Faster Big Data Prep for Tableau
To compete effectively, business users must be able to rapidly produce and present accurate, concise, and compliant information. Whether the analytic discipline is diagnostic, descriptive, predictive, or prescriptive, time-to-visualization matters.
However, such rapidity is not always easy to achieve, nor is accuracy and security, especially when you consider the growing landscape of structured, semi-structured, and unstructured sources of ‘big data’ that can feed analytic engines. Those engines are not designed to package, protect, or provision high volumes of data efficiently.
Thus, good tools and methods to prepare (or franchise) big data for business intelligence (BI) and analytic platforms are increasingly important. This article for Tableau, like its predecessors for BOBJ, Cognos, and Microstrategy, illustrates the relative speed and simplicity of staging data with the IRI CoSort product — or newer IRI Voracity data management platform using it — by performing data transformation, data cleansing, and data masking outside the BI layer.
Tableau provides a refined set of tools to display and render data in more user-friendly formats, such as charts, graphs, and visualizations. It is designed to connect to multiple data sets, extract and filter selected data, and then provide that data to its visualization tools. Tableau can handle complex queries, but nothing can be analyzed or visualized effectively until the data has been located, acquired, refined, aggregated, protected and otherwise prepared for the visualization(s). That is where CoSort (or Voracity) enters the scene.
You can extract, filter, transform, and mask data from more than 150 different data sources. Without the need for Hadoop or DB engines, the SortCL program in CoSort and Voracity does the heavy lifting of data restructuring, transformation, and remapping. Its targets are custom-formatted, purpose-built subsets that visualization applications easily ingest. For privacy law compliance, it can also apply field-level redaction, encryption, pseudonymization, tokenization, and other masking functions at the same time.
It should be noted that Voracity and Tableau are not mutually exclusive. Both can be used to extract data from multiple sources and bring it into one location for reporting or further manipulation. However, depending on the data sources, data volume, platforms, and resources, CoSort or Voracity can be used with Tableau to pre-build a selected data set (flat file) as accepted input for analysis and creating visualizations.
An independent testing resource with expertise in Tableau was recently able to demonstrate the performance benefit of using CoSort as a pre-transformation tool for data feeds into Tableau. The focus of this test was only on the data collection tasks – sources, queries, filters, and generating the resulting data set. Time-to-delivery tests were conducted with CoSort against Tableau, which showed a dramatic performance difference with the sample inputs. Given the need to sort, join, and aggregate big data sources prior to producing reports in a BI tool, testing demonstrated comparative query and output speeds between the two products.
CoSort provides two ways for end-users to acquire and stage data; via a SortCL job script run from the command line, or in Voracity through the IRI Workbench GUI, built on Eclipse™. For the test, data from two large sources were sorted, joined, filtered, aggregated, and reformatted into CSV targets. CoSort was run from the command prompt in this case:
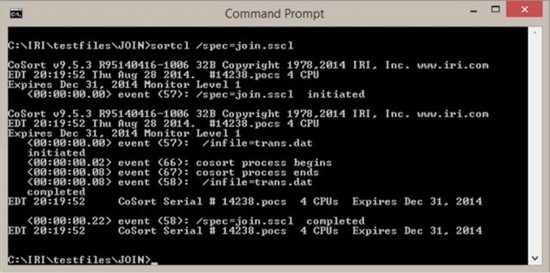
The tester performed analogous integration steps to create the foundation for processing the same data files, and creating the same outputs in Tableau for visualization purposes:

However, the time it took for Tableau to generate the same pre-visualization data from the same sources was much greater. CoSort was more than 8 times faster than Tableau in processing the same data and producing the same pre-visualization results. The relative data preparation performance for 20M-row sources is shown here:
| Product | Start Time | End Time | Elapsed Time |
|---|---|---|---|
| CoSort | 10:57:20 | 10:57:46 | 00:00:26.37 |
| Tableau | 19:22:16.031 | 19:25:35.933 | 00:03:19.902 |
There are times when getting the requisite data necessitates multiple nested queries with complex joins. In this case, CoSort prepared all the data and ran the query in the same amount of time it took Tableau just to run the query after receiving its output from CoSort.
In addition, being able to script the queries, define the outputs, and run updates from a command line — or automate them as part of a scripted and timed batch job — saves time for both IT and business users.
For more information on improving Tableau performance without in-memory databases or other costly paradigm shifts email info@iri.com. For wrangling data for other BI and analytic tools, and links to similar benchmarks, see this section.