
Which Data Masking Function Should I Use?
According to Simson L. Garfinkel at the NIST Information Access Division’s Information Technology Laboratory,
De-identification is not a single technique, but a collection of approaches, algorithms, and tools that can be applied to different kinds of data with differing levels of effectiveness. In general, privacy protection improves as more aggressive de-identification techniques are employed, but less utility remains in the resulting dataset.
-De-Identification of Personal Information, NISTIR 8053
Static data masking (SDM) is the industry-recognized term for these various means of de-identifying data elements at rest. The elements are typically database column or flat-file field values that are considered sensitive; in the healthcare industry, they are referred to as key identifiers. Specifically at risk are personally identifiable information (PII), protected health information (PHI), primary account numbers (PAN), trade secrets, or other sensitive values.
The “startpoint” data-centric security product IRI FieldShield — or the IRI CoSort product and IRI Voracity platform that include the same capabilities — provide multiple data discovery and SDM functions for multiple data sources. Available per-field/column masking functions include:
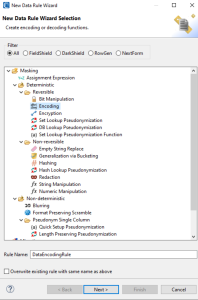
- multiple, NSA Suite B and FIPS-compliant encryption (and decryption) algorithms, including format-preserving encryption
- SHA-1 and SHA-2 hashing
- ASCII de-ID (bit scrambling)
- binary encoding and decoding
- data blurring or bucketing (anonymization)
- random generation or selecction
- redaction (character obfuscation)
- reversible and non-reversible pseudonymization
- custom expression (calculation / shuffle) logic
- conditional / partial value filtering or removal (omission)
- custom value replacement
- byte shifting and string functions
- tokenization (for PCI)
You can also “roll your own” external data masking function. This allows you to call a custom-written, field-level routine at runtime instead of a built-in.
The question remains, which masking function should I use (on each item)? That depends on your business needs and rules, as well as applicable data privacy law(s). At a technical level, that usually means deciding how the resulting ciphertext (masked data) needs to appear, if it needs to be reversible or unique, how secure it is, and possibly, what kind of compute resources and time are available for the process. Let’s look at these common decision criteria in detail:
Appearance (Realism)

Should the newly masked data look more or less like the original data? What about its size and format? Pseudonymization and format-preserving encryption are the two most common ways to
retain the look and feel of proper nouns and alpha-digit account or phone numbers, respectively. But substring masking (a/k/a partial field redaction, e.g., XXX-XX-1234) may be just fine for things like SSNs. Think about the persistence and display of the data for analytics, etc.
Related to this, appearance and realism of the ciphertext can also determine the usability of the results. Application and database table (load utility) targets may require that the format of the data not only comply with pre-defined structures, but continue working in queries or other operational contexts downstream.
In other words, if masked data that’s pretty and/or functional data is required, don’t go for full redaction, randomization, hashing, or straight encryption (which widens and obfuscates the results). You may be able to get away with smaller tweaks like ageing and sub-string manipulation, but consider the impact of these choices on your other decision criteria …
Reversibility (Re-Identification)
 Need the original data restored? The answer to that may depend on whether you’re leaving the source data alone, as you would in dynamic data masking, or when you’re writing the masked data out to new targets. In those cases, the answer is no.
Need the original data restored? The answer to that may depend on whether you’re leaving the source data alone, as you would in dynamic data masking, or when you’re writing the masked data out to new targets. In those cases, the answer is no.
If the answer is no, you may still need realism, in which cases non-reversible pseudonymization may be your best bet. If it’s no and appearance doesn’t matter, go with character redaction. And if neither is true, consider outright deletion of the source column from the target.
When the answer is yes, IRI data masking functions like encryption, reversible pseudonymization or tokenization, encoding, or ASCII re-ID (bit scrambling) are indicated. In more advanced use cases, you may also need differential reversal; i.e., when different recipients of the same target are authorized to see different things in the same data set. In such cases, private encryption keys, user-specific revelation job scripts, or even custom applications can be deployed.
Uniqueness (Consistency)

Does the same original value always need to be replaced by the same, but different, replacement value? Is the data going to be joined on, or grouped by, the replacement values? If so, then the replacement algorithm chosen must produce results which are unique and repeatable in order to preserve referential integrity despite the masking that’s occurred. This is also known as deterministic data masking.
This can be achieved through encryption when the same algorithm and passphrase (key) are used against the same plaintext. The data classification and cross-table protection wizards in the IRI Workbench IDE for FieldShield, Voracity, etc. facilitate this through cross-table (or more global) application of the matched masking rule. In this way, the same plaintext value always gets the same ciphertext result regardless of its location.
 Pseudonymization is trickier here, however, because of a shortage of unique replacement names, duplicate original names, and changes (inserts, updates, or deletes) to the original values in source tables or files. IRI addressed the issue of consistent cross-table pseudonymisation in this Voracity workflow example.
Pseudonymization is trickier here, however, because of a shortage of unique replacement names, duplicate original names, and changes (inserts, updates, or deletes) to the original values in source tables or files. IRI addressed the issue of consistent cross-table pseudonymisation in this Voracity workflow example.
Strength (Security)
A look at the algorithms inside each function can help you determine their relative “crackability”, and assess that against the other ciphertext considerations like appearance and speed. For example, IRI’s AES256 function is stronger than the AES128 option, SHA2 is stronger than SHA1, and all are stronger than base64 encode/decode and ASCII de-ID/re-ID functions.
By definition, reversible functions are typically weaker than those that cannot be reversed. For example, IRI’s irreversible (foreign lookup set) pseudonymization method is more secure than its reversible (scrambled original set) pseudonymization method. That said, the AES-256 encryption algorithm can be very hard to crack when the key has been lost, too.
 Even stronger security is of course omission, followed by character obfuscation (redaction), which are irreversible. But the downside is lack of usability. In the HIPAA safe harbour context, the removal of key identifiers complies. If you need to use any part of the source data for analysis, research, marketing, or demonstration, however, you will need a masking function instead, and an expert to determine (and certify) that your technique(s) carry a low statistical likelihood of re-identification.
Even stronger security is of course omission, followed by character obfuscation (redaction), which are irreversible. But the downside is lack of usability. In the HIPAA safe harbour context, the removal of key identifiers complies. If you need to use any part of the source data for analysis, research, marketing, or demonstration, however, you will need a masking function instead, and an expert to determine (and certify) that your technique(s) carry a low statistical likelihood of re-identification.
While we’re on the subject of HIPAA de-identification, remember there may also be risk associated with so-called quasi identifiers (like zip code and age). Those values can be used in conjunction with other data sets to establish a re-identification trail, and are thus also worth masking in many cases; the whether and how are subject to these same considerations.
Computation (Performance)
One of the nice things about the data masking approach — even when compute-intensive encryption algorithms are involved — is that its overhead relative to broad-brush encryption (of an entire network, database, file/system, disk drive) is far lower. Only those data elements (column values) that you designate for protection need to be ingested into, processed by, and returned from, the masking function.
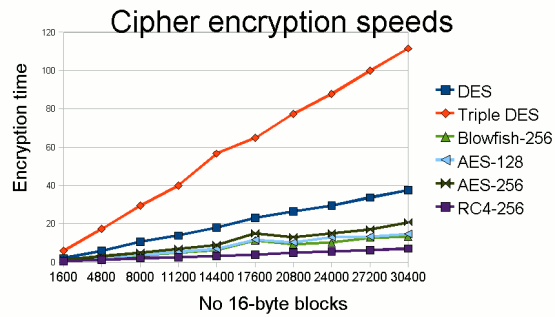 In general, the more complex (and stronger) the algorithm, the longer it will take to apply. Data masking speeds will also depend on the number of functions applied, the number of DB columns and rows, the number of lookup constraints to respect in the process (for referential integrity), network bandwidth, RAM, I/O, concurrent processes, and so on.
In general, the more complex (and stronger) the algorithm, the longer it will take to apply. Data masking speeds will also depend on the number of functions applied, the number of DB columns and rows, the number of lookup constraints to respect in the process (for referential integrity), network bandwidth, RAM, I/O, concurrent processes, and so on.
The following non-scientific chart breaks down most of the attributes described above for convenient reference, for some (but not all!) supported IRI data masking functional categories, and in generally relative terms only. Needless to say, IRI disclaims any warranty of fitness or liability for this chart!
Selected Data Masking Functions (FieldShield & DarkShield)
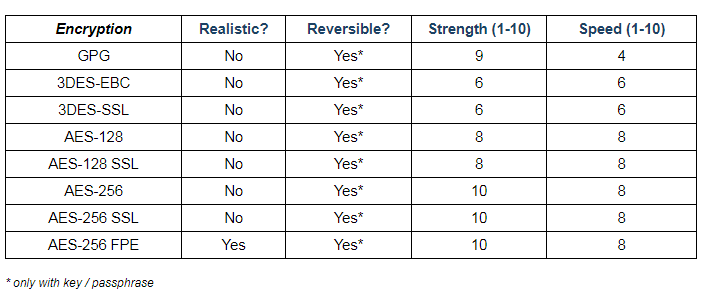
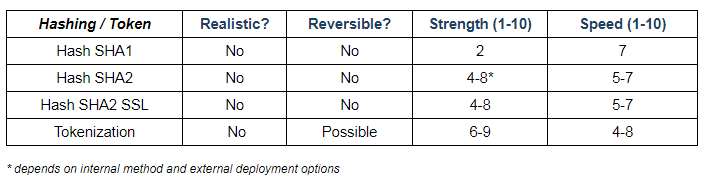




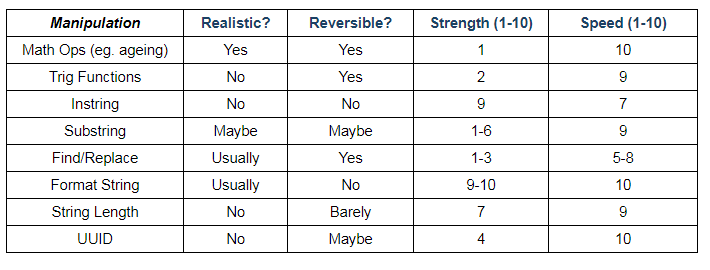
Whether you use built-in IRI data masking functions, or custom functions that you define, the idea is to apply them based on your business rules to specific rows or columns and/or across tables. And you will do it through data masking rules you can define, store, and re-use. It is also possible (and preferable) to apply these data masking functions against auto-classified data as rules for convenience and consistency. And you can leverage several of them in dynamic data masking applications via an API call.
FieldShield (or Voracity) users can create, run, and manage your data masking jobs in a free state-of-the-art GUI, built on Eclipse.™ Or, they can edit and run compatible, self-documenting 4GL scripts defining their source/target data and masking functions, and run those scripts on the command line.
For more information, see https://www.iri.com/solutions/data-masking or contact your IRI representative.










