
Connecting to Teradata in IRI Workbench
Introduction
The ability to directly move very large database (VLDB) data from/to, and manipulate it within IRI software is essential for those requiring:
- big data integration (ETL)
- database performance optimization (unloads, loads, reorgs, queries)
- database migration
- data masking (encryption, redaction, de-identification, etc.)
- data transformation, replication, or federation
- business intelligence (embedded reporting or hand-offs to analytic platforms)
- test data generation
As IRI Workbench users know, IRI software products in this Eclipse GUI environment (including Voracity, CoSort, FieldShield, NextForm, and RowGen) can connect to, process data from, and feed (via ODBC or pre-sorted bulk loads) data into:
- Oracle
- Sybase
- MySQL
- DB2
- SQL Server
- PostgreSQL
- others …
and, of course, all kinds of flat (and certain index and other) files.
The Connection
What’s new is direct access to data in Teradata tables for Teradata data integration, data masking and more, plus metadata creation (automatic if using FastLoad) for the definition and bulk load (via FastLoad and Multi-Load) of Teradata targets.
Teradata is an established leader in big data analytics, and like IRI, its software can consolidate data from different sources to make it available for processing and analysis. Also like IRI software, Teradata is chosen over other systems because it is linearly scalable, and offers extensive parallel data processing for data warehouse optimization.
Practical Applications of IRI Software Support for Teradata
Users migrating to (or from) Teradata systems can use IRI CoSort or IRI NextForm (DB edition) to acquire data from the existing VLDB, re-map it, and load it into the new environment quickly and easily. Either product can also transform, replicate, federate, and report on Teradata-based data in the file system.
For security purposes, IRI FieldShield or DarkShield can apply multiple data protection functions to any number of Teradata tables and columns. Available column-level security functions are listed on this page.
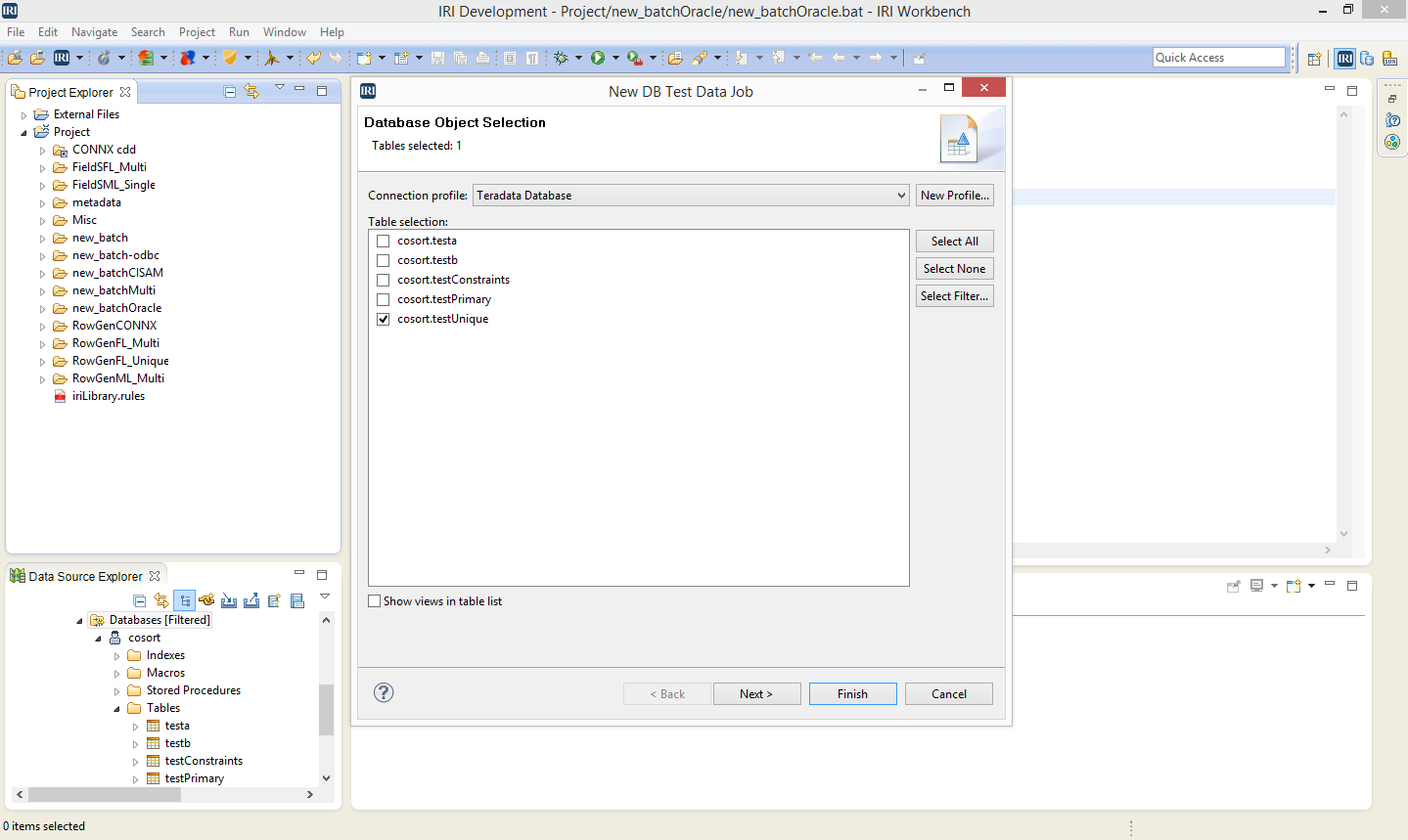
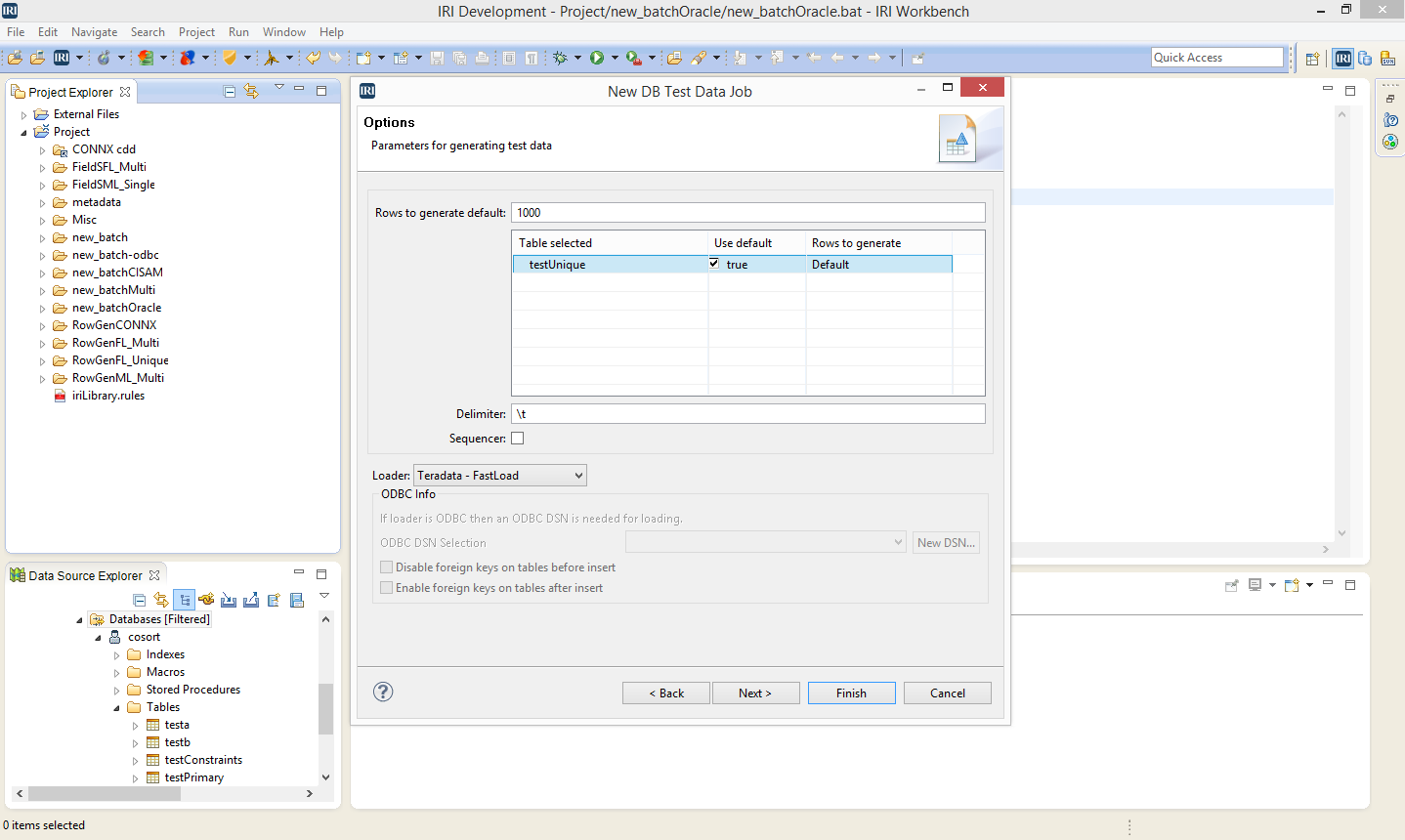
IRI RowGen can produce safe, intelligent, and referentially correct test data for Teradata tables, with or without the original production data. Only the DDL information provided through the JDBC connection in the IRI Workbench is needed. Click here to read the article on generating Teradata test data with IRI RowGen.
Note that all of the IRI tools mentioned above are bundled in the IRI data management platform called Voracity, which can also perform ETL for Teradata. If you would like more details on any of the capabilities in Voracity, please email info@iri.com.










