Finding and Masking PII in XML and JSON Files…
Editors Note: The content of this article has been superseded as of DarkShield Version 5. Please refer to this article instead for the current methodology using data classification and location matchers for XML and JSON files. Note that in addition to the GUI approach described in that article, DarkShield also provides an API for files to integrate search/mask operations into your application(s).
Personally Identifiable Information (PII) like names, Social Security numbers, home addresses, etc. are stored in multiple sources and silos, including semi-structured files in JSON and XML format. These formats are characterized by key-value pairs that identify data elements; these identifiers can now be used for finding and masking PII values in IRI DarkShield software.
Note that IRI FieldShield could already find and mask PII in structured (flat) JSON and XML formats. But DarkShield handles more complex, semi-structured documents, and can save more time in the search process through a new method: path filters.
Specifically, this article discusses the location and remediation of PII in semi-structured files via these key or element names. This method can be used alone or in conjunction with other “search matchers” supported in DarkShield, which include: pattern matchers, value lookups, and NER models. Path flters can provide a faster and more reliable way of finding PII in semi-structured files.
By way of example, suppose we have an XML file containing a list of invoices with Forename and Surname elements as well as other PII hidden within free-flowing text elements which could potentially be used to expose the identity of the customer. We want to mask this PII wherever we find it in the Invoices, but retain the customer information in other parts of the document.
DarkShield supports this use case through the use of Filters, which are file-type specific objects attached to Search Matchers. DarkShield supports the use of XPaths, a query language that can navigate through XML file elements and attributes, and return a value pertaining to the specified element. DarkShield can also use JSON Paths to filter through keys in a JSON file.
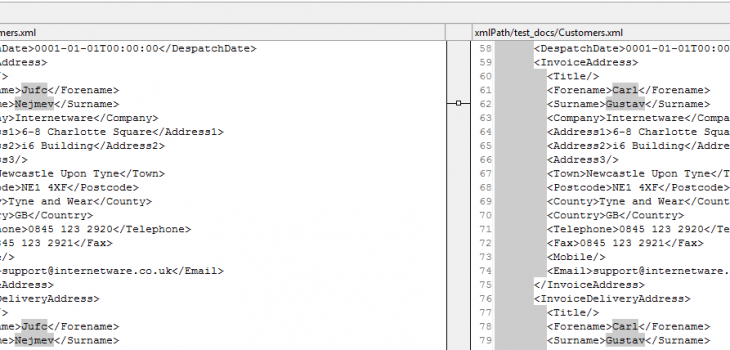
Let’s look at an XML file containing PII in IRI Workbench, the graphical IDE for DarkShield et al, built on Eclipse™:
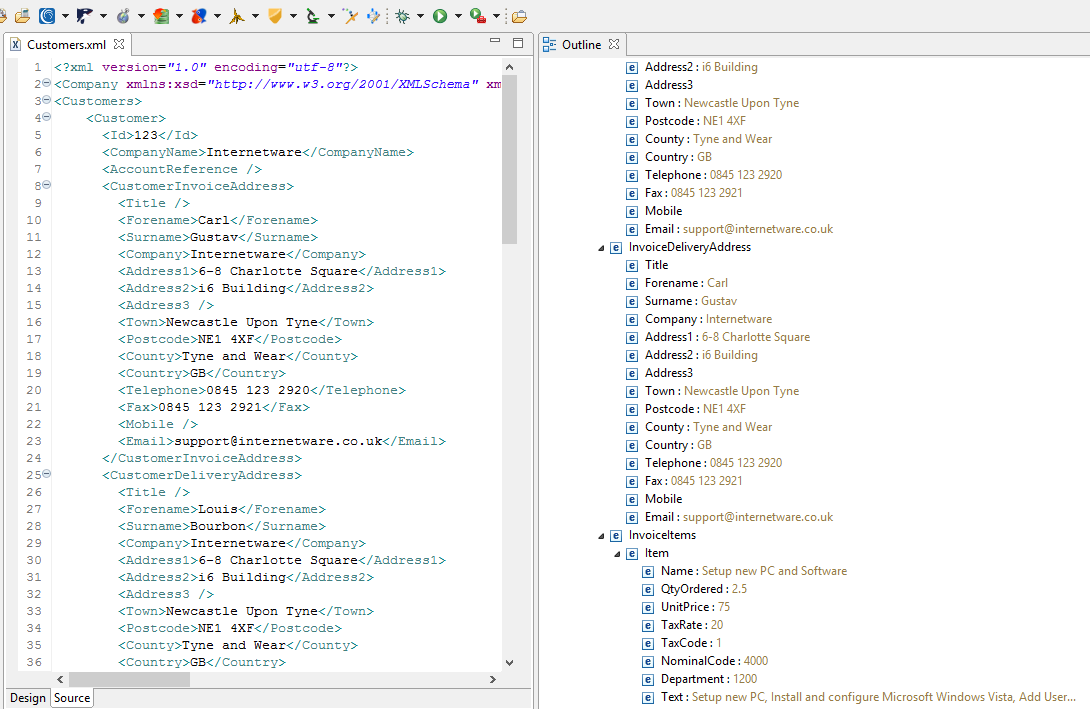
The left side shows file in a standard XML format, with customer information inside. On the right is that same data outlined in a more readable format. We can see the Forename “Carl” and Surname “Gustav” — and an address and telephone number — are exposed PII in this file.
In this example, we will only be masking people’s names. Similar techniques can be used to mask other PII within XML documents.
Forename and Surname Matcher
To search and mask this file, we need to open the New Dark Data Discovery Job Wizard from the Data Discovery dropdown menu. Select the source of this file, the target folder for remediated results, and the metadata information to accompany the results. If you are unfamiliar with this process, please refer to this blog article for assistance.
To begin, we want to create a new Search Matcher to match on Forenames and Surnames found under the Invoices element.1 Once we open the Search Matcher Details Dialog, we can start by adding a new XPath Filter by selecting Add under the Filters field:
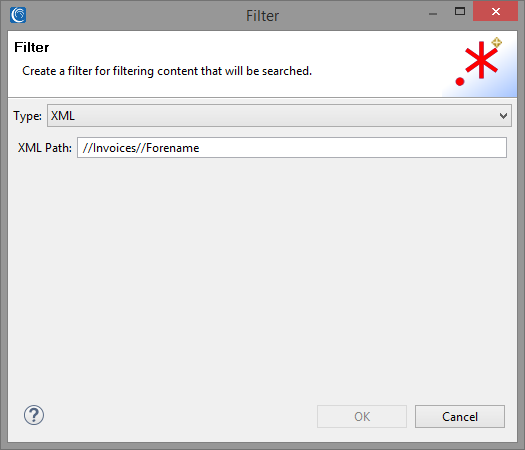
Select the type of the Filter as XML and enter the XPath query into the text box. This particular filter uses Recursive Descent (“//”) to help locate data without having to specify absolute paths.
The parser will substitute “//” for any arbitrary nested sequence of elements, in our case “Customers/Invoices/Invoice/InvoiceAddress/Forename. More simply, “//Invoices//Forename” searches for every instance of Forename within the Invoices element of the file.
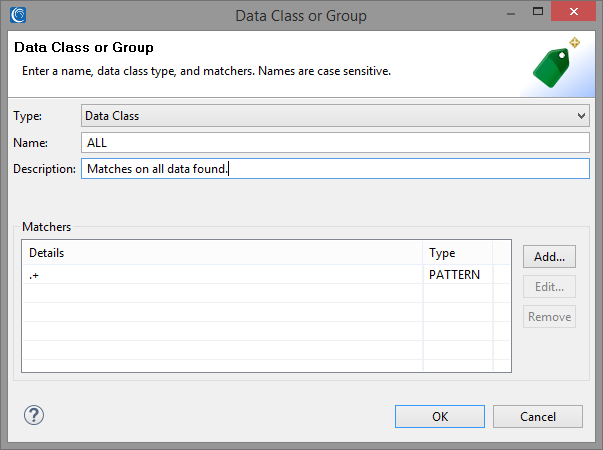
Every Search Matcher we create requires a Data Class in order to match on portions of the text. We can create a new Data Class from the Search Matcher details dialog by clicking on Create in the Data Class Name field, or by selecting an existing Data Class from our preferences by clicking Browse.
In our example, we will create a new Data Class which uses a RegEx pattern to match all characters. This is useful when a filtered element contains only the necessary data (a name, in this case) and does not need to be searched further.
Note that this Search Matcher will match on all content within file types other than XML, so make sure that only the XML file type is selected in the Source URI Dialog.
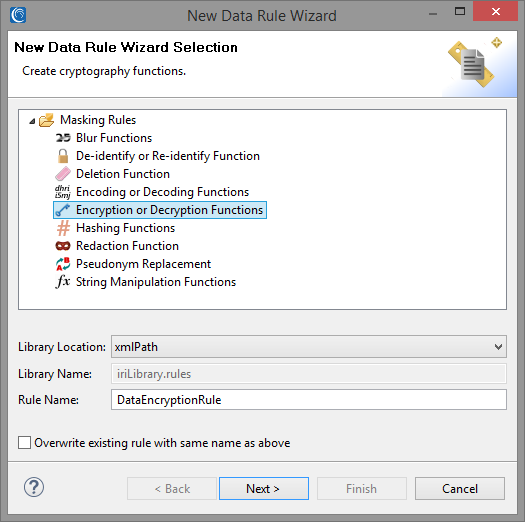
We also need to create a new Data Rule to mask our data. In the Data Rule field, click Create to open up the Data Rule Wizard.
This wizard provides a list of different masking functions that can be applied to your search results. Identifying what data that is going to be masked will help you decide what masking rule will be most suitable.
In this case, we are searching for Forename and Surname, so applying a rule that returns ciphertext that also looks like a name — while remaining a consistent and unique replacement that can preserve referential integrity — would be ideal.
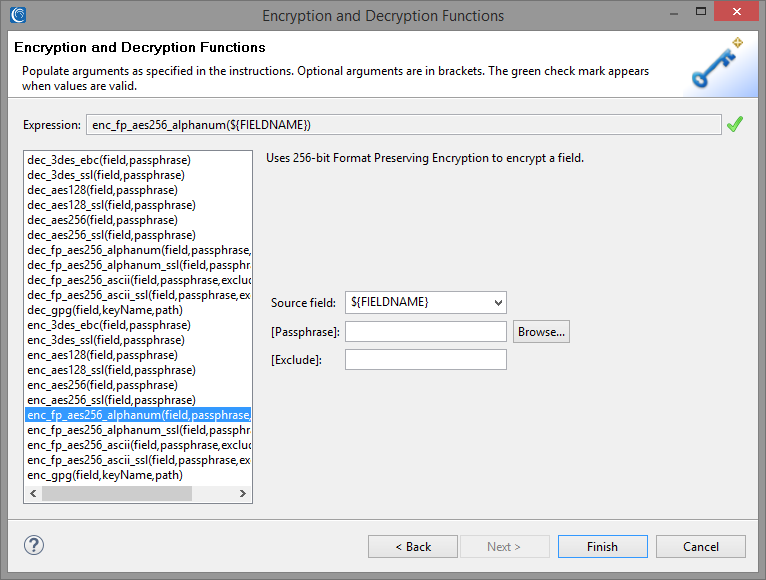
In this instance we will use an alphanumeric Format Preserving Encryption (FPE) encryption function that replaces the found value with like alphanumeric characters. Letters and numbers will be swapped for other letters and numbers in the same places. Original length, capitalization, and non-alphanumeric characters are also retained in this anonymization scheme.
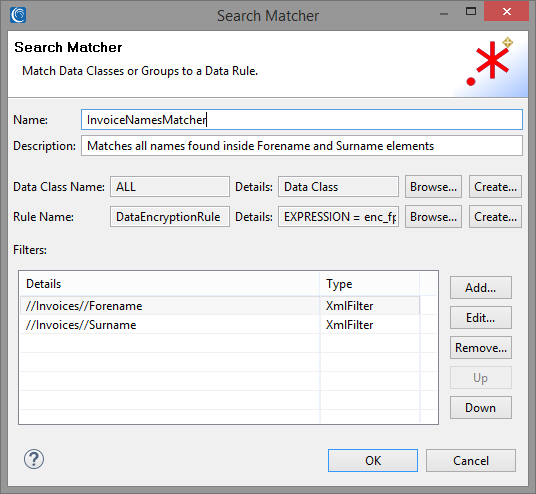
To match on Surnames within the Invoices element, we’ll add another XPath filter to our list of filters. We can create multiple filters for each Search Matcher, and as long as the element matches at least one filter in the list it will be found by the Search Matcher. The screenshot above represents the final state of the Search Matcher we have created for Invoice names.
Names in Free-Flowing Text
So far we have described a process for matching the entire content of the filtered elements, but we would also like to use our Search Matchers to intelligently search through free-flowing text embedded within certain elements. To do this, we will use a Named Entity Recognition (NER) matcher for finding names using natural language (contextual) clues in sentences.2
Since not all values within this XML contain sentences, we would like to create a Search Matcher that can filter only those elements which contain free-flowing text, and use an additional NER matcher to match on the portions of that filtered, unstructured text which contain PII.
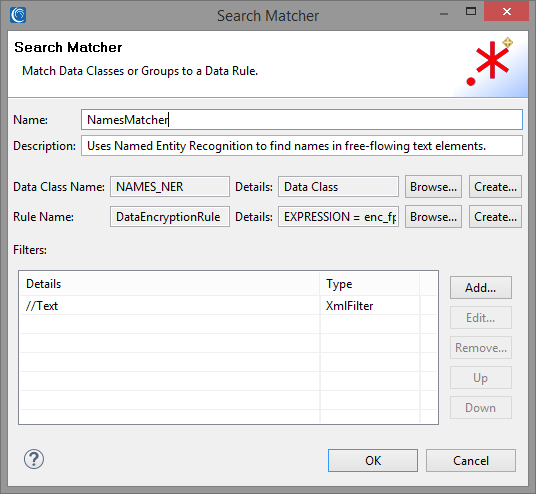
To that effect, we can add another Search Matcher to use a separate set of filters, Data Classes and Data Rules to find and match PII. In the screenshot above, we created another Search Matcher which uses a Data Class loaded with a NER model.
The XML will be filtered for any arbitrarily nested Text elements which contain free-flowing sentences. We can also reuse the same Data Rule as for the previous Search Matcher.
After finishing the wizard, a .search file is generated. Right-click and select Run As -> IRI Search and Remediate Job to find matches and mask them with the FPE rule we defined.
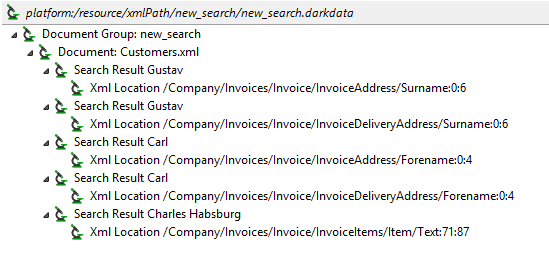
Shown above are the search results, including the XML location (with XPath and character offsets shown). Note how “Carl Gustav” was only matched in Invoices rather than the Customer element. Also note how “Charles Habsburg” was found in the Text element using NER.
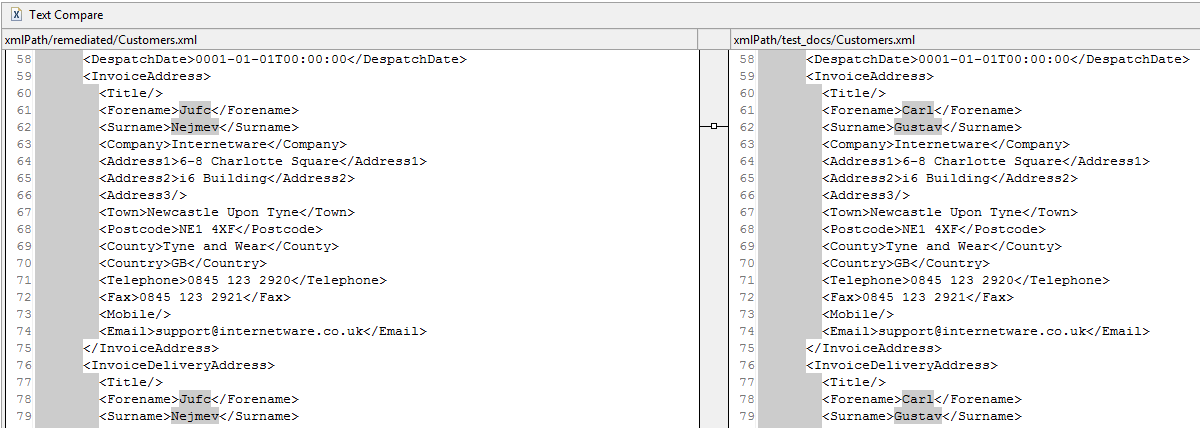
Snippet of the remediated results on the left in comparison to the original data on the right.

In the first screenshot above, you can see the original XML file on the right side that displays the name “Carl Gustav”. On the left side, the file shows the remediation with Format Preserving Encryption. Note how the ciphertext is the same in both cases, preserving referential integrity.
In the second screenshot, we put our NER model to use and it locates the name “Charles Habsburg”. This model is best used when working with documents or transcript values, as it uses Natural Language Processing (NLP) to find the name in the context of sentences.
If you need help to use DarkShield to find and mask PII in semi- or unstructured text sources in XML, JSON, or any other file, document, or image format, just ask your local IRI representative.
- Previously, we had to create a Data Class with a RegEx pattern to match on text that follows the given elements, and attach it to the Search Matcher. Using a regular expression to match on the XML structure is more error-prone however, and does not allow us to exclude arbitrarily nested Forenames and Surnames found under other elements like Customers. Filters do not share the same shortcomings, and allow for greater flexibility, since Data Classes need no longer be tailored to a particular semi-structured file layout, and can thus be reused in other file formats.
- Details on NER matchers, along with how to train your own NER models, will be discussed in a future blog article.










