
Textual ETL: Unlocking Unstructured Data
Synopsis
Corporations and government agencies store a lot of useful information in non-transactional semi-structured and unstructured data sources. Finding that data – in documents, logs, and images – is important not only for data masking, but also for textual ETL.
Textual ETL lends structure and meaning to data that’s hidden in text and prepares it for us in standard structural repositories like flat files, relational databases and Excel. When combined or joined to matching values in other structured sources, more information can be discovered and mined for the benefit of operational monitoring, marketing, trend analytics, law enforcement, etc.
Beyond enhancing data integration, these values can also be used in some test data scenarios as well. This article talks about producing structure from values discovered during file LAN or cloud 1 file searches using the IRI DarkShield data masking tool. And if you license the broader Voracity data management platform which includes DarkShield, you have the ETL and reporting facilities built-in.
How this Works
As you know, most data in unstructured sources is difficult to parse, and the values need context and structure to be leveraged in data integration and reporting contexts. Fortunately, the New File Search/Mask Job wizard in the IRI Workbench GUI will extract ‘dark data’ values (and log their metadata) into a flat file, which is what will ultimate enable textual ETL, data fabrics, and other forms or analytics in the IRI Voracity ecosystem, powered by SortCL.
To add value to the delimited log file, DarkShield also generates its field layouts automatically into a separate metadata file in IRI-standard data definition format (.DDF). The results file and its metadata repository are easily used and re-used by IRI software to integrate, transform, migrate, mask, and report on that data, and feed it in other formats or to external applications as needed.
Note again that in Voracity, the CoSort SortCL ETL engine can query and join over flat files directly, or facilitate the creation and population of tables with DBA-defined primary-foreign keys. In this way, dark data extracts can acquire form and relationships (structure) that can make it a lot more useful.
Creating the Search Job
A DarkShield Files Search Job will search every supported file type in every directory below the root network drive you specify. The scan through your dark data employs search methods you can align to your sensitive type types (e.g., names, email, IP and street addresses, credit card and NID numbers, medical conditions, etc.), or Data Classes.
You can specify search matchers based on the content of the data, fixed metadata (location), or both depending on the situation.When looking across all file types, you might want to specify a combination of regular expression patterns, lookup set files, and Named Entity Recognition (NER) models in addition to (metadata) location matchers for data in structured files.
Here is a list of file sources containing strings that the wizard can search, extract, and structure:
- Free-form text (.txt)
- Delimited Flat Files (.csv and .tsv)
- Fixed Width Files
- Microsoft Word documents (.doc and .docx)
- Adobe Portable Document Format (.pdf)
- Extensible Markup Language (.xml)
- Microsoft Excel spreadsheets (.xls and .xlsx)
- Microsoft PowerPoint presentations (.ppt and .pptx)
- JavaScript Object Notation files (.json)
- Parquet (.parquet)
- DICOM image (.dicom)
- Various image formats (.tiff, .jpeg, .png, .gif, .jp2, .jpx, .bmp)
You can create your DarkShield Files Search Job from the New File Search/Masking Job wizard:
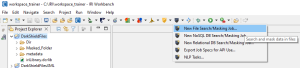
To launch the wizard, select the DarkShield menu dropdown and select the New Files Search/Masking Job… wizard. This brings up the first page where you can name the new job:
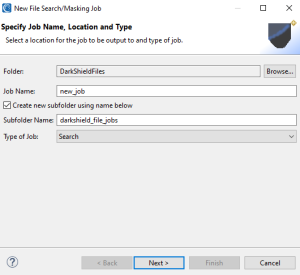
Here you specify the folder and file names for the data discovery artifacts, since we only want to perform a Search (vs. mask only or search and mask) job to extract data from files.
Click Next to move into this data source specification (files to be masked) page of the wizard:
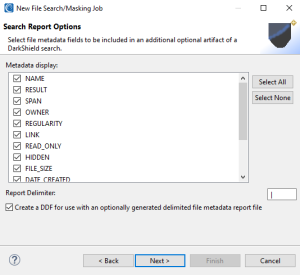
Here you can customize the content of the flat-file search log that would contain actual data. More specifically, you can also generate several metadata attributes of the flies where PII was discovered.
These attributes will be displayed as columns in a flat text log file containing the values (and specified metadata) from the search operation. The default delimiter is a pipe (“|”) but you can change that.
Note that the RESULT attribute contains the actual PII values found, so if you do not wish to persist (make use of the PII in the search report) do not select RESULT).
If you want to leverage the textual ETL functionality described below, check the option to create a Data Definition Format (DDF) file for the report. The DDF metadata defines the field layouts of the flat report which you can use in the SortCL textual ETL process below.
More specifically, the /FIELD names in the DDF file will correspond to the keywords and patterns you searched, as well as the forensic attributes that you selected in this dialog to be part of that output log/report.
Note that DarkShield search jobs also produce another log in JSON format named annotations.json which DarkShield renders in HTML charts like these. Machine-readable DarkShield logs can also be exported to third-party log analytic and action tools like Datadog and Splunk Phantom Playbooks.
Continue through the wizard by repeatedly clicking Next until you reach the page that will prompt for your data source or sources, on which data discovery will be performed. After which, click Finish and a DarkShield Search Job (.dsc) configuration file will be created.
For an in-depth look at the DarkShield Files Wizard and the different configuration options it supports (particularly for data masking), see this article.
Running the Search Job
To run a DarkShield Search Job, right click on the .dsc file and select IRI > Run Search Job.
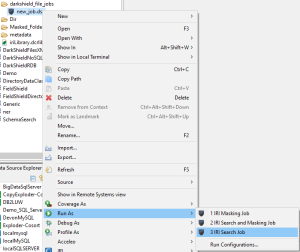
After running a Search Job, the search results and metadata are recorded inside files. Below is an extract of a sample comma-delimited DarkShield file-search log/report from a scan of Word, Excel, PDF, and image files stored in a local folder:
DATA_CLASS_NAME,PII_RESULT,SPAN,OWNER,READ_ONLY,HIDDEN,DATE_CREATED,DATE_MODIFIED,DATE_ACCESSED,FILE_PATH,FILE_TYPE "FIRST_NAME","Holder","8:14","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.855Z","2022-10-19T16:04:24.822Z","2022-10-21T21:32:30.039Z","FRIDAY_DEMO/input/Bank%20Report.xlsx","openxmlformats-officedocume" "FIRST_NAME","Jane","0:4","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.855Z","2022-10-19T16:04:24.822Z","2022-10-21T21:32:30.039Z","FRIDAY_DEMO/input/Bank%20Report.xlsx","openxmlformats-officedocume" "FIRST_NAME","Johnson","5:12","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.855Z","2022-10-19T16:04:24.822Z","2022-10-21T21:32:30.039Z","FRIDAY_DEMO/input/Bank%20Report.xlsx","openxmlformats-officedocume" "DATE_US_MMDDYYYY","04/07/2021","0:10","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.855Z","2022-10-19T16:04:24.822Z","2022-10-21T21:32:30.039Z","FRIDAY_DEMO/input/Bank%20Report.xlsx","openxmlformats-officedocume" "FIRST_NAME","John","0:4","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.859Z","2022-10-19T16:04:24.798Z","2022-10-21T21:32:30.046Z","FRIDAY_DEMO/input/Bank%20Statement.docx","openxmlformats-officedocume" "CREDIT_CARD_DS","5235-7345-1354-7345","0:19","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.885Z","2022-10-19T16:04:24.819Z","2022-10-21T21:32:30.058Z","FRIDAY_DEMO/input/buyers.xls","ms-excel" "PIN_US","421-55-7346","0:11","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.885Z","2022-10-19T16:04:24.819Z","2022-10-21T21:32:30.058Z","FRIDAY_DEMO/input/buyers.xls","ms-excel" "PHONE_DS","(310)55-7445","1:14","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.885Z","2022-10-19T16:04:24.819Z","2022-10-21T21:32:30.058Z","FRIDAY_DEMO/input/buyers.xls","ms-excel" "EMAIL","jhelly@gmail.com","0:16","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.885Z","2022-10-19T16:04:24.819Z","2022-10-21T21:32:30.058Z","FRIDAY_DEMO/input/buyers.xls","ms-excel" "FIRST_NAME","Johnson","0:7","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.885Z","2022-10-19T16:04:24.819Z","2022-10-21T21:32:30.058Z","FRIDAY_DEMO/input/buyers.xls","ms-excel" "FIRST_NAME","Doe","35:38:00","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.879Z","2022-10-19T16:04:24.800Z","2022-10-21T21:32:30.048Z","FRIDAY_DEMO/input/bank_info.jpg","image/jpeg" "CREDIT_CARD_DS","6011-4256-2332-1212","60:18:00","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T14:27:25.879Z","2022-10-19T16:04:24.800Z","2022-10-21T21:32:30.048Z","FRIDAY_DEMO/input/bank_info.jpg","image/jpeg" "FIRST_NAME","Bay","947:35:00","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T19:21:47.202Z","2022-10-20T19:06:32.105Z","2022-10-21T21:32:30.076Z","FRIDAY_DEMO/input/Sample%20Policy.pdf","application/pdf" "FIRST_NAME","Ridge","951:41:00","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T19:21:47.202Z","2022-10-20T19:06:32.105Z","2022-10-21T21:32:30.076Z","FRIDAY_DEMO/input/Sample%20Policy.pdf","application/pdf" "FIRST_NAME","Jack","1109:15:00","DESKTOP-8NLA23I\adaml","FALSE","FALSE","2022-10-20T19:21:47.202Z","2022-10-20T19:06:32.105Z","2022-10-21T21:32:30.076Z","FRIDAY_DEMO/input/Sample%20Policy.pdf","application/pdf"
Using the Results
Because we chose to create the DDF metadata for this log file, the data above can be leveraged in SortCL operations to report on (e.g, aggregate), extract, transform, or restructure the data within the search log as we demonstrate below. First, here is the DDF file layout for log data above: for the above log data., i.e.,
DDF File for Use in Script 1 below
# Generated with IRI Workbench - Discover Metadata # Author: chaitalim # Created: 2024-03-14 14:27:11 /FILE=InputFiles/DelmitedDarkShieldSearchLogSample.csv # /PROCESS=CSV /FIELD=(DATA_CLASS_NAME, TYPE=ASCII, POSITION=1, SEPARATOR=",", FRAME="\"", CDEF="DATA_CLASS_NAME") /FIELD=(PII_RESULT, TYPE=ASCII, POSITION=2, SEPARATOR=",", FRAME="\"", CDEF="PII RESULT /FIELD=(SPAN, TYPE=ASCII, POSITION=3, SEPARATOR=",", FRAME="\"", CDEF="SPAN") /FIELD=(OWNER, TYPE=ASCII, POSITION=4, SEPARATOR=",", FRAME="\"", CDEF="OWNER") /FIELD=(READ_ONLY, TYPE=ASCII, POSITION=5, SEPARATOR=",", FRAME="\"", CDEF="READ_ONLY") /FIELD=(HIDDEN, TYPE=ASCII, POSITION=6, SEPARATOR=",", FRAME="\"", CDEF="HIDDEN") /FIELD=(DATE_CREATED, TYPE=ASCII, POSITION=7, SEPARATOR=",", FRAME="\"", CDEF="DATE_CREATED") /FIELD=(DATE_MODIFIED, TYPE=ASCII, POS=8, SEP=",", FRAME="\"", CDEF="DATE_MODIFIED") /FIELD=(DATE_ACCESSED, TYPE=ASCII, POS=9, SEP=",", FRAME="\"", CDEF="DATE_ACCESSED") /FIELD=(FILE_PATH, TYPE=ASCII, POSITION=10, SEPARATOR=",", FRAME="\"", CDEF="FILE_PATH") /FIELD=(FILE_TYPE, TYPE=ASCII, POSITION=11, SEPARATOR=",", FRAME="\"", CDEF="FILE_TYPE")
You can leverage this metadata in the two-script (or single batch) SortCL job shown below to extract, transpose and group the PII result data by data class in a flattened format for multiple uses:
SortCL Job Script 1 (Extract):
# This job reads the file containing Data Class names in one column and a related value # another column (the PII) to output row and column data for input to transpose script. /INFILE=InputFiles/DelmitedDarkShieldSearchLogSample.csv /PROCESS=CSV /SPECIFICATION=metadata/DarkShieldSearchLog.ddf # metadata shown above /SORT # to create a unique list of column names and row values /KEY=DATA_CLASS_NAME /KEY=PII_RESULT_OPTIONAL # By default duplicate values for a Data Class will be excluded from the output. # If you need all values retained, then comment the line below, i.e # /NODUPLICATES /NODUPLICATES # This target will be the input to the transpose script /OUTFILE=WorkFiles/FileRowColumnData.csv /PROCESS=RECORD /FIELD=(ROW_NUM,POSITION=1, SEPARATOR="," ) /FIELD=(DATA_CLASS_NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /COUNT ROW_NUM RUNNING BREAK DATA_CLASS_NAME /FIELD=(PII_RESULT, TYPE=ASCII, POSITION=3, SEPARATOR=",", FRAME="\"")
This produces a work file (which you should subsequently delete) needed in the next job, like this:
1,ACC_NUMBER,"1001001234" 2,ACC_NUMBER,"123456" 3,ACC_NUMBER,"123456718735" 1,CREDIT_CARD_DS,"040392-5967562" 2,CREDIT_CARD_DS,"1134-6845-9545-3453" 3,CREDIT_CARD_DS,"120486-7863214" 4,CREDIT_CARD_DS,"1624-7457-4567-4545" . . .
SortCL Job Script 2 (Transform & Load):
# This job reads the data file from the prior extract script and outputs a transposed file # with columns containing each data class (PII type) and rows for each data value /INFILE=WorkFiles/FileRowColumnData.csv /PROCESS=DELIMITED /FIELD=(ROW_NUM, TYPE=ASCII, POSITION=1, SEPARATOR=',', FRAME='"') /FIELD=(COL_NAME, TYPE=ASCII, POSITION=2, SEPARATOR=',', FRAME='"') /FIELD=(COL_VALUE, TYPE=ASCII, POSITION=3, SEPARATOR=',', FRAME='"') /INREC /FIELD=(ROW_NUM, POSITION=1, SEPARATOR=',', NUMERIC) /FIELD=(VALUE_1, POSITION=2, TYPE=ASCII, SEPARATOR=',', IF COL_NAME EQ "ACC_NUMBER" THEN COL_VALUE) /FIELD=(VALUE_2, POSITION=3, TYPE=ASCII, SEPARATOR=',', IF COL_NAME EQ "CREDIT_CARD_DS" THEN COL_VALUE) /FIELD=(VALUE_3, POSITION=4, TYPE=ASCII, SEPARATOR=',', IF COL_NAME EQ "DATE_US_MMDDYYYY" THEN COL_VALUE) /FIELD=(VALUE_4, POSITION=5, TYPE=ASCII, SEPARATOR=',', IF COL_NAME EQ "EMAIL" THEN COL_VALUE) /FIELD=(VALUE_5, POSITION=6, TYPE=ASCII, SEPARATOR=',', IF COL_NAME EQ "FIRST_NAME" THEN COL_VALUE) /FIELD=(VALUE_6, POSITION=7, TYPE=ASCII, SEPARATOR=',', IF COL_NAME EQ "LAST_NAME" THEN COL_VALUE) /FIELD=(VALUE_7, POSITION=8, TYPE=ASCII, SEPARATOR=',', IF COL_NAME EQ "PHONE_DS" THEN COL_VALUE) /FIELD=(VALUE_8, POSITION=9, TYPE=ASCII, SEPARATOR=',', IF COL_NAME EQ "PIN_US" THEN COL_VALUE) /SORT /KEY=(ROW_NUM) /OUTFILE=OutputFiles/DarkShieldSearchLogTransposed.csv /PROCESS=CSV /HEADREC="ACC_NUMBER,CREDIT_CARD_DS,DATE_US_MMDDYYYY,EMAIL,FIRST_NAME,LAST_NAME,PHONE_DS,PIN_US\n" /FIELD=(VALUE_MAX_1, POSITION=1, TYPE=ASCII, SEPARATOR=',', FRAME='"') /MAX VALUE_MAX_1 FROM VALUE_1 BREAK ROW_NUM /FIELD=(VALUE_MAX_2, POSITION=2, TYPE=ASCII, SEPARATOR=',', FRAME='"') /MAX VALUE_MAX_2 FROM VALUE_2 BREAK ROW_NUM /FIELD=(VALUE_MAX_3, POSITION=3, TYPE=ASCII, SEPARATOR=',', FRAME='"') /MAX VALUE_MAX_3 FROM VALUE_3 BREAK ROW_NUM /FIELD=(VALUE_MAX_4, POSITION=4, TYPE=ASCII, SEPARATOR=',', FRAME='"') /MAX VALUE_MAX_4 FROM VALUE_4 BREAK ROW_NUM /FIELD=(VALUE_MAX_5, POSITION=5, TYPE=ASCII, SEPARATOR=',', FRAME='"') /MAX VALUE_MAX_5 FROM VALUE_5 BREAK ROW_NUM /FIELD=(VALUE_MAX_6, POSITION=6, TYPE=ASCII, SEPARATOR=',', FRAME='"') /MAX VALUE_MAX_6 FROM VALUE_6 BREAK ROW_NUM /FIELD=(VALUE_MAX_7, POSITION=7, TYPE=ASCII, SEPARATOR=',', FRAME='"') /MAX VALUE_MAX_7 FROM VALUE_7 BREAK ROW_NUM /FIELD=(VALUE_MAX_8, POSITION=8, TYPE=ASCII, SEPARATOR=',', FRAME='"') /MAX VALUE_MAX_8 FROM VALUE_8 BREAK ROW_NUM
Note that the output in this case was defined as a single CSV file, but SortCL also supports one or more outputs of this data into differently formatted files (e.g., fixed position, JSON, XML, and XLS/X) as well as any ODBC-connected database table. Here are the results of this job in spreadsheet form:
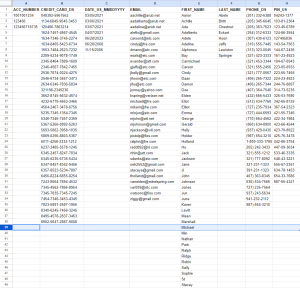
The output from this SortCL job produces unpivoted, through unrelated structured data; i.e., no logical association (relationship) between these data elements is likely to exist. More specifically, the results of the DarkShield search through files are now available for several uses, including:
- PII Audits – review of all values in each data classes to show what was found / vulnerable, which from Excel can also be aggregated and graphed as necessary; see also this solution built into DarkShield for graphical PII discovery results
- ETL – run join / lookup transformations that match like values in structured sources to learn more from the associated values in those rows; see this follow-on article for a continuation of this job the performs the join on email address.
- Testing – these scrambled data values can be used for certain logicless but realistic test sets
- Segmented delivery – Selected columns can be sent to individual files in the second script using the /NEWFILE statement for those with specific PII type (data class) need to know
If you have any questions about PII search/mask in DarkShield or textual ETL in Voracity, please email us at voracity@iri.com.










