PII Masking in MongoDB (3rd Method)
Note: This article covers the third available IRI customer method for statically masking or encrypting PII in structured MongoDB collections through the IRI FieldShield product or IRI Voracity platform (both powered by IRI CoSort v10 and its support of the native MongoDB driver). A fourth method is now available for finding and masking PII floating in unstructured MongoDB collections through IRI DarkShield.
This article explains how new, native MongoDB collection support in IRI’s data manipulation products enables the rapid performance and consolidation of multiple data-centric functions, including:
- data profiling & cleansing
- data masking & re-ID risk scoring
- data integration (ETL) & CDC
- data migration & replication
- custom report & test data generation
The API-level support for MongoDB data is offered in the core SortCL program, which is the default processing engine of the IRI Voracity data management platform, as well as its subset products: CoSort, NextForm, FieldShield, and RowGen. This connection method is the third, and fastest, way that IRI customers can acquire and manipulate data in MongoDB collections. The first is via flat files as described in 2014 here. The second is with ODBC and JDBC drivers described in 2016 here.
About MongoDB
MongoDB is a “NoSQL”, document-oriented database which works on the concept of collections and JSON-like documents with schemas. A collection, like a relational database table, contains one or more documents.
A document is a set of key-value pairs. Documents have dynamic schema, which means that documents in the same collection do not need to have the same set of fields or structure. Common fields in a collection’s documents may hold different types of data.
The following chart compares the terminology of an RDBMS and MongoDB:
| Oracle | MongoDB |
|---|---|
| Database | Database |
| Table | Collection |
| Row | Document |
| Column | Field |
| Primary Key | Object ID provided by MongoDB |
Demonstration
My example below does a simple sort, mask, and movement of a MongoDB collection called “chiefs” into another collection, and also out to a standalone JSON file. JSON files are another new IRI data source supported in the release of CoSort v10.
Database Connection
The first step is to establish connectivity with your MongoDB instance in IRI Workbench. Built on Eclipse, IRI Workbench is the common job design and deployment IDE for all the IRI software listed above. It’s also where you can connect to other DBs, HDFS, and additional data sources in local or remote file systems.
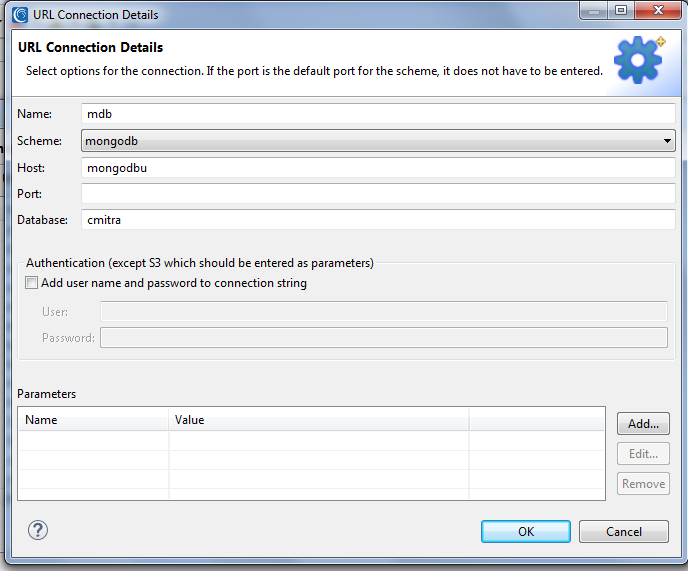
From the IRI Menu (swirl icon) in the Workbench toolbar, select IRI Preferences > IRI > URL Connection Registry > Add. Specify an existing MongoDB from the schema and the server hostname. My DB’s name is cmitra, created on the ‘mongodbu’ host:
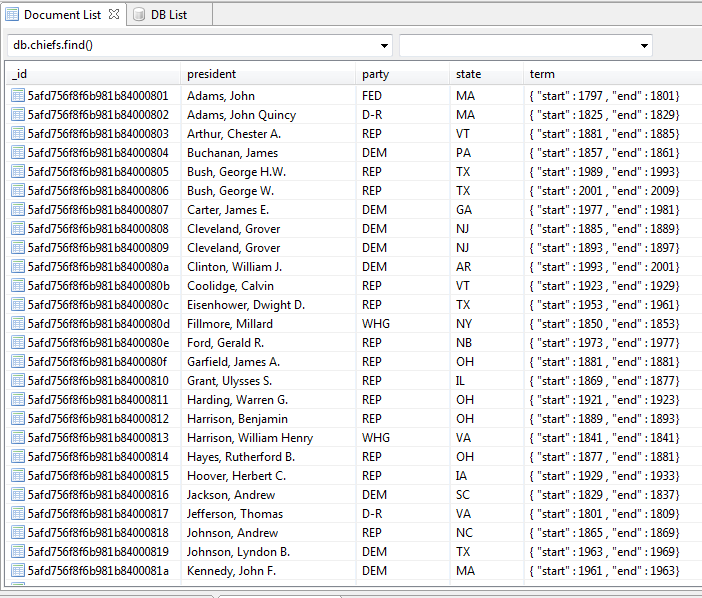
For convenience, I installed the free MonjaDB plugin for Eclipse to interact with the database within my Workbench perspective. My collection contains US Presidents by name, party, state, and their term dates. MongoDB assigned a unique ID for each document:
Metadata Definition
Before I can process MongoDB data in this mode, I must create a data definition format (DDF) file that lays out my collection documents in /FIELD statements for use in SortCL-compatible jobs like FieldShield. As with other data sources supported in Workbench, a wizard does this for me automatically.
Create (or select an existing) Project Folder in Workbench to store the job assets like the source metadata, SortCL script/diagram, saved masking rules, data classes, etc. With that folder active (highlighted) and knowledge of my MongoDB collection’s location, I can now run the Discover Metadata wizard from the IRI menu in the top toolbar.
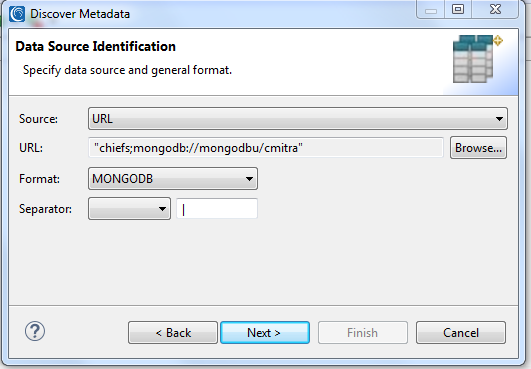
In this Data Source Identification step, I can select an ODBC connection, file-browse, or URL. In this case, I am reaching MongoDB via URL, so I choose that and MongoDB for my format. After browsing for the database registry entry I previously added, I enter the collection name. The wizard prepends this to the standard MongoDB connection string.
The Data Viewer and Field Editor page connects to the collection and previews its column contents and columns as SortCL field names:
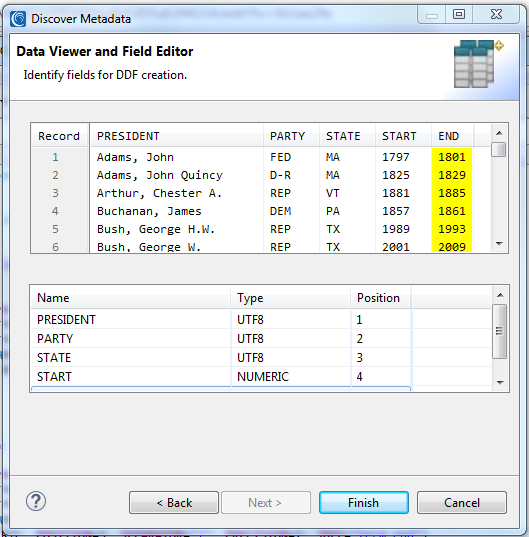
When I click Finish, my DDF file is created and displays as follows:
/FIELD=(PRESIDENT, TYPE=UTF8, POSITION=1, SEPARATOR="|", MDEF="president")
/FIELD=(PARTY, TYPE=UTF8, POSITION=2, SEPARATOR="|", MDEF="party")
/FIELD=(STATE, TYPE=UTF8, POSITION=3, SEPARATOR="|", MDEF="state")
/FIELD=(START, TYPE=NUMERIC, POSITION=4, SEPARATOR="|", MDEF="term.start")
/FIELD=(END, TYPE=NUMERIC, POSITION=5, SEPARATOR="|", MDEF="term.end")
This DDF metadata can be used in any job (or jobs) affecting this collection, including the one in this example as shown below. The _id column is unneeded for my purposes was omitted.
Note the use of dot notation in the “MDEF” attribute, which is a required path definition to discrete, flat elements SortCL jobs process. Multi-value and sub document array elements get generated in sequence starting with 0 in their order of appearance.
Run the Job Design Wizard
Workbench includes many different fit-for-purpose wizards for generating the metadata for running discrete tasks (.*cl scripts) or batch-driven jobs (.flow and .bat/.sh files) on the command line, through Workbench, your programs, etc.
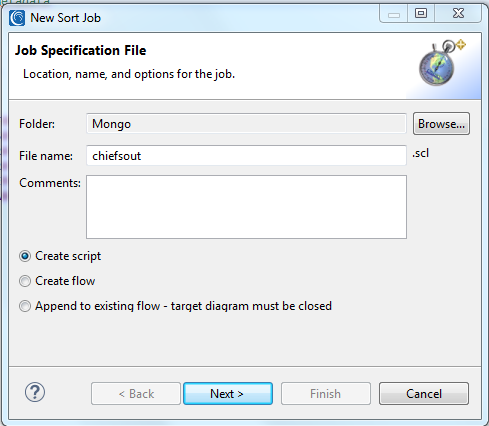
I chose a basic sort transform wizard because within it I can add multiple targets, mask output fields, etc. This wizard runs from the CoSort menu group (stopwatch) icon from the toolbar. I select New Sort Job and specified chiefsout.scl as the name of my job:
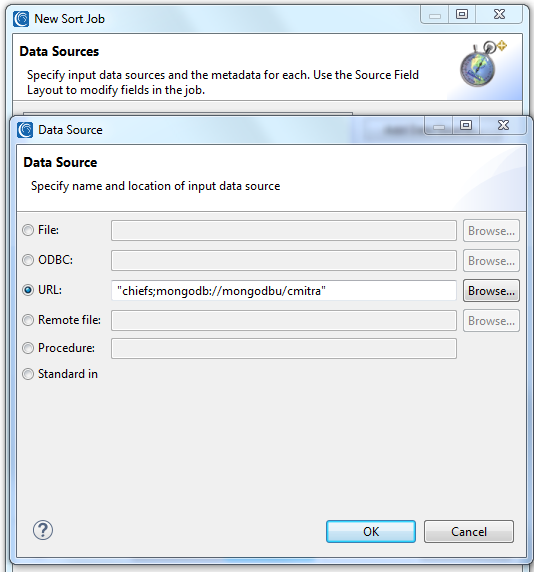
In the next step, I identify the name of my source MongoDB collection and where it is, using the same locator URL used during the metadata definition for “chiefs”:
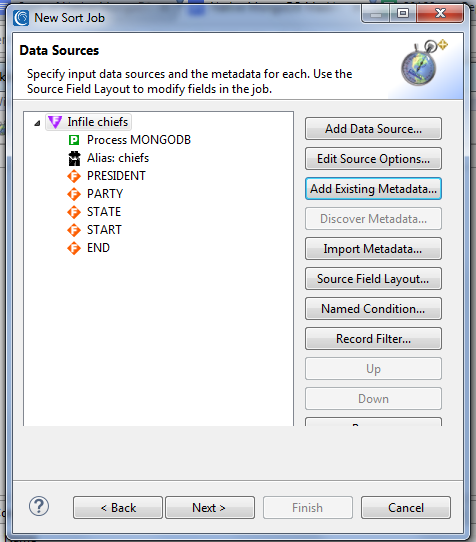
The next step is to specify the generation, or use of existing, metadata for the collection in the data definition (DDF) format required in all SortCL-compatible programs. In this case, I will use the DDF file I created in Step 2 above. I select Add Existing Metadata to put these layouts directly into my job script as input specifications, and they then get reflected in the dialog below:
On the next page, I specify a sort key field to define the order of data in my target(s). In this case, I will go from the default chronological order of presidents and sort them by name:
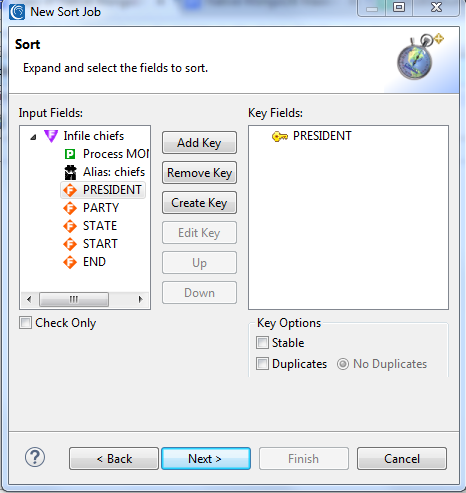
After clicking Next, the Data Targets page displays. As with my source options, there are several different kinds of targets I can create and format through this wizard and also later in another job design mode (e.g., script editor).
This and other Workbench wizards allow me to keep adding targets, and granularly defining the contents of each one. Target-specific attributes include: format (e.g., CSV, MongoDB, MFVL), formatting (e.g., headers and footers, rows to skip, etc.), filter conditions, field-level layouts, and applied functions/rules (e.g., new data types, masks, expression logic, aggregation).
In the Data Targets page, I know that I want two targets: a standalone JSON file and a remote MongoDB collection. Thus, I click Add Data Target and begin specifying the first one. Unless I edit the target options or target field layout, my output will only contain the sorted version of the input data as is. That’s what my JSON target file will contain by simply my naming it..
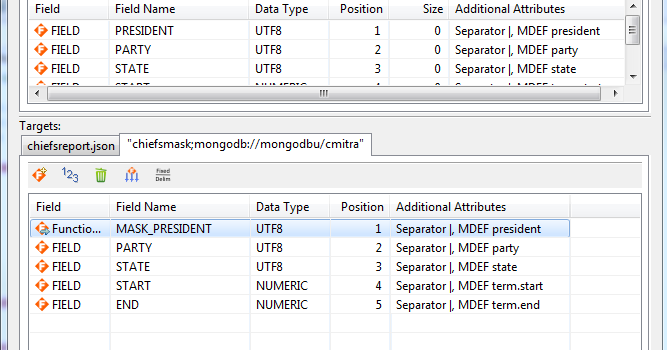
When I again click Add Data Target I define the second as a MongoDB collection via URL. My new chiefsmask collection will automatically build and populate when I run the job. It is within that target that I want one of the fields masked for privacy, the President’s names in this case. I click on Target Field Layout to open a top-to-bottom mapping page for my source and targets:
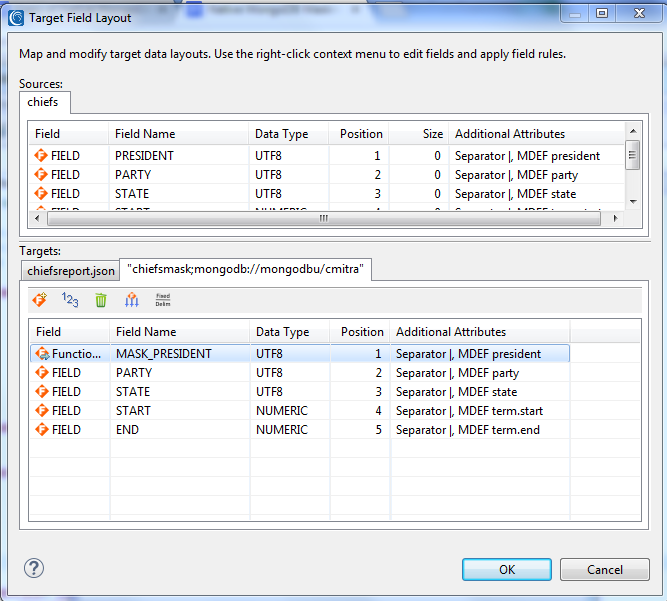
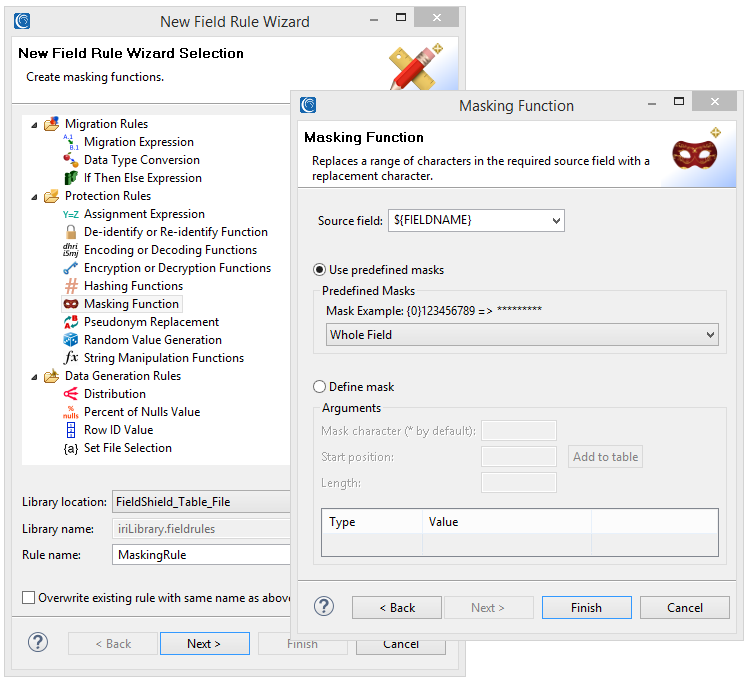
This page also shows my masking rule already defined. I had defined that by right-clicking on PRESIDENT in the target and clicking Create Rule (instead of browsing to an existing one). That opened a list of field-level protection wizards, shown below. Note that more static data masking functions are available.
I selected Masking (character redaction). On that page, I took the full-field default to mask out the entire President’s name in the target collection:
After finishing these selections, I am returned to the mapping dialog. I click OK and return to the Data Targets page. At the end of my changes, I will wind up with the details below:
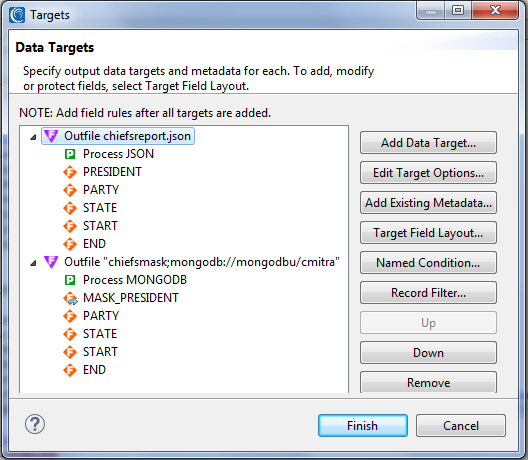
I click OK to end the wizard and build the job.
Review the Job
With the chiefsout.scl job now built in my active project and open for me in the editing window automatically, I can see and modify it from there, or through available in-context dialog pages. Learn about script editing options here.
I can also right-click inside the script or its file name in the project window, and from an IRI menu of options, build a flow diagram to visualize the task within a project. From inside the flow diagram, I double-click on the brown task block to open a transform mapping diagram showing the source-to-target field movement I’ve defined, this time left-to-right:
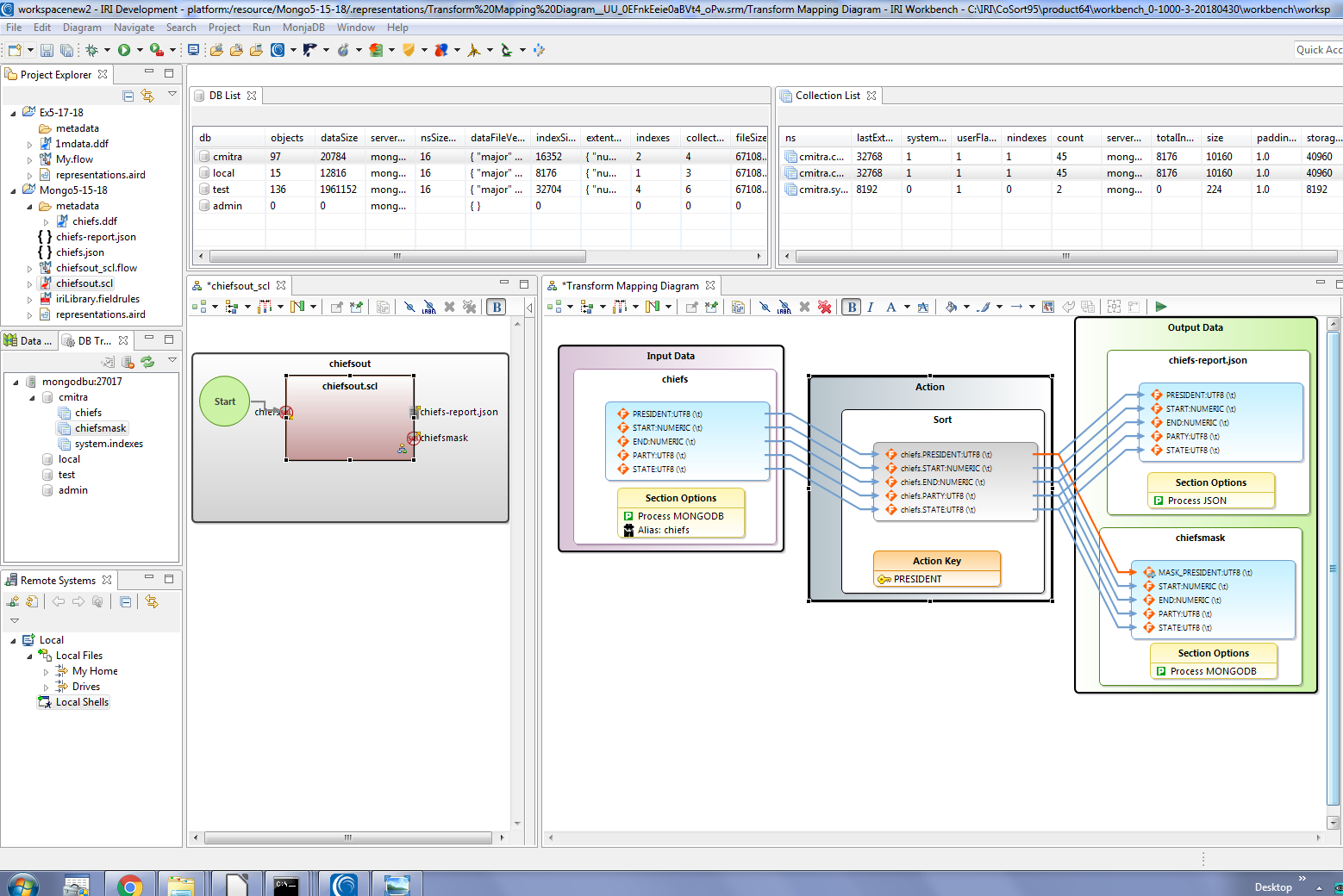
The chiefsout.scl script and chiefsout.flow file are both open, team-shareable metadata assets that share a common data model.
Run the Job
There are also multiple ways to execute the job I built, both from and outside Workbench.
Shown below is the source collection and my same job represented in script and outline form. After running the job, I opened a MonjaDB view to see my masked collection and sorted JSON file:
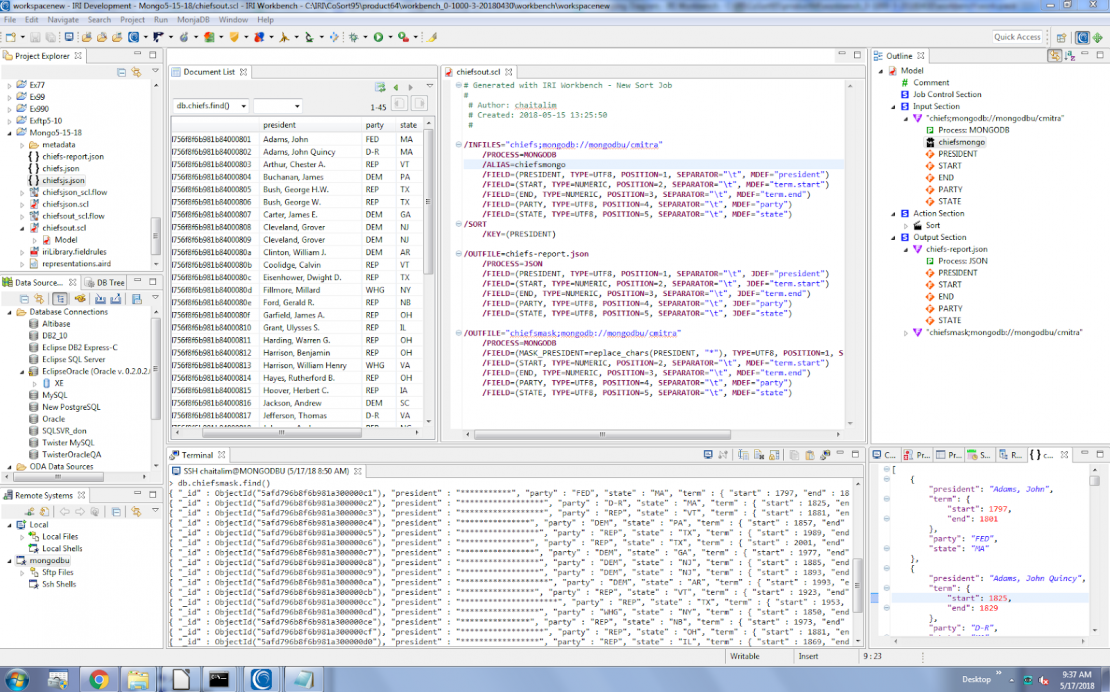
As mentioned, many other permutations of, and faster data management jobs using, MongoDB data are now possible in this environment. Structured data management users in IRI Voracity users can now choose from three connection methods to MongoDB, and leverage many other functional capabilities. IRI DarkShield users can also perform search/mask operations on structured, semi-structured, and unstructured collections in MongoDB and other NoSQL databases.
If you have any questions or need help, contact info@iri.com or find your IRI representative here.










