Improving Talend Performance
Talend has been on the market for several years now, and its flexible UI components make it a very reasonable choice for developers when it comes to customization. Talend Studio is built in Java, which gives it a certain degree of control and flexibility in managing its performance. That said, however, I found that Talend has two general limitations in processing large data sets:
- It requires too much RAM for data processing, especially sort, join, or aggregation. Talend will always try to do them in memory, and must have that memory pre-allocated to run the operation. For example, just to perform a lookup in a 2GB file, you must first allocate 2 GB as HEAP memory.
- The performance, even after allocating enough RAM, would be dependent on the hardware resources and the configuration options used (e.g., in T-Map check mark “Stored on Disk” or bulk loading, etc.)
IRI CoSort continues to perform or accelerate high-volume data manipulations in DB, BI, and ETL environments. CoSort is also the default engine in the IRI Voracity data management platform, which, like Talend, is built on Eclipse™, and now overlaps in many areas, including ETL.
Like other independent DW consultants have with DataStage, Informatica, and Pentaho, I performed multiple benchmarks on large data sets in Talend natively, with CoSort (Voracity) alone, and from a Talend workflow calling CoSort. The head-to-head comparisons speak for themselves, while the embedded use of CoSort overcame Talend’s inherent processing limitations and need for additional hardware.
Configuration
Following are the hardware and software specifications used for this POC:
Hardware
- HP Proliant DL360-G7
- Intel® Xeon® CPU X5650 @ 2.67GHz 12MB cache, 24 cores (4 CPUs x 6 cores)
- 72GB (18 x 4GB single rank RDIMM)
- Virtual Machine constrained to 8 cores (2 CPUs x 4 cores) and 32GB RAM
Software
- Talend Open studio 6
- IRI Voracity® 1.0, which includes CoSort® 9.5.3
- IRI Workbench, a free GUI option, built on Eclipse
The scenario took two file sources (Customer and Transactions) of various sizes and sorted, joined, aggregated, and filtered them. In CoSort, that’s all expressed in one transform block, job script, and I/O pass. Talend requires the files be joined in memory, and then split using a filter transformation into two data streams that are later sorted and aggregated. In both cases, two target files are written to the disk with filtered and formatted results.
The source data was created automatically by IRI RowGen. RowGen is sold as a standalone test data generation package for EDW DB and file targets, and is a spin-off of the CoSort SortCL program. RowGen also uses the same Eclipse GUI (IRI Workbench) and metadata as all IRI software, and its use is supported in a Voracity platform subscription.
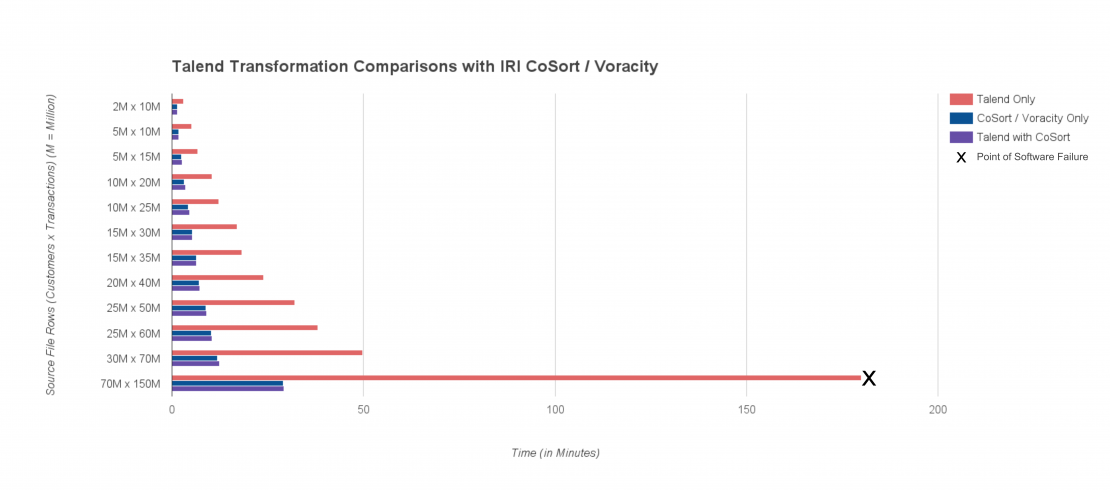
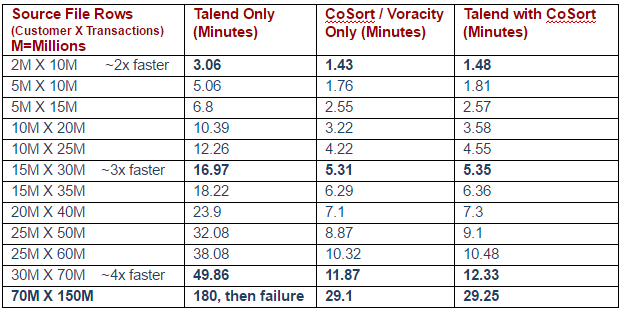
Following are the relative benchmarks:
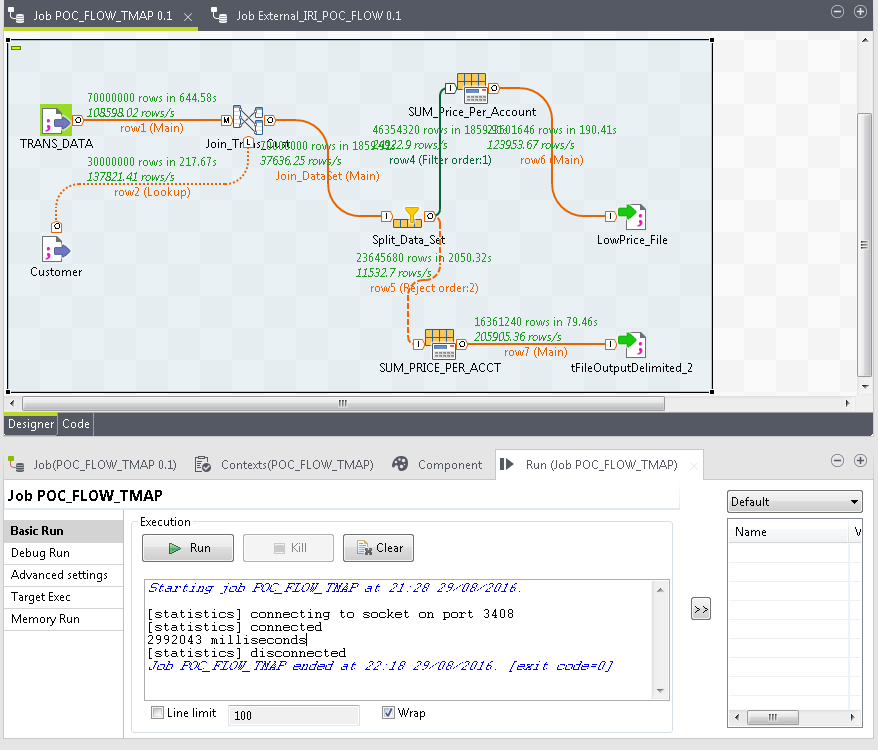
Talend Workflow (Native)
Below is the Talend job design required to first join the same two sequential files, filter them on a condition and, later, sort and aggregate. Then final results are written to two separate sequential files.
We Enabled the Run → Advanced settings → JVM settings to specify 16GB as the maximum memory for Talend to process the large data set under consideration. In the TMap transformation, we enabled the “Store on Disk “option to speed up the join process.
Things ran fine until the data sizes exceeded memory. I turned to CoSort to speed things up at all file sizes (from 2-4X) until Talend failed, and CoSort kept going.
CoSort Process (Voracity Workflow)
The IRI CoSort product — and its SortCL data definition and manipulation 4GL program doing the transforms — is shown above in the IRI Workbench’s syntax-aware editor.
SortCL is fast primarily because it combines the transforms (and other functionality) in the same job script and I/O pass. It also uses the CoSort engine in the file system, which takes advantage of multi-threading, task consolidation, modern memory management, and proven I/O optimization techniques. And, it is not a Java program that must be compiled at every runtime.
SortCL jobs can be hand-written, generated via job wizard, or built in the ETL workflow palette (with an IRI Voracity subscription). The scripts are easy-to-read text files you can run (ad hoc or scheduled) in the GUI or on any Windows, Unix, or Linux command line. That is how I was able to call it so easily into my Talend Workflow.
In the Hadoop version of Voracity, these same jobs can run in MapReduce 2, Spark, Storm, or Tez without code modification. It also supports HDFS file browsing, editing and transfer, and certification is underway for Cloudera, HortonWorks, and MapR distributions. IRI recommends running these jobs when speed and scalability demand it, usually with data sets above 5TB.
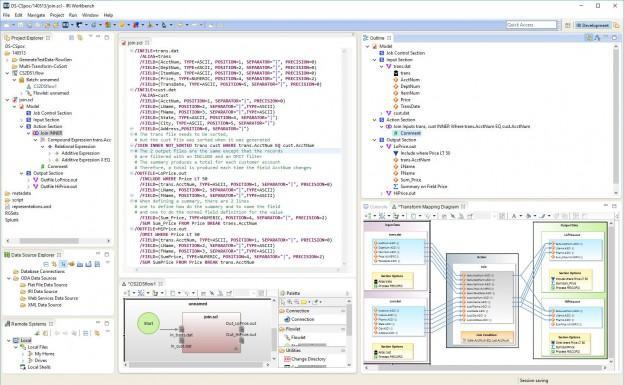
The CoSort ‘SortCL’ script is shown above, with an outline, in the IRI Workbench (Eclipse) GUI. The IRI Voracity ETL workflow and transform mapping diagrams of the same job are below those. All the metadata is: 1) re-entrant regardless of work-style, 2) manageable in EGit and other repositories, and 3) compatible with Erwin (formerly AnalytiX DS) Mapping Manager CATfx templates for spreadsheet-style mapping definition, stratification, and automatic conversion from Talend and other ETL tools to Voracity.
Talend Workflow (with CoSort)
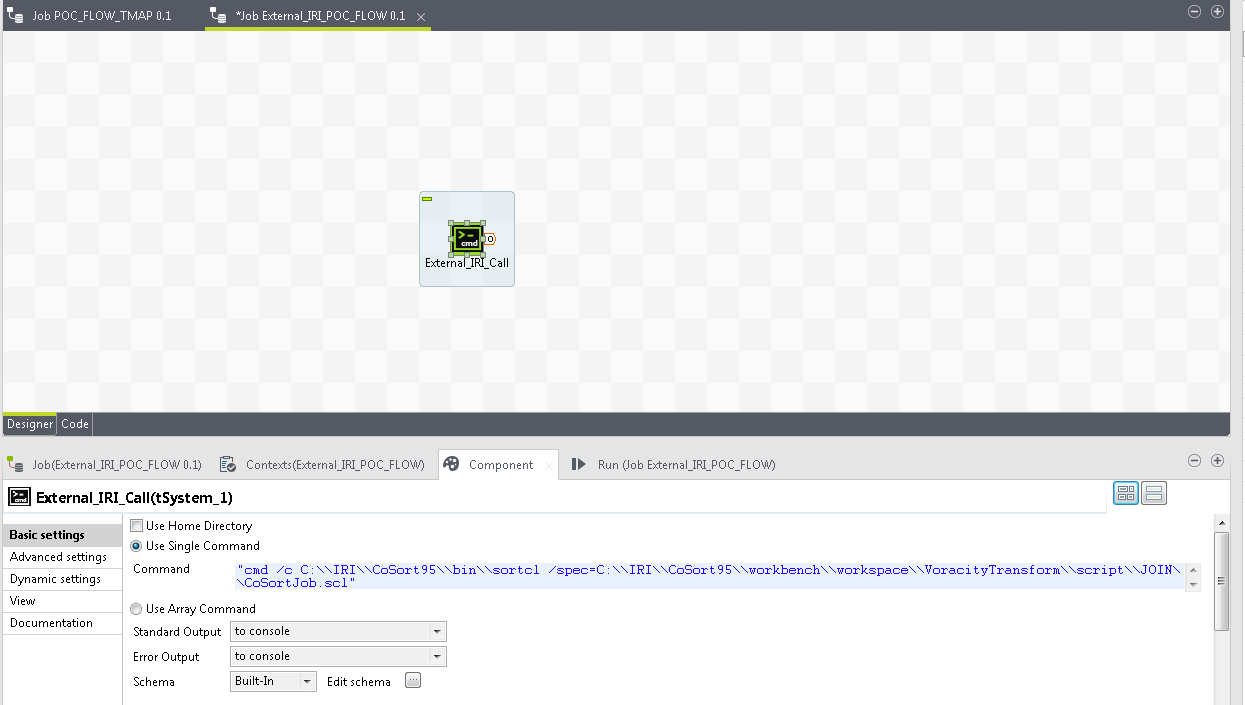
To combine the processes for the benefit of my Talend operation, I wrote a simple call to my CoSort SortCL script using the tSystem transformation. This “pushes out” all of the big data transformation overhead to CoSort with a simple command line call:
sortcl /spec=CoSortJob.scl
This performs all the same transformations against the same inputs with the same results, but at the faster times shown in the chart.
CoSort also provides some options to enhance its own performance similar to Talend; e.g., setting a memory limit. RAM use, along with thread, overflow file, and other I/O options, are set in resource controls for use at the job, user, or global level. In IRI Workbench, I just click on:
Run -> Resource Control Analysis -> Run Setup -> Tune CoSort
This opened a dialog box with options to edit and set new values in effect in the workspace. I moved MEMORY_MAX down to 16GB to match what Talend could use, and left the remaining values at their default settings. It’s worth noting that CoSort’s tuning values are ceilings, not floors, so the product can run as a “good neighbor” on multi-user systems.
From the graphic version of the benchmarks above, it is easy to see the value CoSort adds to Talend in data transformations. CoSort more efficiently performs multiple, complex data transformations in big data use cases without adding memory, server hardware, or Hadoop:

If you would like more information or have any comments suggestions, please provide feedback in the form below, or contact cosort@iri.com. Look for a subsequent article comparing the relative ETL ergonomics of IRI Voracity (powered by CoSort) and Talend.

This third-party POC comparison was demonstrated by Tahir Aziz of BigData Dimension Inc.