
Introduction to IRI DarkShield
What is DarkShield?
IRI DarkShield is a data masking tool for classifying, searching, and de-identifying Personally Identifiable Information (PII) and other sensitive data in structured, semi-structured and unstructured sources. You can define and run DarkShield jobs via a GUI, CLI or API.
DarkShield supports data on-premise or in the cloud. Sources include free-floating text , files and documents , various NoSQL DBs , and any relational database connected through a JDBC driver.
One of several data masking tools in the IRI Voracity platform and IRI Data Protector Suite , DarkShield supports most data formats and silos.1
The data classes and masking functions you define for DarkShield jobs are the same ones used in IRI FieldShield and IRI CellShield EE. This allows you to secure data consistently across disparate silos and formats.
How Does It Work?
Most DarkShield jobs can be configured, run, and shared through the IRI Workbench GUI, built on Eclipse. See this section for more information on the front end:
https://www.iri.com/products/workbench/darkshield-gui
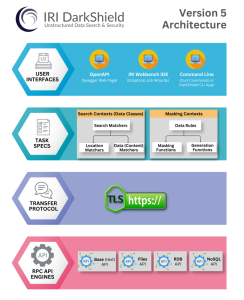
Under the hood, DarkShield runs one or more Remote Procedure Call (RPC) API engines – depending on your data source(s) – that perform the searching and masking work. These engines run through a server in your infrastructure (called Plankton Server) which accepts HTTP(S) requests containing your PII searching and masking instructions.
You host the DarkShield API server either on-premise or in a cloud server you manage. IRI does not maintain or manage these services, and at no time would PII leave your environment.
The methods DarkShield uses to search for PII are provided in instructional JSON payloads to the applicable DarkShield API as Search Contexts. These are instructions for masking PII found during a search or contained in instructions called Mask Contexts.
Inside IRI Workbench, Search Contexts are derived from Data Classes that contain Data Matchers and Location Matchers. Mask Contexts, in turn, are created from Masking Rules that are paired to Data Classes. Again, the consistent application of deterministic data masking function rules will preserve data or referential integrity across all your target silos.
Provided alongside the search and mask contexts are some additional contexts that provide instructions on where to read data from (FileSearchContext, NoSqlSearchContext, RdbSearchContext) and where to write masked data to (FileMaskContext, NoSqlMaskContext, RdbMaskContext).
By pairing search methods with masking functions you get more granular control for masking. For example, you can configure a DarkShield job to redact any credit card numbers that are found, but use a (consistent) pseudonym replacement for names wherever those are found.
Getting Started
You can license DarkShield as a standalone product, or in a bundle with IRI FieldShield or IRI CellShield EE in the IRI Voracity data management platform. Licensing and pricing options are on this page.
IRI will send you download and installation instructions under your evaluation or licensing agreement. At installation time, you will need to register a provided version of the IRI CoSort engine, sortcl, to enable masking jobs. 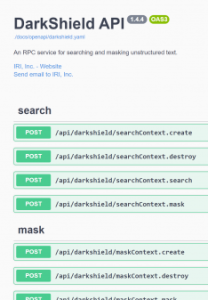
The DarkShield API is run on a web server called Plankton, listening for requests. These HTTP(S) payloads can contain either instructions on how to find PII and mask it in the form of Search Contexts and Mask Contexts, or instructions on where to access and read data from and where to write the masked result.
DarkShield can be installed either as the backend engine (API) only, or with an installation of the IRI Workbench (GUI). To run any jobs, you must first start your DarkShield server 2 via the:
- shell or batch startup script in the DarkShield API distribution bin directory;
- Workbench Window > Preferences > IRI > DarkShield properties dialog; or,
- DarkShield API Status view in your workspace.
Connecting to Different Sources
Whether calling them directly or using them from Workbench, DarkShield uses different API plugins to access and manipulate different source types, including (streaming) text (strings), standalone or embedded files/documents/images, NoSQL databases, and relational databases.
For file sources, DarkShield supports several different formats, including:
- .doc, .docx, .xls, xlsx, .ppt
- .csv, .tsv, fixed-length
- JSON and XML
- DICOM, JPG, PNG GIF, TIF
- Parquet
- HL7v2 and X12
DarkShield can reach files stored on the local machine or LAN, and from IRI Workbench, DarkShield can also reach files stored in cloud sources such as Azure Blob Storage, Google Cloud Storage, S3 Buckets, OneDrive, and SharePoint Online.
Read the articles on the DarkShield-Files plug-in (RPC API for files) or the New File Search/Masking Job … wizard in IRI Workbench. You will learn how to find and mask the PII within many different file formats and silos all at once.
For NoSQL databases, the DarkShield NoSQL wizard currently supports these sources:
- Cassandra
- Elasticsearch
- MongoDB
Read the blog article on the NoSQL plugin or the NoSQL wizard for DarkShield to learn more about setting up connections to those sources. It is also possible to use the DarkShield API with glue code to search and mask PII in at least 7 more NoSQL DBs; find the sample projects here.
For relational database sources, DarkShield will support any instance that can be accessed via a JDBC connection.3 See the JDBC sections of these articles for DB-specific connection advice, and the DarkShield RDB plugin or RDB wizard article to learn about working with RDB sources.
Classifying PII
Data classification refers to the act of defining and labeling specific types of data – like email addresses, ID numbers, and last names – into unique, abstract categories of data called Data Classes (or Data Class Groups), based on certain location attributes or data/content traits.
DarkShield requires that you classify data in IRI Workbench (usually just once) so that the data you’re looking for can be found and masked. The Data Classification process begins when you create a project and elect to configure a Data Class and Rule Library (.dcrlib file).
This library is where the Data Classes you define – and the search methods and masking functions you assign to them – are held for (possibly shared) use in search and masking jobs.
To learn more about the Data Classification process, please refer to this article.
Applying Masking Functions
DarkShield applies masking functions through rules. Rules are created and stored for future use and modification in the Data Class and Rule Library, which resides in an IRI Project folder.
Rules can be paired to Data Classes when defining a DarkShield job in any of the DarkShield masking wizards. Masking Rules can support masking PII using various techniques such as:
- NSA Suite B and FIPS-compliant encryption and decryption algorithms, including format-preserving encryption
- MD5, SHA-1 and SHA-2 hashing
- Deletion/removal
- Full or partial string editing
- Pseudonymization
Auditing jobs
After running a search-only, search and mask, or mask-only job, DarkShield produces a number of artifacts for use in PII discovery, compliance auditing, and operational monitoring. Search and masking logs are produced in machine-readable delimited 4 and JSON formats suitable for reporting or exporting to analytic tools like Excel , Datadog , Splunk ES , and Phantom playbooks.
DarkShield also produces interactive, aggregate dashboard charts to visualize and take action on without the use of a SIEM tool, like this “heat map”:
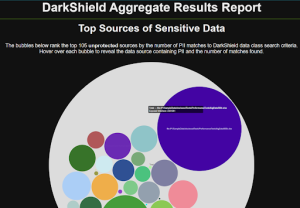
See this article for details on the HTML5 charts you can customize from IRI Workbench.
Advanced Topics
Here are some additional articles related to DarkShield:
- Video: PDF configuration options
- Named Entity Recognition (NER)
- DarkShield Wizards
- DarkShield RPC API calls
In general, you can find resources like these at: https://www.iri.com/services/training/courseware#iri-darkshield
If you have any questions about IRI DarkShield or other IRI data masking tools or are interested in a demonstration or free trial, please email info@iri.com .
- Consider your use case. IRI FieldShield or RowGen may be a better fit for your relational database test data requirements. IRI CellShield EE may be easier for your Excel users to operate. See the tool comparison matrix.
- If you are running DarkShield from Workbench, open the DarkShield API configuration dialog in preferences and paste the local or remote folder location of the DarkShield API distribution (e.g., C:\IRI\DarkShield\API\plankton-1.5.1). Click the Start Server button, and then Apply (and Close). You should see startup messages for the API server in the Workbench console window confirming the DarkShield API is configured correctly for use and management in Workbench.
- The JDBC driver(s) must be located in the API distribution /lib subfolder, which happens automatically when running a DarkShield job.
- The delimited log file is for file-related search results only. JSON logs cover all sources plus masking.










