AI Data Classification for RDBs
Introduction
Data Classification in the IRI Workbench GUI is used to name and find specific kinds of data – usually Personally Identifiable Information (PII) – and to consistently apply chosen functions (e.g., pseudonymization) to each data class. Applying deterministic masking functions to data classes preserves referential integrity in IRI FieldShield and DarkShield data masking results.
Defining and locating data classes – like names and addresses, ID, phone, and credit card numbers can be time-consuming, however, in a Relational Database (RDB) with hundreds of tables and thousands of columns. New IRI AI functionality can now accelerate this process.
The new “AI Schema Data Classification” wizard can scan relational schemas to automate both the identification of data classes and the specification of default masking rules for those classes. The results of the wizard allow FieldShield and DarkShield (or Voracity platform) users to build and run RDB data discovery and de-identification jobs 1 much sooner than they could before.
This additional RDB data discovery capability is yet another application of AI in IRI data masking tools. DarkShield, for example, already leverages AI to discover and mask names in unstructured text through Named Entity Recognition (NER) models, as well as signatures within documents. IRI will also use AI to protect faces, PII in handwriting, and complex address presentations.
Where Is It?
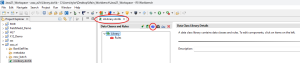
The new AI Schema Data Classification wizard is located directly inside the Data Classes and Rules (iriLibrary.dcrlib) file dialog in IRI Workbench. In the top toolbar, located next to the Data Class creation button, there is a new Robot icon that is used to denote the new AI scanning tool:
How Is It Helpful?
The wizard helps database users set up data classes faster. Regardless of whether the default rule attached works in your situation, at the very least, the manual work of creating the data class and its location matcher will already be completed for you.
Using various combinations of detection methods – including pattern matching, context, custom logic, and checksums – the current AI model searches for these 29 classes of data and assigns each the default masking rule shown here:
| Data Class Name | Description | Default Masking Rule |
| Phone Number | Telephone number (multiple formats) | FPE |
| IP Address | IPv4 or IPv6 Internal Protocol address | FPE |
| Email Address | RFC-822 validated email address | FPE |
| Location | City, province, region, country, ocean | Pseudonymization |
| Person | First, middle, last or full name | Pseudonymization |
| NRP | Nationality, religious or political group | Pseudonymization |
| Credit Card | 12-19 digit credit card # | Synthesis |
| Date/Time | Dates and time periods < 1 day | FPE |
| Crypto | Cryptocurrency (Bitcoin) wallet number | FPE |
| Medical License | Common medical license numbers | FPE |
| IBAN Code | International Bank Account Number | FPE |
| URL | Uniform Resource Locator (web address) | FPE |
| Australia Business | 11-digit ID for Australian Business Register companies | FPE |
| Australia Company | 9-digit ID for Commonwealth Corporations Act companies | FPE |
| Australia Medicare | Cardholder ID for medical expense rebates | FPE |
| Australia TFN | Tax file number (ATO ID) for every taxpaying entity | FPE |
| India PAN | 12-digit Permanent Account # (tax ID) | FPE |
| India Aadhaar | 12-digit individual identity # | FPE |
| India Vehicle | government-issued transport registration # | FPE |
| India Voter ID | 10-digit alphanumeric # for each citizen | FPE |
| India Passport | Indian passport # | FPE |
| Singapore NRIC | National Registration Identification Card # | FPE |
| UK NHS | 10-digit National Health System ID | FPE |
| UK NINO | National Insurance Number (also used for taxation) | FPE |
| US Bank Number | 8-17 digit bank account # | FPE |
| US Driver License | State driver license # in NTSI format | FPE |
| US ITIN | 9-digit Individual Taxpayer Identification Number | FPE |
| US Passport | 9-digit passport # | FPE |
| US SSN | 9-digit Social Security Number | FPE |
FPE means Format Preserving Encryption. Pseudonymization replaces the value with a realistic, non-reversible substitute. Synthesis generates a new PAN in the same format.
Although you cannot currently add classes to this scanning model, you can define additional data classes, and rules for those (as well as modify the rules for the classes above) … whatever best suits your requirements. See this article on the Data Class and Rule Library for details on how to configure, group, and prioritize data classes.
Once your data class rules are defined, you can configure RDB data discovery and masking jobs. For DarkShield, use the New Relational DB Search/Masking Job wizard per this article. For FieldShield, see: 1) this article on the Schema Data Class Search wizard; 2) this article on the Data Class Map; and then, 3) this article on the New Data Class Map DB Masking wizard.
Using the Wizard
Prerequisites
- IRI Workbench (installed and open)
- Established JDBC database connection
Step 1: Launch the Wizard
With the iriLibrary.dcrlib file opened, select the Robot Icon.
Step 2: Configure the Scan
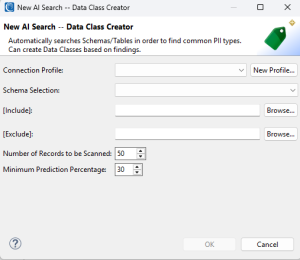
There will be a new wizard menu that pops up with information about the AI scan you want to perform (see the image below). Following is a breakdown of what each option represents.
Connection Profile: Select the JDBC-connected database instance you want to scan.
Schema Selection: The SCHEMA you want to scan.
[Include]: Scan ONLY these specific tables.
[Exclude]: Do NOT scan these specific tables.
[Amount of Records to be Scanned]: Reads a specified number or rows in each column. The higher the number, the potential for higher accuracy, but at the cost of performance.
[Minimum Prediction Percentage]: The minimum confidence score given by the AI that you want to see. This means the AI model will still search through all the data, but will only display the results for anything above this threshold. Keeping the confidence score low is recommended, since you will still see the higher confidence items as well.
Step 3: Running the Scan
After selecting OK, a new wizard will appear showing you the AI model is actively searching and predicting. Once the searching and predicting is done, a new wizard will appear showing you the breakdown of what the AI model found and scored:
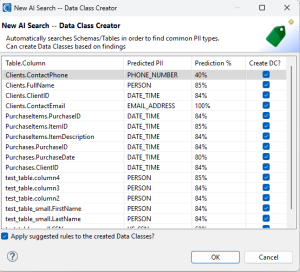
Following is a breakdown of what is shown on this screen:
Table.Column: Displays each table/column name where a data class was identified.
Predicted PII: Shows the model’s predicted PII type based on the scanned data. More than a dozen different labels of data are currently recognized in the model.
Prediction %: Shows how confident the model is that the predicted type is correct.
Create DC?: Allows you, the user, to either allow or prevent the creation of a data class using the information provided by the AI model.
Finally, there is a button in the bottom left corner that asks if you want to apply suggested masking rules to these data classes based upon their predicted PII types. This will also generate a list of rules to allow for easier swapping if needed.
Please note that this is an AI model and the predictions will NOT be 100% accurate. IRI therefore recommends that you review everything the wizard produces to prevent PII leakage and preserve referential integrity (via consistent application of a deterministic masking function).
Selecting OK on this wizard will then create Data Classes based on your selection. It will also create a Data Class Group to house all of the Data Classes so they do not clutter up the library:
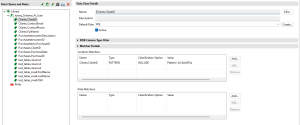
The new Data Class Group will have a prefix name of the scanned Schema. In my example, the Data Class Group name starts with tylorq. Within these newly created Data Classes, we can see a location matcher and a default rule applied (see above).
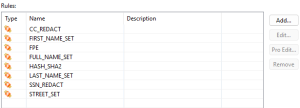
Looking inside the Rules library, we can see a list of created rules for easier application, with less manual user work:
Conclusion
This new AI Schema Data Classification wizard can speed your path to search and mask PII in VLDBs by reducing the setup time and work needed to define many of the data classes likely to occur. Again, this is a tool to help, but not replace or guarantee 100% definitional accuracy. Be sure to verify all classification results, rules, and data that you will touch.
Please email voracity@iri.com if you have any questions about, or need help with, this wizard.
- See this FAQ to learn which RDB masking use cases are best suited for FieldShield vs. DarkShield.










