What is Data Franchising?
Data franchising is the 2003 term coined by Richard Sherman of Athena Solutions to refer to the staging or packaging of large data sets into clean, usable chunks for decision-making, particularly through business intelligence (BI) and analytic software. Newer terms for the preparation of data for these ends include data blending, data munging, and data wrangling.
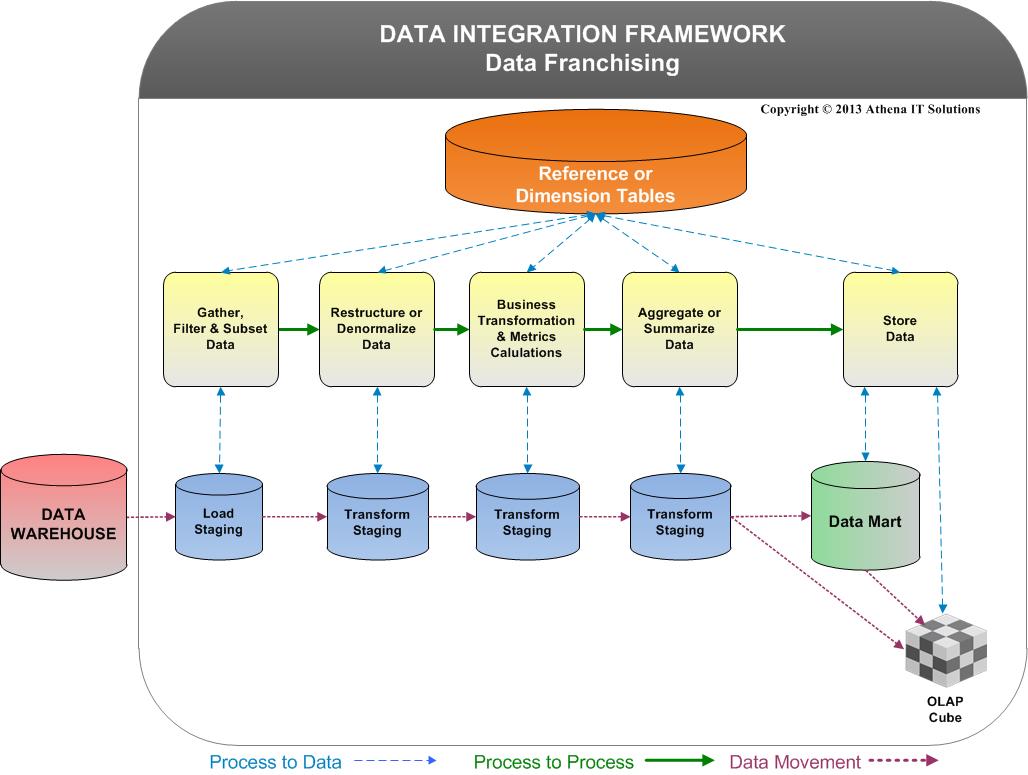
To improve the usability and performance of BI and analytic tools, the IRI data manipulation program (SortCL) — which is the default engine in the IRI CoSort product and IRI Voracity platform — rapidly prepares CSV and XML “feed” files or ODBC tables ready for consumption. This primary benefit of this external data preparation is efficiency; it removes the overhead of integrating data from the BI layer.

SortCL takes very large input data from mainframe data sets, very large relational or NoSQL databases, device or web logs, HDFS, cloud apps, and other files, and performs one or more data integration and staging functions simultaneously that result in one or more outputs, such as:
- select/filter
- sort/merge
- aggregate/calculate
- match/join
- cleanse/enrich
- encrypt/mask
- convert/reformat
- pivot/unpivot
- substring/custom
By integrating large volumes of sequential data in the file system, SortCL takes the overhead of data transformation out of the BI layer. By combining and multi-threading the big data manipulations, SortCL also saves job design, computation, and I/O cycle time. Savings also manifest in the BI front-end, since query and display (responses) are faster with smaller inputs.
CoSort’s SortCL is routinely used for data franchising into BI platforms like BIRT, Business Objects, Cognos, Cubeware, Microstrategy, QlikViewk, Spotfire, Splunk, Tableau, and Excel spreadmarts. IRI also partners directly with best-of-breed dashboard and analytic vendors like Crossing Technologies, Dimensional Insight, IVIZ Group (iDashboards), and NextCoder (DW Digest) to populate the displays in those platforms. SortCL can also prepare data for SOA, web services, data modeling, security, and advanced statistical applications like R, SAS and SPSS.
Once the prepared data has been ingested into the BI platform, users can continue to run a variety of custom queries, modifications, and dynamic reports to visualize, and interact with, data at multiple levels of granularity, and cycle their data through additional query and display processes.
Because the IRI Workbench IDE supporting CoSort and Voracity runs on Eclipse, Business Intelligence Reporting Tool (BIRT) or KoNstanz Information MinEr (KNIME) users can consume SortCL data targets directly, and produce custom reports in the same environment. They can even specify an IRI Data Source in BIRT through ODA or in a purpose-built Voracity provider for KNIME to combine data integration in the same runtime operation with the reporting, analytics, machine learning, and other data science activities.
Finally, SortCL itself also includes standard reporting functionality. This means you can actually run detail, summary, and delta reports (usually in batch processes), and still franchise data for more sophisticated BI tools — at the same time. It is for this reason, as well as its tie-ins to third-party analytics tools above, that 15 years later (in 2018), BI/DW industry guru Dr. Barry Devlin named IRI Voracity a Production Analytic Platform.
See the business intelligence section of the IRI web site for details about all the above, or contact your IRI representative for assistance.