csv file residing in a S3 bucket:

The new employee.csv file is placed in Azure Blob Storage with format preserving encryption on the 2nd, 4th, and 11th column:

Adding Cloud Connections to IRI Preferences
As previously mentioned when building a job in a Workbench wizard, you can either choose to reuse a previously created connection or create a new connection during job design. If you created a new connection in the wizard, it would automatically be added to the list of previously created and stored connections.
In the past, any previously created database or URL connections could be viewed, added, modified, or deleted from inside IRI Preferences under the IRI tab. The same is now also true for cloud storage connections.
Open IRI Preferences from the toolbar
Open the IRI tab in left window pane
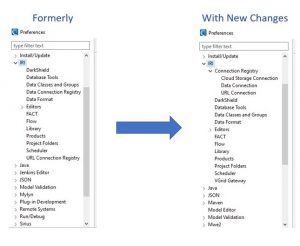
New changes to layout of IRI tab in preferences.
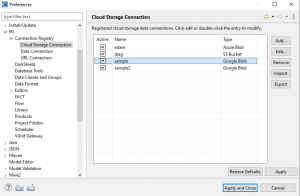
Cloud Storage Connection Registry table that displays saved cloud storage connections
If you are interested in learning more on managing connections in the connection registry, read this article about using the connection registry in Workbench.
To summarize, with the latest additions to SortCL and IRI Workbench, Voracity-compatible data management software now supports structured file sources and targets in Azure Blob Storage and Google Cloud Storage, along with Amazon S3 buckets.










