Using Selection to Reduce Data Bulk (and Improve Data…
One of the best ways to speed up big data processing operations is to not process so much data in the first place; i.e. to eliminate unnecessary data ahead of time. Data can be culled en masse by specifying the collection, processing, or output of only a certain number of rows, or more intelligently with selection criteria in which certain conditions must be met for the data to be included in, or omitted from, processing.
In IRI CoSort (data transformation and reporting), IRI NextForm (data, file and DB migration), IRI FieldShield (data masking), and even IRI RowGen (test data generation) job scripts, you can apply SQL-like WHERE filters at the input, action, and output phases of each job. These filters are defined, stored, and effected in the CoSort Sort Control Language (SortCL) program common to all IRI tools to avoid the reading, processing, and/or targeting of data you simply do not need at each logical phase of a job.
First let’s cover de-duplication. If you use CoSort or the IRI Voracity platform that does, SortCL’s /NODUPLICATES command will remove the second and successive rows in any job that sorts when their key values match; i.e., only the key fields (not the records) must compare equally to be removed. Conversely, you can specify /DUPLICATESONLY so only records containing key fields that compare equally are processed and output. You can see how either function can save time in processing large data sets.
Conditions for the /INCLUDE and /OMIT statements in IRI software can be simple or elaborate, based on unary changes in data, or complex boolean logic. These conditions can be defined at the field (column) or record (row) level, and expressed in both SortCL text scripts or in the IRI Workbench GUI which creates and runs those scripts. In the GUI, built on Eclipse, you can either hand-write or create job scripts through a wizard or dialog editors that reflect your business rules for filtering data.
The example input file below contains a list of transactions over a given year:

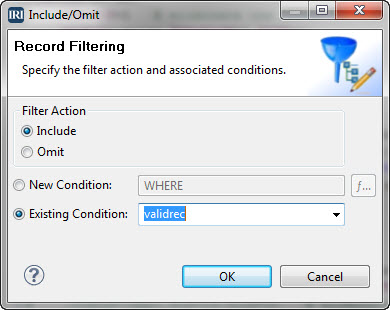
Conditions can be expressed explicitly in job scripts (for example, /INCLUDE WHERE AGE GT 55 AND GENDER EQ “MALE” ) or implicitly through defined and named conditions like this one:

The particular filter in this case is an include action where the records meeting the condition ‘validrec’ are selected for processing.

The result of this filter transformation is automatically reflected in the overall job script shown below, and supported by its dynamic outline to the right:

Only those records meeting the ‘validrec’ condition are input to the sort and displayed on output:

The other conditions associated with that particular data source were not used in subsequent filtering, formatting, or aggregation statements in this job, but could be.
See also:
http://www.iri.com/solutions/data-transformation/select-filter
http://www.iri.com/blog/data-protection/selecting-pii-for-secure-queries-fieldshield-filters/










