Using Sonra Flexter to Process Complex XML Files in…
Sonra recently demonstrated the processing of complex XML data in the IRI Voracity data management platform with the help of Sonra’s Flexter Data Liberator software. Flexter and Voracity are a match made in heaven. Flexter is great at converting complex files like XML into structured formats. IRI Voracity, through CoSort or Hadoop engines, excels at data transformations — as well as data masking — on large, structured datasets.
In this blog post, I will show you how my POC combined these technologies to break complex XML data into constituent CSV files, and then masked personally identifiable information (PII) in them, such as email addresses. Note that finding and masking PII in raw XML files is also possible without Sonra Flexter using IRI DarkShield.
Create Target Schema and CSVs from XML
As a first step, we use Flexter to transform the XML data into CSV files. Flexter can work with arbitrarily complex XML schemas. For this example, I selected a particularly complex XML schema, the NDC standard from IATA . NDC stands for New Distribution Capability, and is a widely used industry standard in the aviation industry.
The schema contains hundreds of elements and is made up of X interconnected and embedded XSD files. It covers most business processes (Shopping, Order Management, Airline Profiles, etc.) in the aviation industry for the purpose of data exchange. You can download sample NDC schema from this page.
Below are some of the XSD files that are part of the NDC standard:
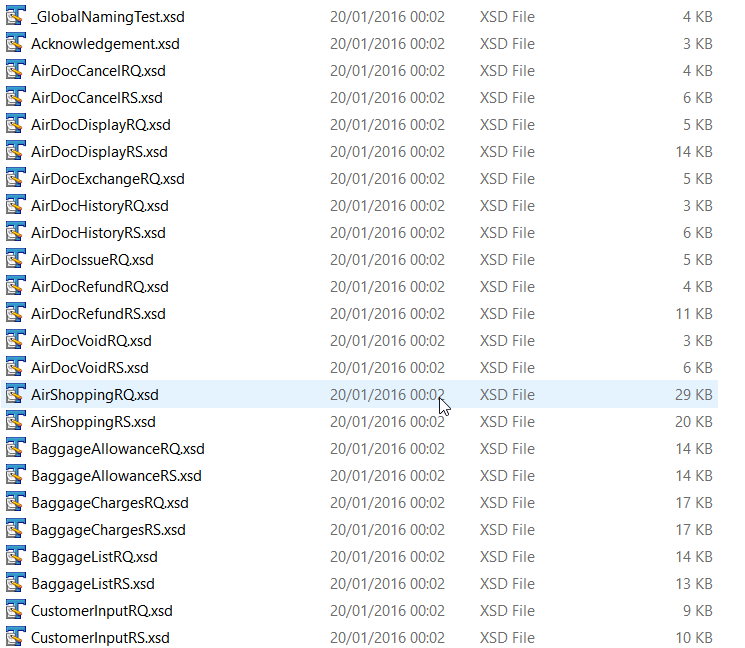
Each of the above XSD files references the core schema edist_commontype.xsd, which contains the bulk of the schema. One of the elements in this schema is email contact. This is the file we will protect using some of the data masking functions available to IRI FieldShield product, or IRI Voracity platform, users.
<xsd:element name="EmailContact" type="EmailType"> <xsd:annotation> <xsd:documentation source="description" xml:lang="en">Email address details, including application (I.e. home, business, etc.).</xsd:documentation> </xsd:annotation> </xsd:element>
We convert this schema and our XML files with Flexter by running the flexter_in_out.sh script. We pass in the name of the XSD and the folder where we have stored our XML files. This creates a relational target schema and the corresponding CSV files for each table.
./flexter_in_out.sh in/xml/ in/OrderCreateRQ.xsd
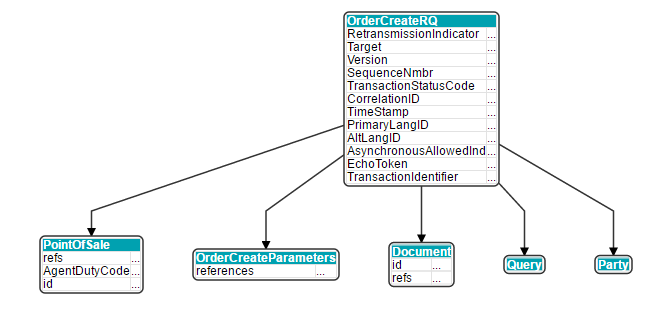
The output is the target schema:
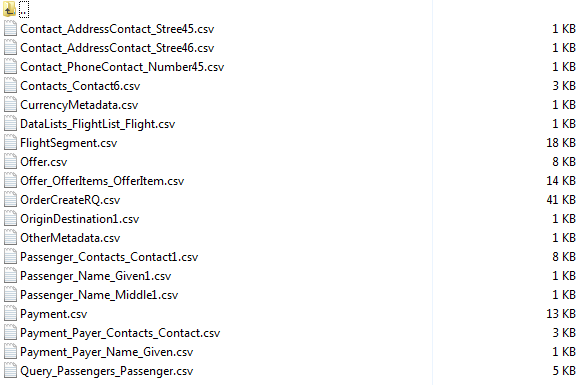
… and the CSV files:
An extract from OrderCreateRQ.csv:
![]()
Masking and Encrypting the Email Addresses
We have seen Flexter in action. So far, so good. Let’s hand the results over to Voracity. We feed the CSV output from Flexter into IRI’s csv2ddf utility, which runs in the IRI Workbench GUI for Voracity (built on Eclipse™) or on the command line. Either way, it parses the CSV files and creates a data definition file (DDF) for each of our CSV files.
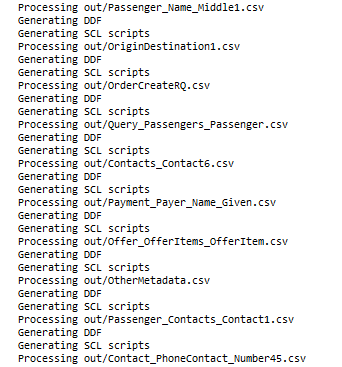
Below is a screenshot of the generated DDF files:
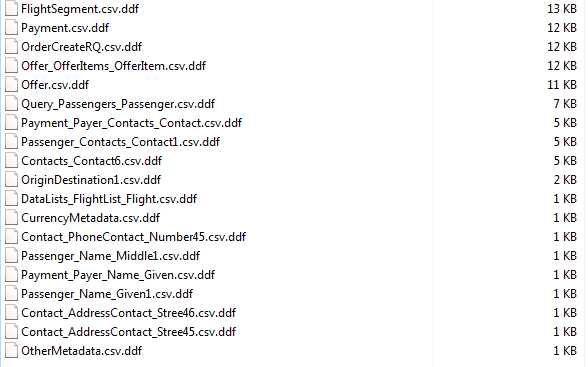
Each DDF file contains a description of the fields for each input file. The DDF for OriginDestination1.csv, for example, is shown here:
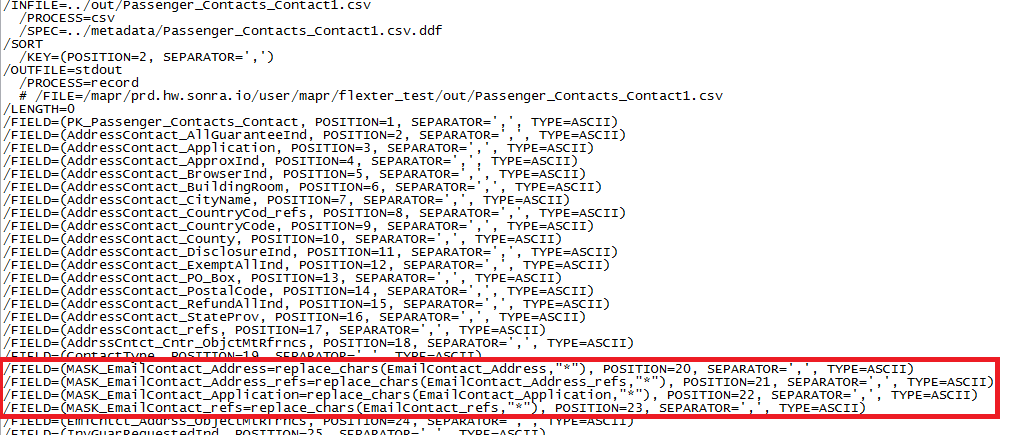
 An IRI job script — in the language called SortCL — references that .DDF as it specifies the sort of one field in the input file, and the masking of four of them on output:
An IRI job script — in the language called SortCL — references that .DDF as it specifies the sort of one field in the input file, and the masking of four of them on output:

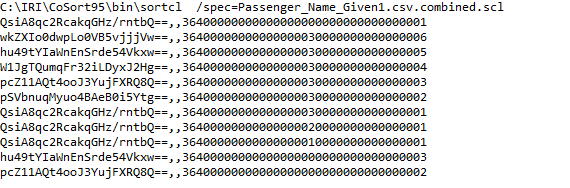
Shown above are the output file results of the sorting and data masking job.
In addition to sorting and redaction, and a host of other data transformations, you can also use CoSort’s SortCL or FieldShield executables to encrypt and decrypt data in CSV files and other sources. Encryption is particularly useful for obfuscating data that needs to be restored at some later point.
Integration with the IRI Workbench GUI
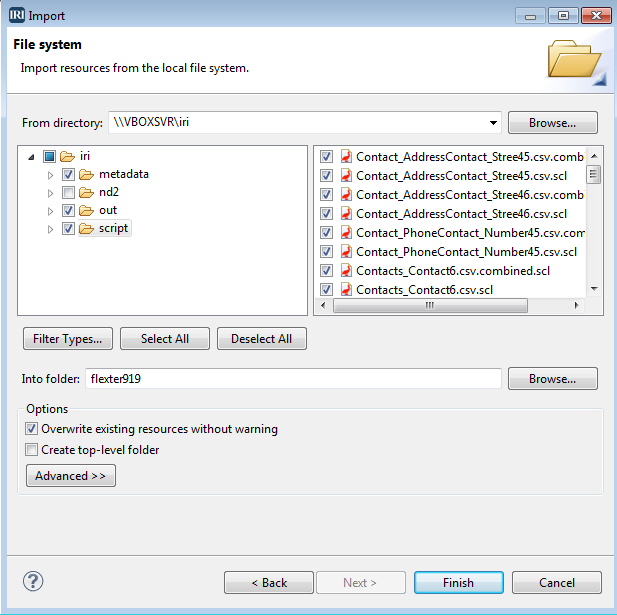
Of course, we can also import our Flexter-generated CSV files into IRI Workbench, the graphical IDE for all IRI software, built on Eclipse. To do that, we select File > Import in the IRI Workbench menu. In the Import window, we select File System and select the folder with the data we generated in the original steps.
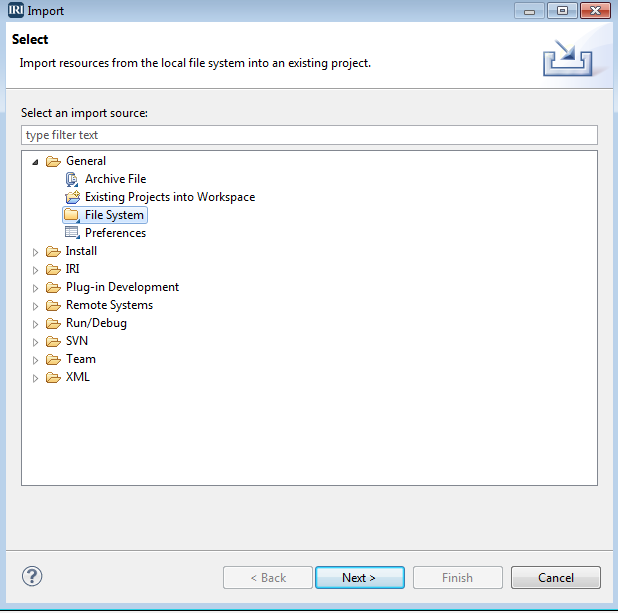
Select script, output, and metadata folders, and also select the folder that contains your project.

Now that we have the files in the Workbench, we can apply additional transformations to the data using the comfort of a free and familiar, graphical user interface (e.g., additional protection rules). See this page for more information on the job design options available to Workbench users.
What’s next?
The above tutorial shows how a powerful data management platform such as IRI Voracity can work well in tandem with Flexter Data Liberator.
Obviously, we could make the whole process more seamless by directly integrating Flexter into the IRI Workbench GUI for Voracity; e.g., via an Eclipse plugin. Both IRI Voracity and Flexter also have advanced REST APIs to integrate the two tools even further. The above post should have given you an overview on what is possible at this juncture.










