
Detecting Incremental Database Changes (Oracle to MongoDB ETL)
Detecting additions and updates to database tables for data replication, ETL, PII masking, and other incremental data movement and manipulation activities can be automated in IRI Voracity workflows designed and run in IRI Workbench (WB). This article explains how to regularly check for changes in Oracle source tables to decide when to move data into a MongoDB target. 1 Note however that in 2022, IRI also added the “Ripcurrent” module for automatic (real-time), incremental data replication and classified PII masking for selected relational databases.
In the example this article details, changed data is loaded into different databases or files using a task-scheduled batch file or shell script. This can be done using a timestamp and specific fields in the source table. Error checking is included and can also be reacted upon.
This example will be created and run on a Windows machine; however, it can be easily modified to work on a Linux or Unix like platform.
Creating the batch file is easy using a Voracity Flow diagram in WB. In this example, the source table contains columns named CREATION_DATE and UPDATE_DATE that are important in this job.
The image below shows the steps that are contained in the batch file. To summarize:
- the job is run in a specific directory
- an environment variable is set using the timestamp of the last job run
- the current timestamp is recorded
- current changes are captured
- the error level is checked and acted upon if successful or not
- the current timestamp overwrites the last run timestamp
- the changed data is converted to CSV
- a stall occurs to wait for the last file to exist
- the CSV file is imported into MongoDB
- the error level is checked, the current file is truncated
- the changes file is deleted

Note that it is also possible to add data cleansing and data masking functions to the target fields within the same job. Each task block in the workflow is explained below. For the how-to on building Voracity workflows from the palette, see this article.
Change Directory
This block changes the current working directory to the one specified.
Set LASTTIME
This command line block sets an environment variable called LASTTIME. The value set to the variable is the contents of the file LastTime.txt. The timestamp in this file is the timestamp that was recorded during the last run of this job. If this is the first run, this file will have to be made manually with an arbitrary timestamp dated before this job is run.
Timestamp.scl
This transformation block uses the CoSort SortCL program in Voracity to query the source database for the current time. That timestamp is saved to a file called LastTimeTemp.txt. The reason it is stored in a temp file is so that both the current and last time stamps can be preserved until error checking occurs.
It is important that the timestamp comes from the database, and not the local machine. This avoids problems where the database and the execution environment are not synchronized.
Changes.scl
This transformation block does a few things. Displayed below is the Transform Mapping Diagram for this block. Input is the source table and output is the file current.txt.
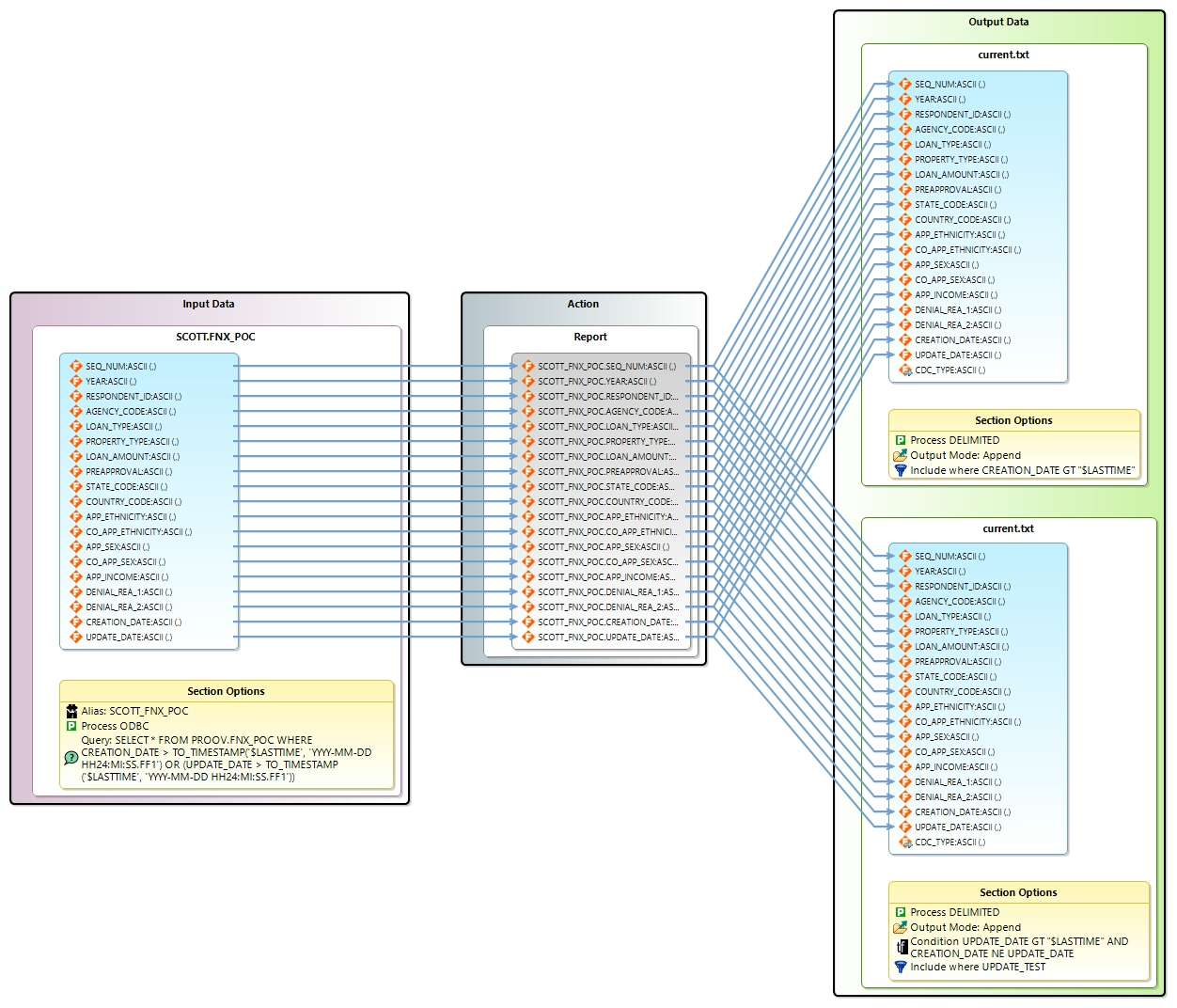
In the input Section Options, a query is submitted to the source table for all records that have a CREATION_DATE or UPDATE_DATE greater than the environment variable LASTTIME.
While the output appears to have two targets , the data is actually being appended to the same file using two different conditions. In the first output section, there is an Include statement that finds all records that have a CREATION_DATE greater than LASTTIME. There is also an additional output field called CDC_TYPE. The string “CREATE” is recorded in that new field.
In the second output section, an Include statement finds all records that have a UPDATE_DATE greater than LASTTIME and where CREATION_DATE is not equal to UPDATE_DATE. This ensures that newly created files are not included in this pass. The string “UPDATE” is recorded in CDC_TYPE.
Error CoSort
This decision block checks the variable ERRORLEVEL to make sure it returned 0 (or success) after running the CoSort job above. If it did not, the job continues to the EXIT block where the job is terminated. If it returns true, the job continues to the next block.
Rename LastTimeTemp
This command block copies the contents of LastTimeTemp.txt to LastTime.txt. This records the previously captured current timestamp in the file to be used for the next job run.
Convert.scl
This transform block takes current.txt and converts it to changes.csv. The conversion is from the default delimited file type to CSV. Using the CSV process type in CoSort prepends a header row to the output file using the field names. This is the task block where I could apply other manipulations (like data masking) to the data if I so choose.
Wait Files
This wait block stalls the batch file for 3 seconds and then checks for the existence of the changes.csv file before proceeding.
MongoImport
This command block executes the mongoimport command using the parameters specified in the properties view as shown below.
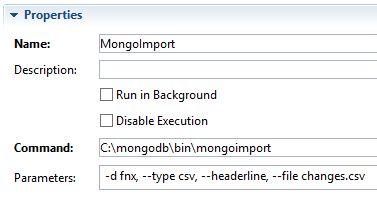
The parameters indicate that the MongoDB database called fnx is to be loaded with the contents of the file changes.csv which is of the type csv and contains a headerline which defines the fields.
Note that Voracity supports other methods of moving and manipulating MongoDB data. See this example of using Progress ODBC drivers for data masking using built-in “FieldShield” functions. Voracity can also process BSON data directly via API through /PROCESS=MongoDB support in CoSort v10, now too.
Error Loading
This decision block checks the variable ERRORLEVEL to make sure it returned 0 (or success) after importing into MongoDB. If it did not, the job continues to the Delete-Changes and EXIT blocks where the job is terminated. If it returns true, the job continues to the next block.
Truncate Current
This command block truncates the file current.txt. This is to clear out the records that were loaded into MongoDB. If the import failed and the block above exited the job, then these changed records are appended to on the next pass. Then, as the job repeated, they would be loaded into MongoDB with the next group of changed records.
Delete Changes
This command block deletes changes.csv so that the next pass is started with a newly created file for the pass.
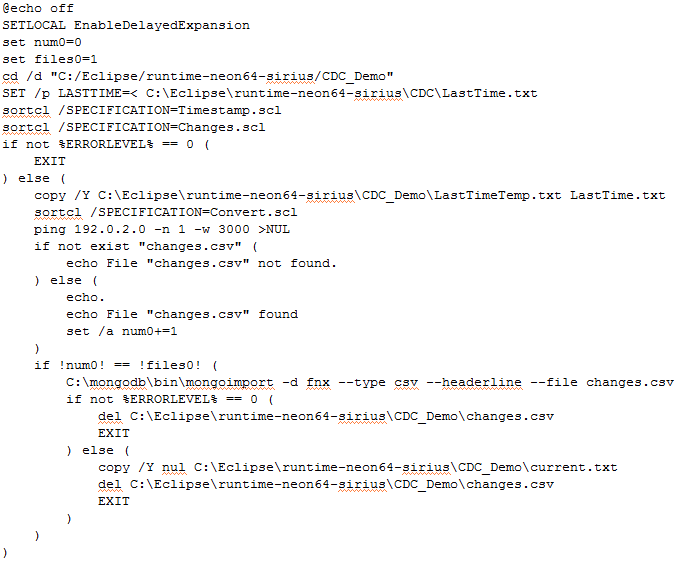
Batch File
The batch file and transformation scripts are created when the Flow diagram is exported. A copy of the batch file is below. Each block adds executable lines to the batch file.
Task Scheduler
Using the Windows Task Scheduler, this batch file can be executed repeatedly to capture the changes in the source database.
Conclusion
With a little planning, and the use of command blocks, changes to a database table can be detected automatically using a batch file, and then scheduled to run at selected intervals.
Contact voracity@iri.com or your IRI representative for more information or help with your use case
- This approach differs from third-party log-based change data capture solutions, which typically have performance bottlenecks, and are limited to specific databases, and do not enable simultaneous data transformation, PII data masking, cleansing, and reporting.










